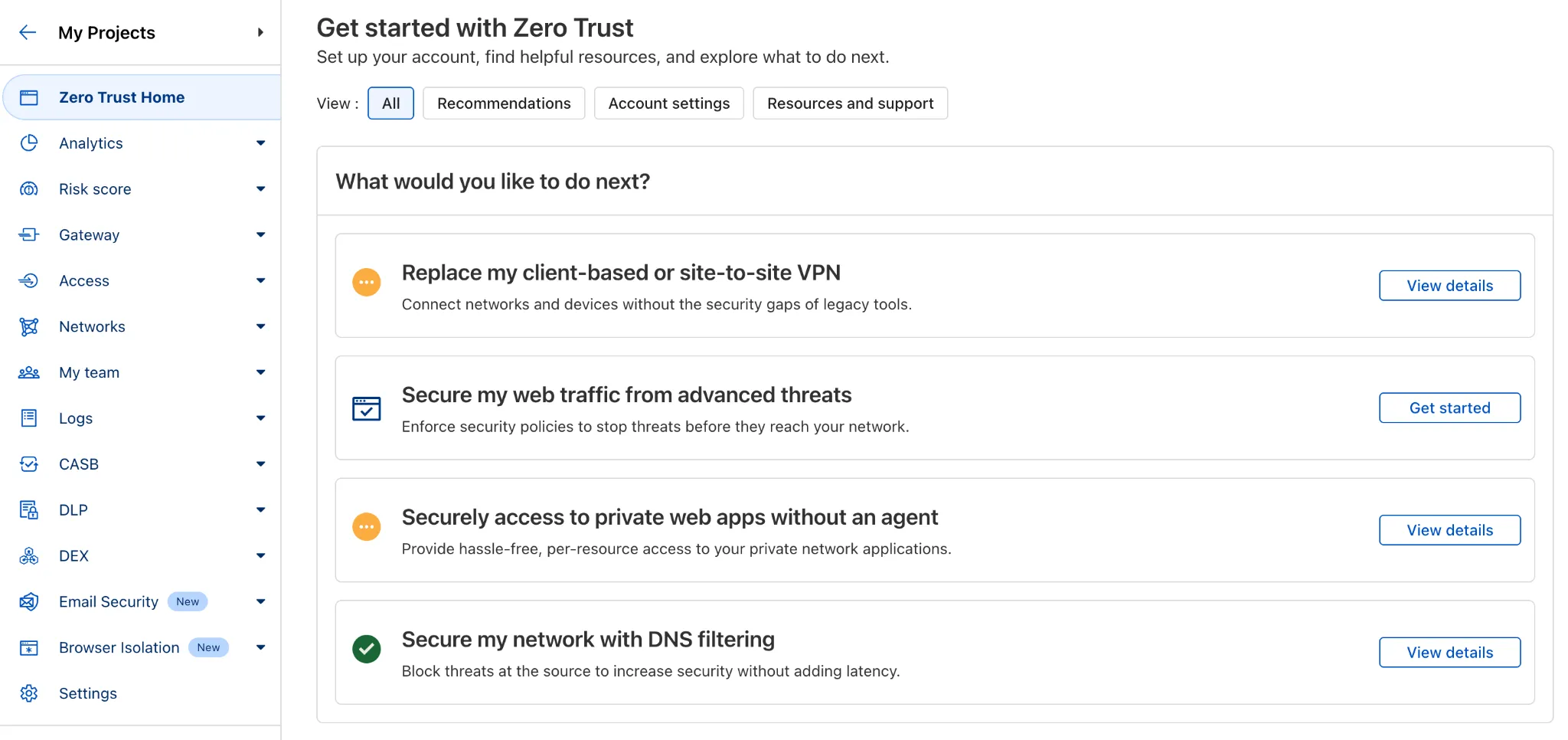
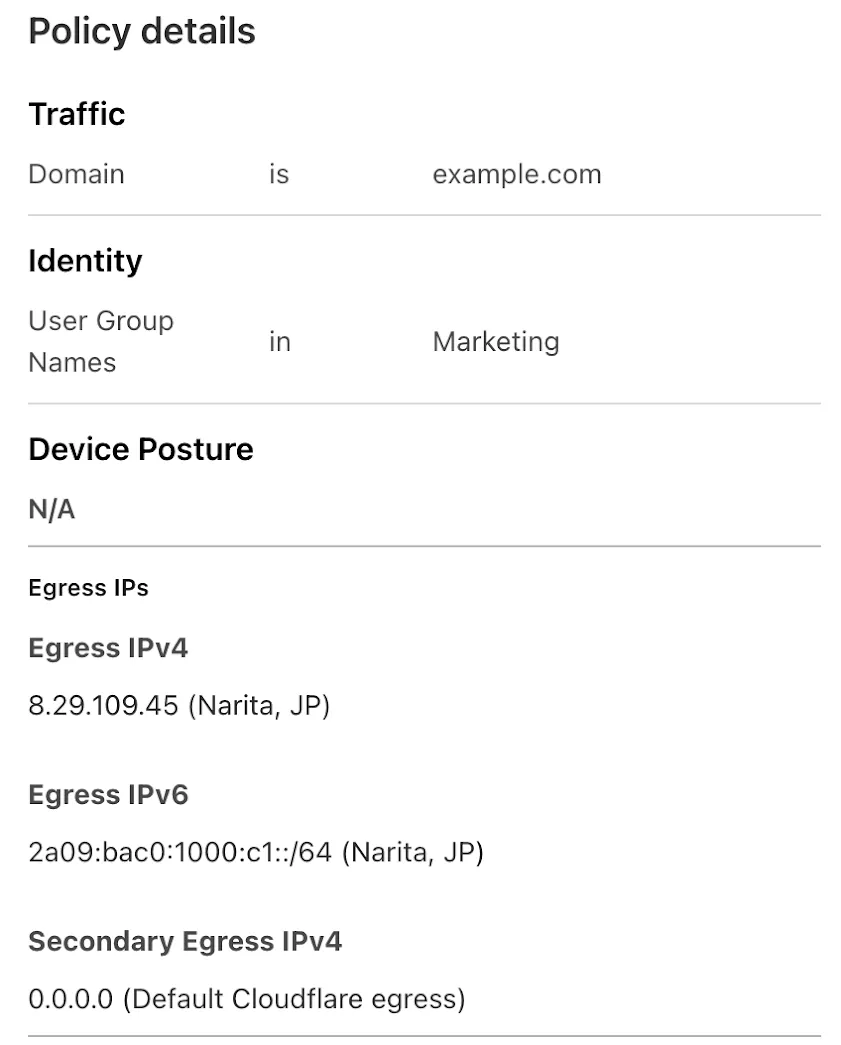
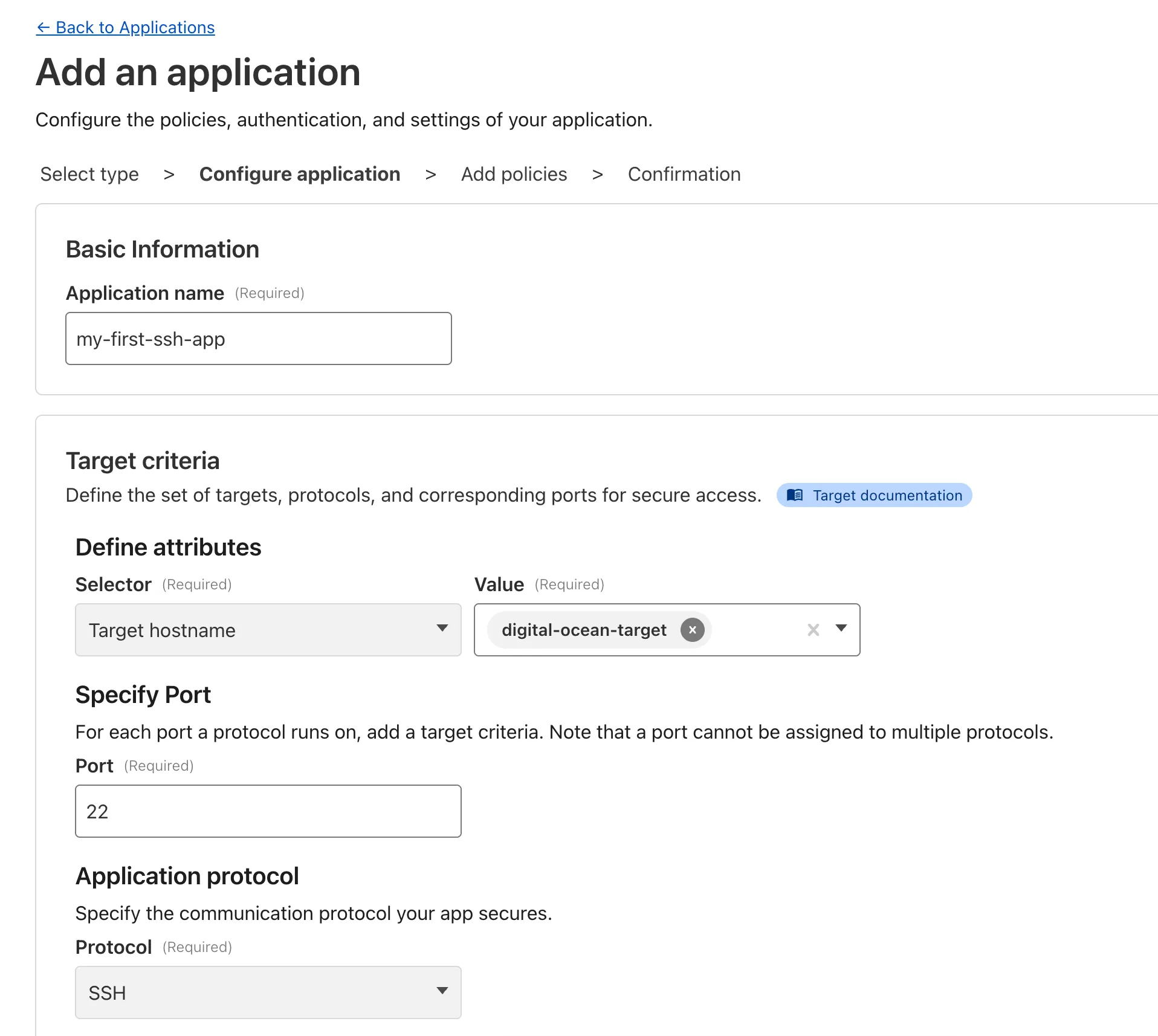
Use our brand new onboarding experience for Cloudflare Zero Trust. New and returning users can now engage with a Get Started tab with walkthroughs for setting up common use cases end-to-end.
There are eight brand new onboarding guides in total:
Securely access a private network (sets up device client and Tunnel)
Device-to-device / mesh networking (sets up and connects multiple device clients)
Network to network connectivity (sets up and connects multiple WARP Connectors, makes reference to Magic WAN availability for Enterprise)
Secure web traffic (sets up device client, Gateway, pre-reqs, and initial policies)
Secure DNS for networks (sets up a new DNS location and Gateway policies)
Clientless web access (sets up Access to a web app, Tunnel, and public hostname)
Clientless SSH access (all the same + the web SSH experience)
Clientless RDP access (all the same + RDP-in-browser)
Each flow walks the user through the steps to configure the essential elements, and provides a “more details” panel with additional contextual information about what the user will accomplish at the end, along with why the steps they take are important.
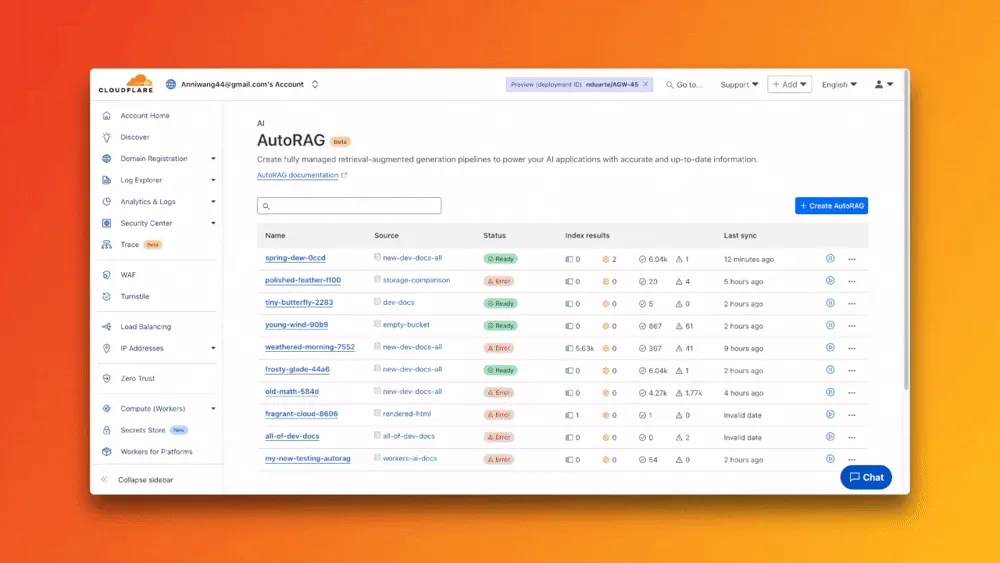
You can now expect 3-5× faster indexing in AutoRAG, and with it, a brand new Jobs view to help you monitor indexing progress.
With each AutoRAG, indexing jobs are automatically triggered to sync your data source (i.e. R2 bucket) with your Vectorize index, ensuring new or updated files are reflected in your query results. You can also trigger jobs manually via the Sync API or by clicking “Sync index” in the dashboard.
With the new jobs observability, you can now:
View the status, job ID, source, start time, duration and last sync time for each indexing job
Inspect real-time logs of job events (e.g. Starting indexing data source...)
See a history of past indexing jobs under the Jobs tab of your AutoRAG
This makes it easier to understand what’s happening behind the scenes.
Coming soon: We’re adding APIs to programmatically check indexing status, making it even easier to integrate AutoRAG into your workflows.
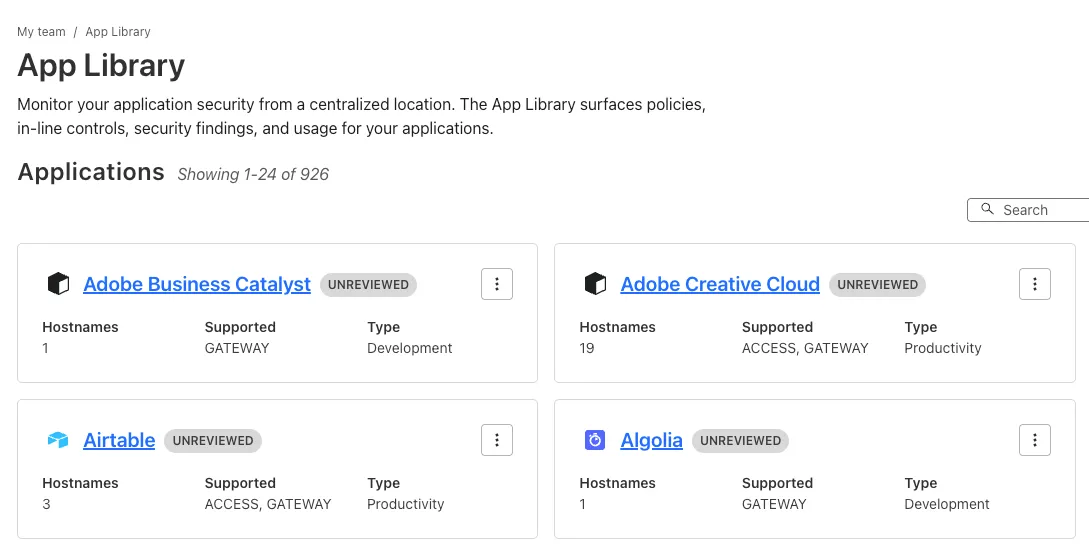
Cloudflare Zero Trust customers can use the App Library to get full visibility over the SaaS applications that they use in their Gateway policies, CASB integrations, and Access for SaaS applications.
App Library, found under My Team, makes information available about all Applications that can be used across the Zero Trust product suite.
You can use the App Library to see:
How Applications are defined
Where they are referenced in policies
Whether they have Access for SaaS configured
Review their CASB findings and integration status.
Within individual Applications, you can also track their usage across your organization, and better understand user behavior.
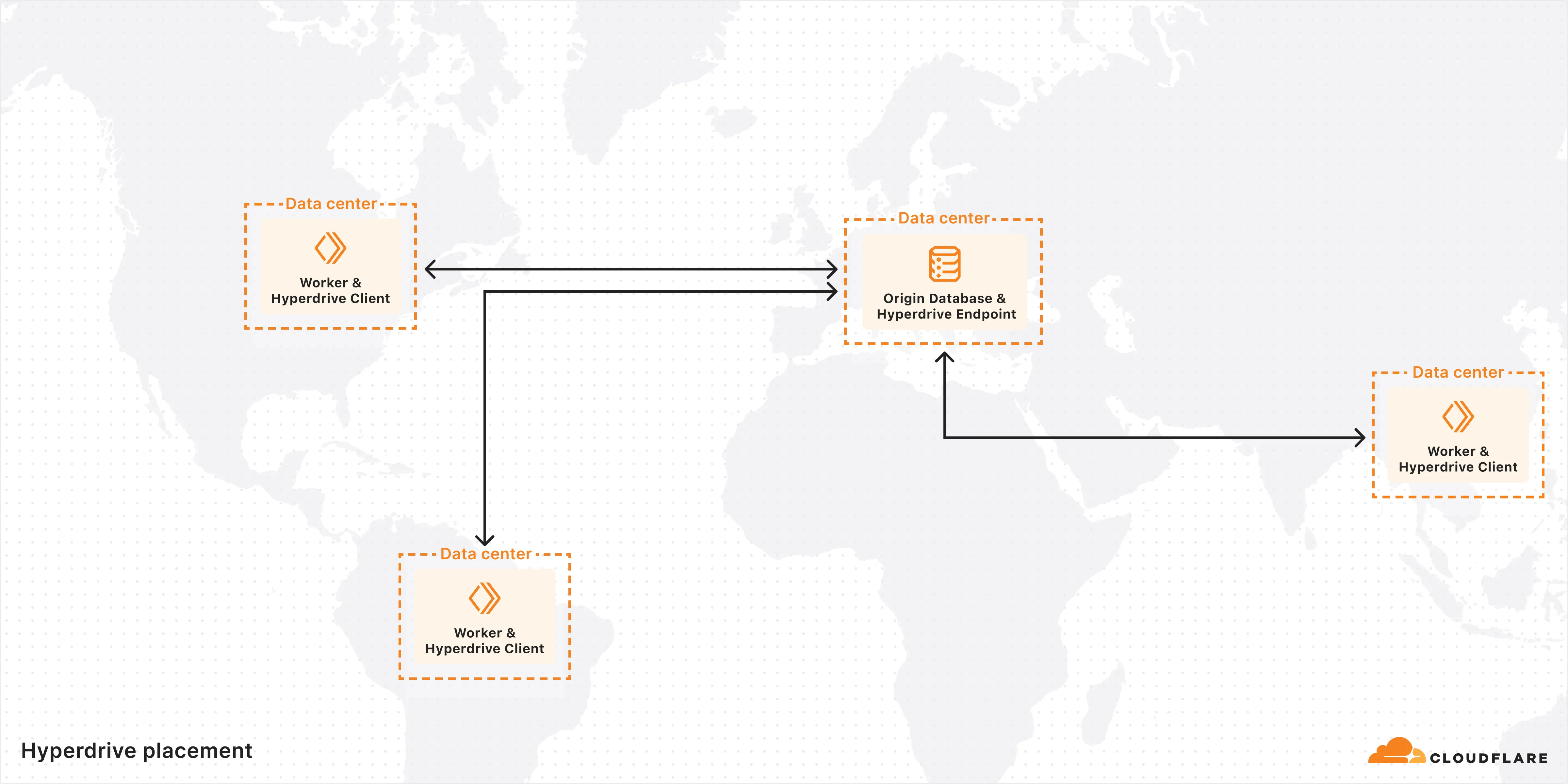
You can now specify the number of connections your Hyperdrive configuration uses to connect to your origin database.
All configurations have a minimum of 5 connections. The maximum connection count for a Hyperdrive configuration depends on the Hyperdrive limits of your Workers plan.
This feature allows you to right-size your connection pool based on your database capacity and application requirements. You can configure connection counts through the Cloudflare dashboard or API.
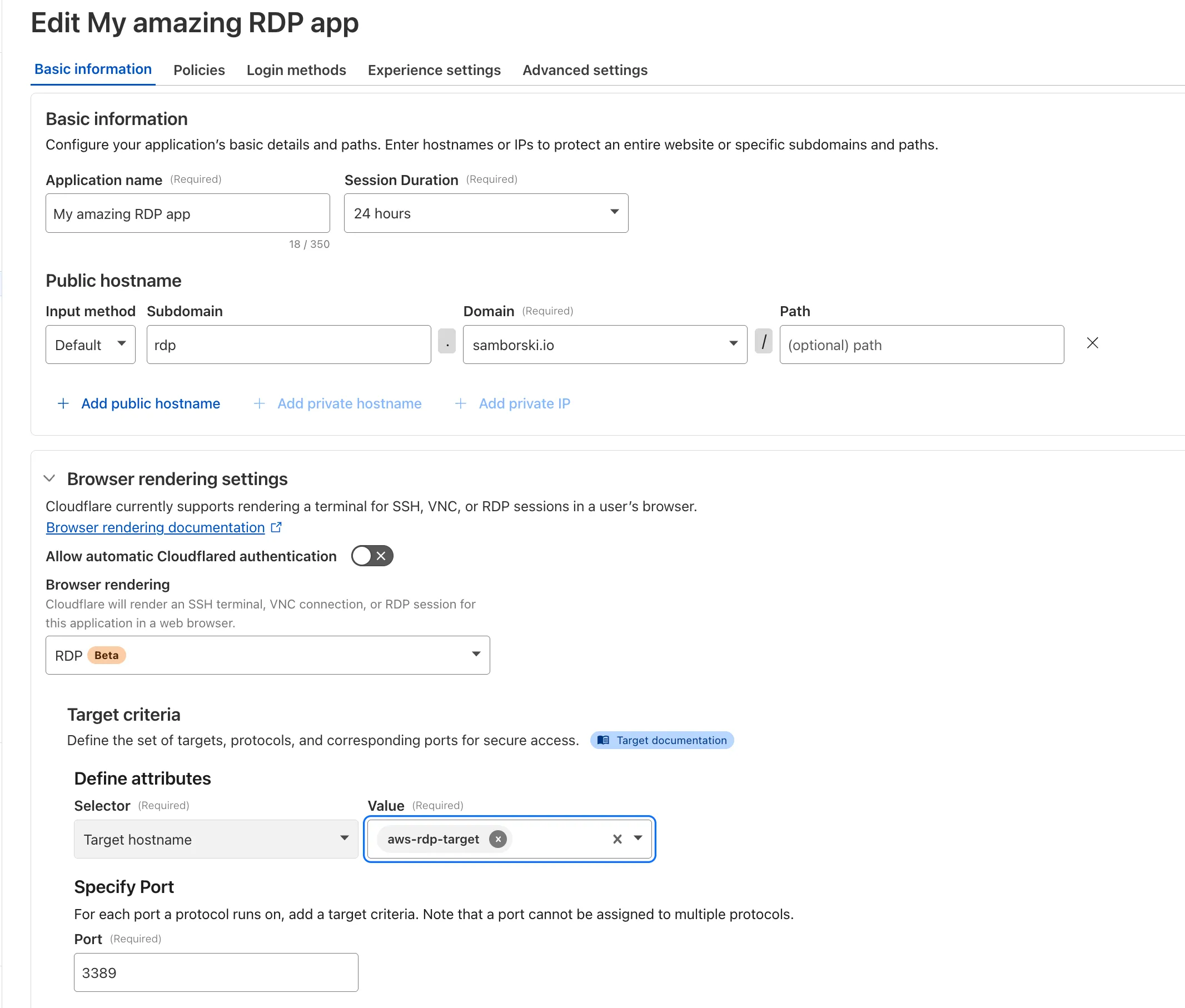
Browser-based RDP with Cloudflare Access is now available in open beta for all Cloudflare customers. It enables secure, remote Windows server access without VPNs or RDP clients.
With browser-based RDP, you can:
Control how users authenticate to internal RDP resources with single sign-on (SSO), multi-factor authentication (MFA), and granular access policies.
Record who is accessing which servers and when to support regulatory compliance requirements and to gain greater visibility in the event of a security event.
Eliminate the need to install and manage software on user devices. You will only need a web browser.
Reduce your attack surface by keeping your RDP servers off the public Internet and protecting them from common threats like credential stuffing or brute-force attacks.
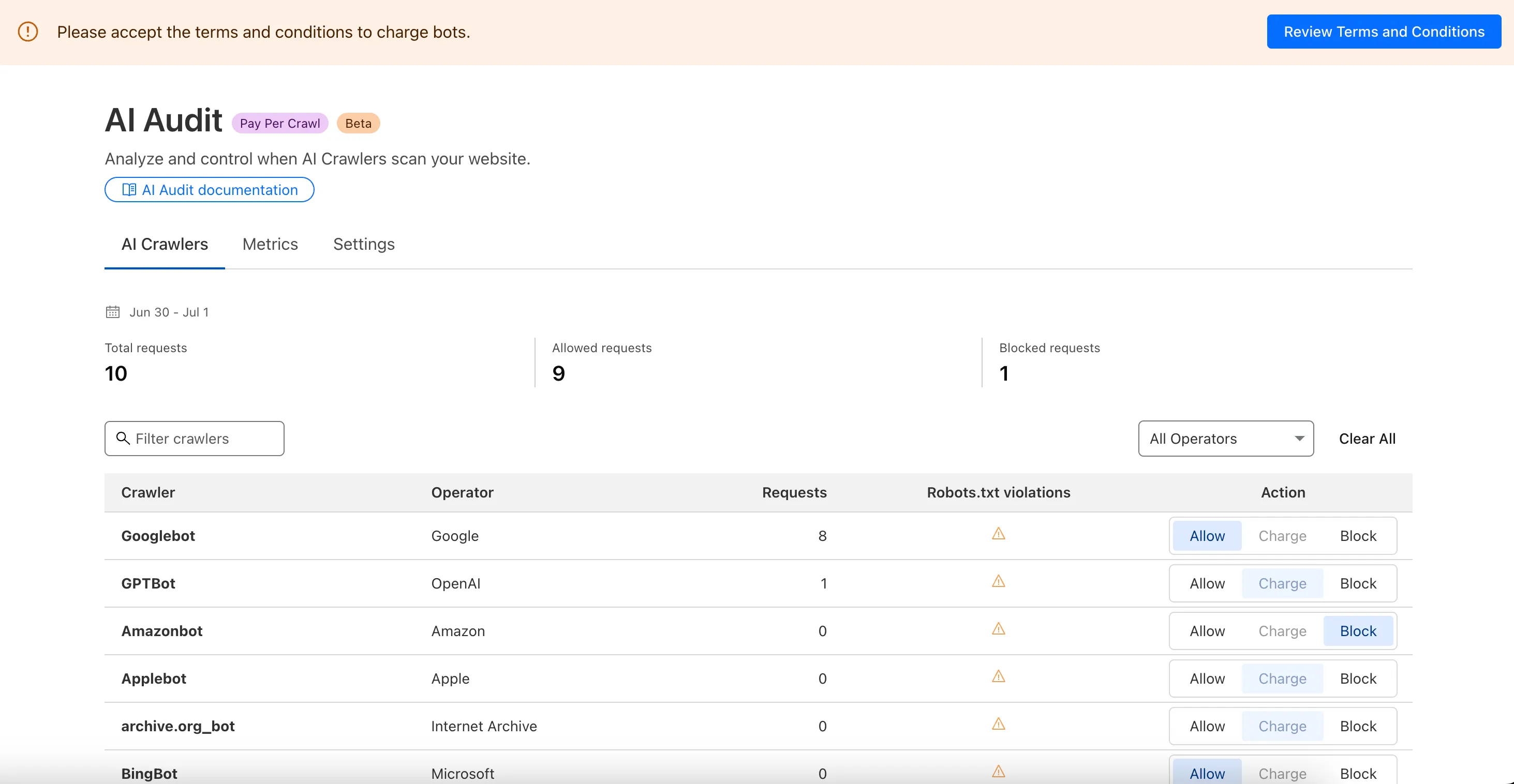
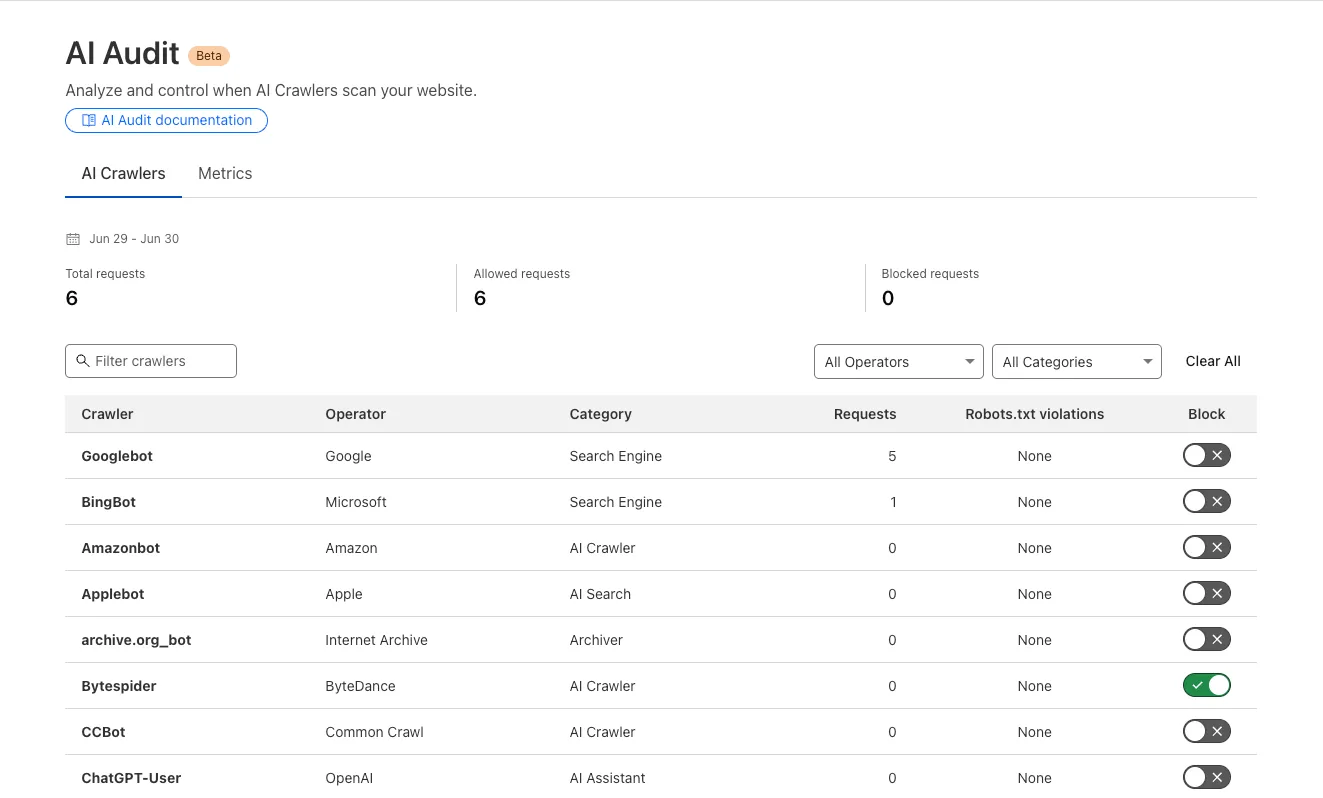
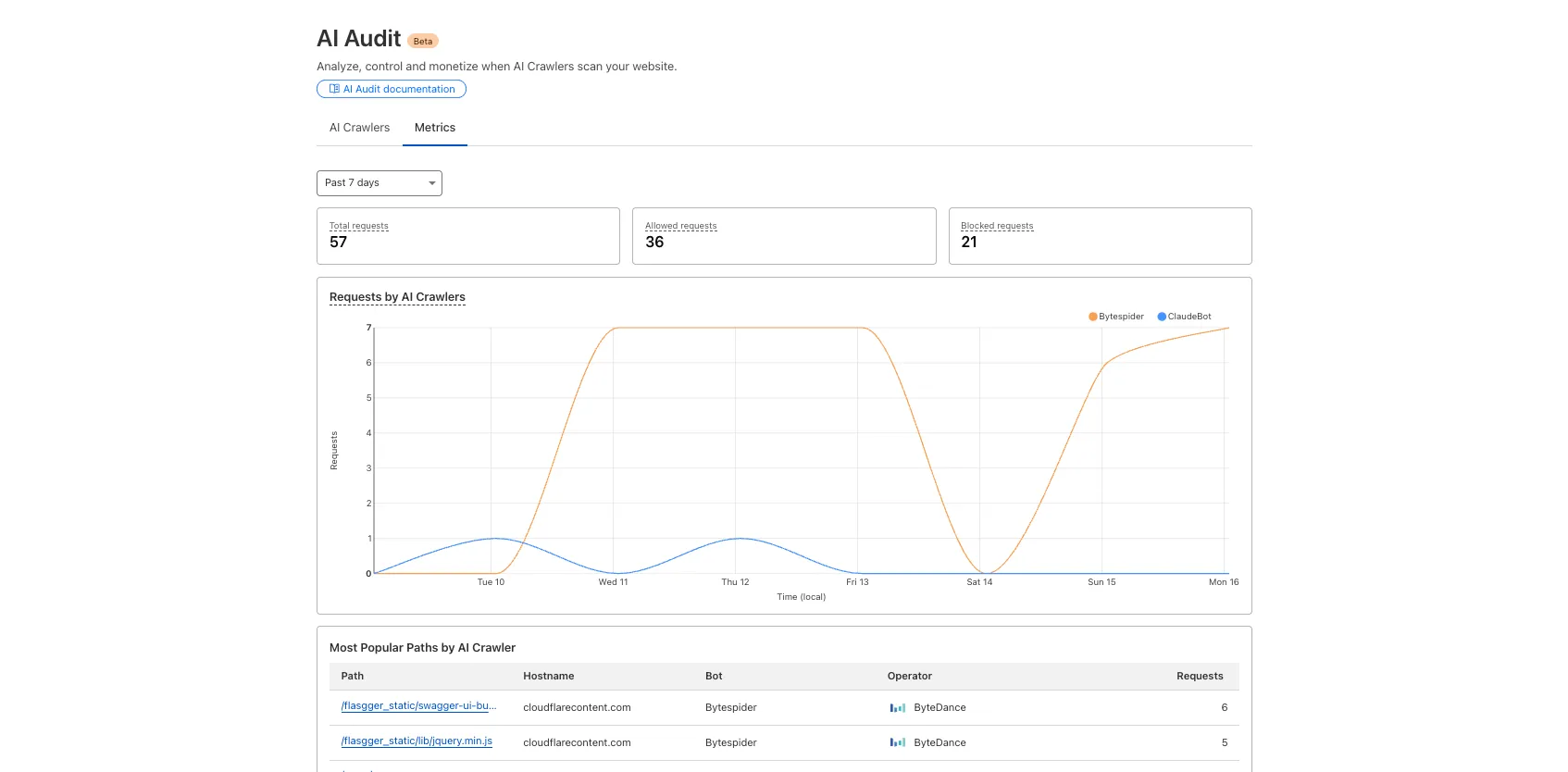
We are introducing a new feature of AI Audit — Pay Per Crawl. Pay Per Crawl enables site owners to require payment from AI crawlers every time the crawlers access their content, thereby fostering a fairer Internet by enabling site owners to control and monetize how their content gets used by AI.
For Site Owners:
Set pricing and select which crawlers to charge for content access
Manage payments via Stripe
Monitor analytics on successful content deliveries
For AI Crawler Owners:
Use HTTP headers to request and accept pricing
Receive clear confirmations on charges for accessed content
/bots/summary: Returns an overview of bot HTTP request distributions across key dimensions.
/bots/timeseries_groups: Provides time-series data on bot request distributions across the same dimensions.
These endpoints support filtering and breakdowns by:
bot: Bot name.
bot_operator: The organization or entity operating the bot.
bot_category: Classification of bot type.
The previously available verified_bots endpoints have now been deprecated in favor of this set of bot insights APIs.
While current data still focuses on verified bots, we plan to expand support for unverified bot traffic in the future.
Learn more about the new Radar bot and crawler insights in our blog post ↗.
You can now use any of Vite's static asset handling ↗ features in your Worker as well as in your frontend.
These include importing assets as URLs, importing as strings and importing from the public directory as well as inlining assets.
Additionally, assets imported as URLs in your Worker are now automatically moved to the client build output.
Here is an example that fetches an imported asset using the assets binding and modifies the response.
// Import the asset URL
// This returns the resolved path in development and production
This release contains improvements and new exciting features, including SCCM VPN boundary support and post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
Fixed a device registration issue that caused WARP connection failures when changing networks.
Captive portal improvements and fixes:
Captive portal sign in notifications will now be sent through operating system notification services.
Fix for firewall configuration issue affecting clients in DoH only mode.
Improved the connectivity status message in the client GUI.
Fixed a bug affecting clients in Gateway with DoH mode where the original DNS servers were not restored after disabling WARP.
The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Improvement to handle client configuration changes made by an MDM while WARP is not running.
Improvements for multi-user experience to better handle fast user switching and transitions from a pre-login to a logged-in state.
Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
Added SCCM VPN boundary support to device profile settings. With SCCM VPN boundary support enabled, operating systems will register WARP's local interface IP with the on-premise DNS server when reachable.
Fix for an issue causing WARP connectivity to fail without full system reboot.
Known issues
Microsoft has confirmed a regression with Windows 11 starting around 24H2 that may cause performance issues for some users. These performance issues could manifest as mouse lag, audio cracking, or other slowdowns. Microsoft's recently released preview build, Windows 11 24H2 KB5060829, may resolve these issues.
Devices with KB5055523 installed may receive a warning about Win32/ClickFix.ABA being present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
Fixed an issue where WARP sometimes failed to automatically relaunch after updating.
Fixed a device registration issue causing WARP connection failures when changing networks.
Captive portal improvements and fixes:
Captive portal sign in notifications will now be sent through operating system notification services.
Fix for firewall configuration issue affecting clients in DoH only mode.
Improved the connectivity status message in the client GUI.
The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Improvement to handle client configuration changes made by an MDM while WARP is not running.
Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
Improvement for WARP connectivity issues on macOS due to the operating system not accepting DNS server configurations.
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
Fixed a device registration issue causing WARP connection failures when changing networks.
Captive portal improvements and fixes:
Captive portal sign in notifications will now be sent through operating system notification services.
Fix for firewall configuration issue affecting clients in DoH only mode.
Improved the connectivity status message in the client GUI.
The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Improvement to handle client configuration changes made by MDM while WARP is not running.
Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
Now, you can use remote bindings with your Next.js applications through the @opennextjs/cloudflare adaptor ↗ by enabling the experimental feature in your next.config.ts:
initOpenNextCloudflareForDev();
initOpenNextCloudflareForDev({
experimental: { remoteBindings: true }
});
Then, all you have to do is specify which bindings you want connected to the deployed resource on your Cloudflare account via the experimental_remote flag in your binding definition:
You can then run next dev to start a local development session (or start a preview with opennextjs-cloudflare preview), and all requests to env.MY_BUCKET will be proxied to the remote testing-bucket — rather than the default local binding simulations.
Remote bindings & ISR
Remote bindings are also used during the build process, which comes with significant benefits for pages using Incremental Static Regeneration (ISR) ↗. During the build step for an ISR page, your server executes the page's code just as it would for normal user requests. If a page needs data to display (like fetching user info from KV), those requests are actually made. The server then uses this fetched data to render the final HTML.
Data fetching is a critical part of this process, as the finished HTML is only as good as the data it was built with. If the build process can't fetch real data, you end up with a pre-rendered page that's empty or incomplete.
With remote bindings support in OpenNext, your pre-rendered pages are built with real data from the start. The build process uses any configured remote bindings, and any data fetching occurs against the deployed resources on your Cloudflare account.
A new GA release for the Android Cloudflare One Agent is now available in the Google Play Store ↗. This release
contains improvements and new exciting features, including post-quantum cryptography.
By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography ↗ without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
QLogs are now disabled by default and can be enabled in the app by turning on Enable qlogs under Settings > Advanced > Diagnostics > Debug Logs. The QLog setting from previous releases will no longer be respected.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
The WARP client now applies post-quantum cryptography ↗ end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Fixed an issue that caused WARP connection failures on ChromeOS devices.
A new GA release for the iOS Cloudflare One Agent is now available in the iOS App Store ↗. This release
contains improvements and new exciting features, including post-quantum cryptography.
By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography ↗ without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
QLogs are now disabled by default and can be enabled in the app by turning on Enable qlogs under Settings > Advanced > Diagnostics > Debug Logs. The QLog setting from previous releases will no longer be respected.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
The WARP client now applies post-quantum cryptography ↗ end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
The Email Routing platform supports SPF ↗ records and DKIM (DomainKeys Identified Mail) ↗ signatures and
honors these protocols when the sending domain has them configured. However, if the sending domain doesn't implement them,
we still forward the emails to upstream mailbox providers.
Starting on July 3, 2025, we will require all emails to be authenticated using at least one of the protocols, SPF or DKIM, to
forward them. We also strongly recommend that all senders implement the DMARC protocol.
If you are using a Worker with an Email trigger to receive email messages and forward them upstream, you will need to handle the case where
the forward action may fail due to missing authentication on the incoming email.
SPAM has been a long-standing issue with email. By enforcing mail authentication, we will increase the efficiency of identifying abusive senders and blocking
bad emails.
If you're an email server delivering emails to large mailbox providers, it's likely you already use these protocols; otherwise, please ensure
you have them properly configured.
Workers can now talk to each other across separate dev commands using service bindings and tail consumers, whether started with vite dev or wrangler dev.
Simply start each Worker in its own terminal:
Terminal window
# Terminal 1
vitedev
# Terminal 2
wranglerdev
This is useful when different teams maintain different Workers, or when each Worker has its own build setup or tooling.
AI is supercharging app development for everyone, but we need a safe way to run untrusted, LLM-written code. We’re introducing Sandboxes ↗, which let your Worker run actual processes in a secure, container-based environment.
exec(command: string, args: string[], options?: { stream?: boolean }):Execute a command in the sandbox.
gitCheckout(repoUrl: string, options: { branch?: string; targetDir?: string; stream?: boolean }): Checkout a git repository in the sandbox.
mkdir(path: string, options: { recursive?: boolean; stream?: boolean }): Create a directory in the sandbox.
writeFile(path: string, content: string, options: { encoding?: string; stream?: boolean }): Write content to a file in the sandbox.
readFile(path: string, options: { encoding?: string; stream?: boolean }): Read content from a file in the sandbox.
deleteFile(path: string, options?: { stream?: boolean }): Delete a file from the sandbox.
renameFile(oldPath: string, newPath: string, options?: { stream?: boolean }): Rename a file in the sandbox.
moveFile(sourcePath: string, destinationPath: string, options?: { stream?: boolean }): Move a file from one location to another in the sandbox.
ping(): Ping the sandbox.
Sandboxes are still experimental. We're using them to explore how isolated, container-like workloads might scale on Cloudflare — and to help define the developer experience around them.
You can try it today from your Worker, with just a few lines of code. Let us know what you build.
The @cloudflare/actors library is a new SDK for Durable Objects and provides a powerful set of abstractions for building real-time, interactive, and multiplayer applications on top of Durable Objects. With beta uasge and feedback, @cloudflare/actors will become the recommended way to build on Durable Objects and draws upon Cloudflare's experience building products/features on Durable Objects.
The name "actors" originates from the actor programming model, which closely ties to how Durable Objects are modelled.
The @cloudflare/actors library includes:
Storage helpers for querying embeddeded, per-object SQLite storage
Storage helpers for managing SQL schema migrations
Alarm helpers for scheduling multiple alarms provided a date, delay in seconds, or cron expression
Actor class for using Durable Objects with a defined pattern
Durable Objects Workers API ↗ is always available for your application as needed
Storage and alarm helper methods can be combined with any Javascript class ↗ that defines your Durable Object, i.e, ones that extend DurableObject including the Actor class.
import {Storage} from "@cloudflare/actors/storage";
exportclassChatRoomextendsDurableObject<Env>{
storage:Storage;
constructor(ctx:DurableObjectState,env:Env){
super(ctx,env)
this.storage=newStorage(ctx.storage);
this.storage.migrations= [{
idMonotonicInc:1,
description:"Create users table",
sql:"CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY)"
constquery=this.storage.sql`SELECT * FROM users WHERE id = ${userId};`
returnnewResponse(`${JSON.stringify(query)}`);
}
}
@cloudflare/actors library introduces the Actor class pattern. Actor lets you access Durable Objects without writing the Worker that communicates with your Durable Object (the Worker is created for you). By default, requests are routed to a Durable Object named "default".
exportclassMyActorextendsActor<Env>{
asyncfetch(request:Request):Promise<Response>{
returnnewResponse('Hello, World!')
}
}
exportdefaulthandler(MyActor);
You can route to different Durable Objects by name within your Actor class using nameFromRequest ↗.
For more examples, check out the library README ↗. @cloudflare/actors library is a place for more helpers and built-in patterns, like retry handling and Websocket-based applications, to reduce development overhead for common Durable Objects functionality. Please share feedback and what more you would like to see on our Discord channel ↗.
We're announcing the GA of User Groups for Cloudflare Dashboard and System for Cross Domain Identity Management (SCIM) User Groups, strengthening our RBAC capabilities with stable, production-ready primitives for managing access at scale.
What's New
User Groups [GA]: User Groups are a new Cloudflare IAM primitive that enable administrators to create collections of account members that are treated equally from an access control perspective. User Groups can be assigned permission policies, with individual members in the group inheriting all permissions granted to the User Group. User Groups can be created manually or via our APIs.
SCIM User Groups [GA]: Centralize & simplify your user and group management at scale by syncing memberships directly from your upstream identity provider (like Okta or Entra ID) to the Cloudflare Platform. This ensures Cloudflare stays in sync with your identity provider, letting you apply Permission Policies to those synced groups directly within the Cloudflare Dashboard.
Stability & Scale:
These features have undergone extensive testing during the Public Beta period and are now ready for production use across enterprises of all sizes.
We’ve increased the total allowed size of blob fields on data points written to Workers Analytics Engine from 5 KB to 16 KB.
This change gives you more flexibility when logging rich observability data — such as base64-encoded payloads, AI inference traces, or custom metadata — without hitting request size limits.
We've simplified the programmatic deployment of Workers via our Cloudflare SDKs. This update abstracts away the low-level complexities of the multipart/form-data upload process, allowing you to focus on your code while we handle the deployment mechanics.
Previously, deploying a Worker programmatically required manually constructing a multipart/form-data HTTP request, packaging your code and a separate metadata.json file. This was more complicated and verbose, and prone to formatting errors.
For example, here's how you would upload a Worker script previously with cURL:
return new Response(env.MESSAGE, { status: 200 });
}
};
EOF
After: SDK interface
With the new SDK interface, you can now define your entire Worker configuration using a single, structured object.
This approach allows you to specify metadata like main_module, bindings, and compatibility_date as clearer properties directly alongside your script content. Our SDK takes this logical object and automatically constructs the complex multipart/form-data API request behind the scenes.
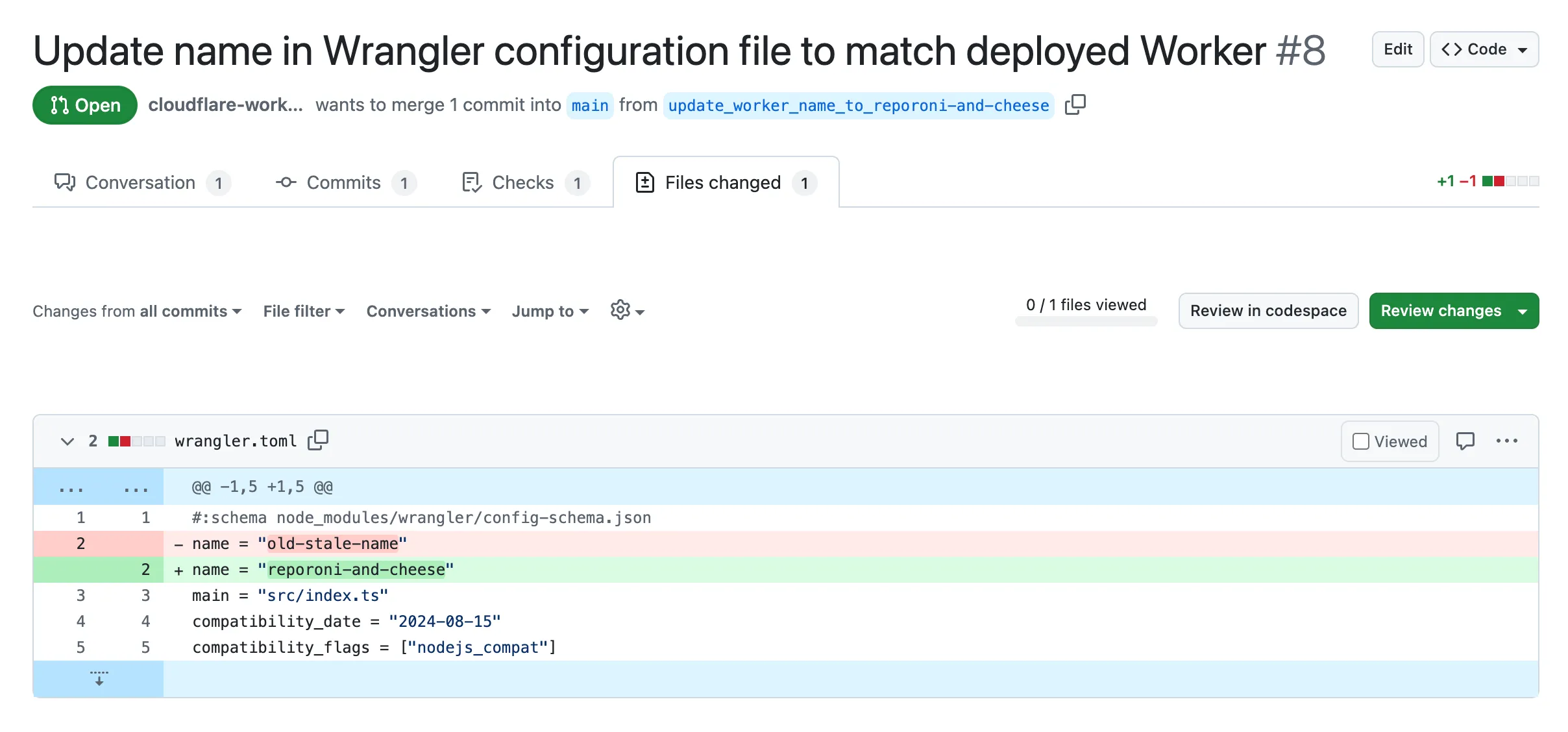
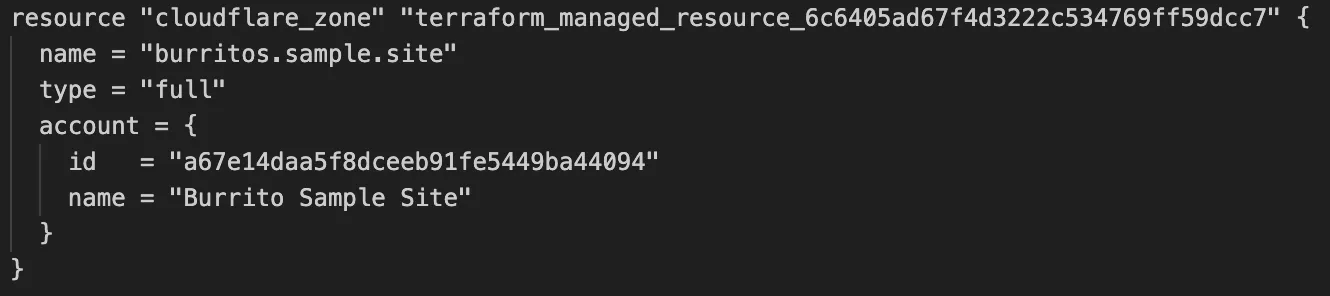
Fixed the cloudflare_workers_script ↗ resource in Terraform, which previously was producing a diff even when there were no changes. Now, your terraform plan outputs will be cleaner and more reliable.
Fixed the cloudflare_workers_for_platforms_dispatch_namespace ↗, where the provider would attempt to recreate the namespace on a terraform apply. The resource now correctly reads its remote state, ensuring stability for production environments and CI/CD workflows.
The cloudflare_workers_route ↗ resource now allows for the script property to be empty, null, or omitted to indicate that pattern should be negated for all scripts (see routes docs). You can now reserve a pattern or temporarily disable a Worker on a route without deleting the route definition itself.
Using primary_location_hint in the cloudflare_d1_database ↗ resource will no longer always try to recreate. You can now safely change the location hint for a D1 database without causing a destructive operation.
This allows users to query DNS analytics across multiple zones in their account, by using the accounts filter.
Here is an example to retrieve the most recent DNS queries across all zones in your account that resulted in an NXDOMAIN response over a given time frame. Please replace a30f822fcd7c401984bf85d8f2a5111c with your actual account ID.
In AutoRAG, you can now view your object's custom metadata in the response from /search and /ai-search, and optionally add a context field in the custom metadata of an object to provide additional guidance for AI-generated answers.
You can add custom metadata to an object when uploading it to your R2 bucket.
Object's custom metadata in search responses
When you run a search, AutoRAG now returns any custom metadata associated with the object. This metadata appears in the response inside attributes then file , and can be used for downstream processing.
For example, the attributes section of your search response may look like:
"context":"A checklist for internal launch readiness, including legal, engineering, and marketing steps."
}
}
}
Add a context field to guide LLM answers
When you include a custom metadata field named context, AutoRAG attaches that value to each chunk of the file. When you run an /ai-search query, this context is passed to the LLM and can be used as additional input when generating an answer.
We recommend using the context field to describe supplemental information you want the LLM to consider, such as a summary of the document or a source URL. If you have several different metadata attributes, you can join them together however you choose within the context string.
For example:
{
"context":"summary: 'Checklist for internal product launch readiness, including legal, engineering, and marketing steps.'; url: 'https://wiki.company.com/docs/launch-checklist'"
}
This gives you more control over how your content is interpreted, without requiring you to modify the original contents of the file.
In AutoRAG, you can now filter by an object's file name using the filename attribute, giving you more control over which files are searched for a given query.
This is useful when your application has already determined which files should be searched. For example, you might query a PostgreSQL database to get a list of files a user has access to based on their permissions, and then use that list to limit what AutoRAG retrieves.
This allows you to connect your application logic with AutoRAG's retrieval process, making it easy to control what gets searched without needing to reindex or modify your data.
Today we announced the public beta ↗ of remote bindings for local development. With remote bindings, you can now connect to deployed resources like R2 buckets and D1 databases while running Worker code on your local machine. This means you can test your local code changes against real data and services, without the overhead of deploying for each iteration.
Example configuration
To enable remote mode, add "experimental_remote" : true to each binding that you want to rely on a remote resource running on Cloudflare:
When remote bindings are configured, your Worker still executes locally, but all binding calls are proxied to the deployed resource that runs on Cloudflare's network.
You can try out remote bindings for local development today with:
Wrangler v4.20.3: Use the wrangler dev --x-remote-bindings command.
The Cloudflare Vite Plugin: Refer to the documentation for how to enable in your Vite config.
The Cloudflare Vitest Plugin: Refer to the documentation for how to enable in your Vitest config.
Have feedback?
Join the discussion in our beta announcement ↗ to share feedback or report any issues.
Gateway will now evaluate Network (Layer 4) policiesbeforeHTTP (Layer 7) policies. This change preserves your existing security posture and does not affect which traffic is filtered — but it may impact how notifications are displayed to end users.
This change will roll out progressively between July 14–18, 2025. If you use HTTP policies, we recommend reviewing your configuration ahead of rollout to ensure the user experience remains consistent.
Updated order of enforcement
Previous order:
DNS policies
HTTP policies
Network policies
New order:
DNS policies
Network policies
HTTP policies
Action required: Review your Gateway HTTP policies
This change may affect block notifications. For example:
You have an HTTP policy to block example.com and display a block page.
You also have a Network policy to block example.com silently (no client notification).
With the new order, the Network policy will trigger first — and the user will no longer see the HTTP block page.
To ensure users still receive a block notification, you can:
Add a client notification to your Network policy, or
Use only the HTTP policy for that domain.
Why we’re making this change
This update is based on user feedback and aims to:
Create a more intuitive model by evaluating network-level policies before application-level policies.
Minimize 526 connection errors by verifying the network path to an origin before attempting to establish a decrypted TLS connection.
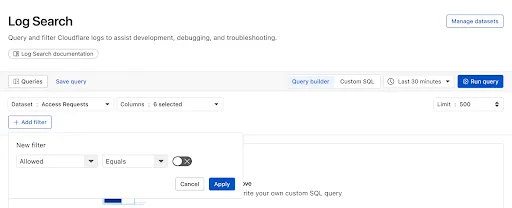
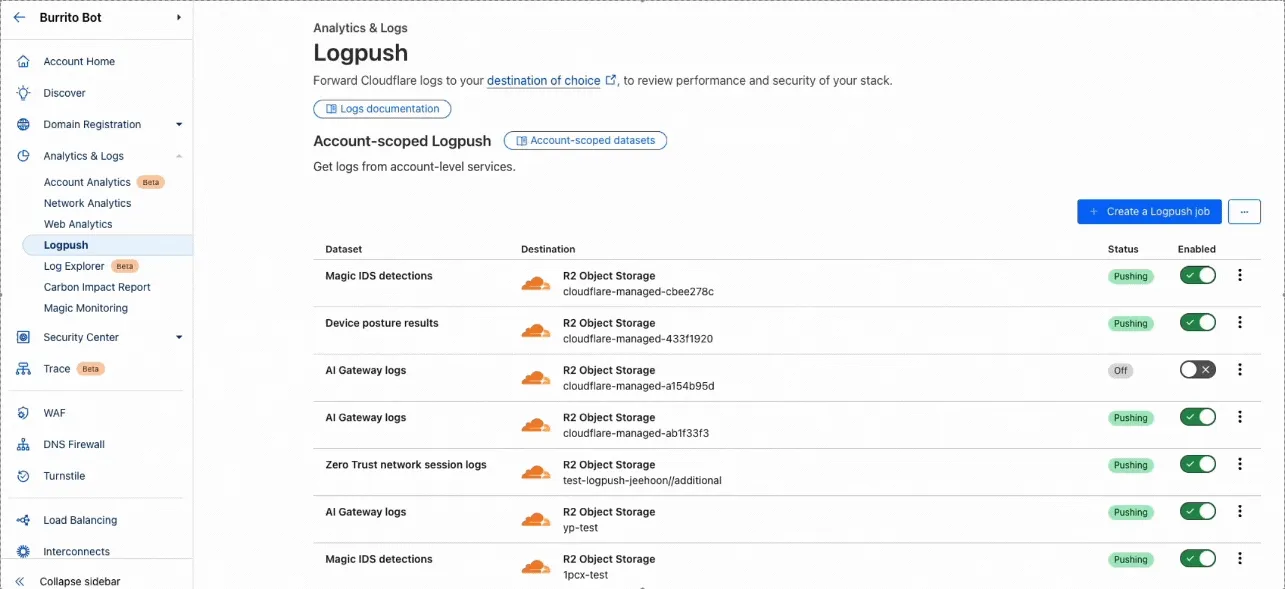
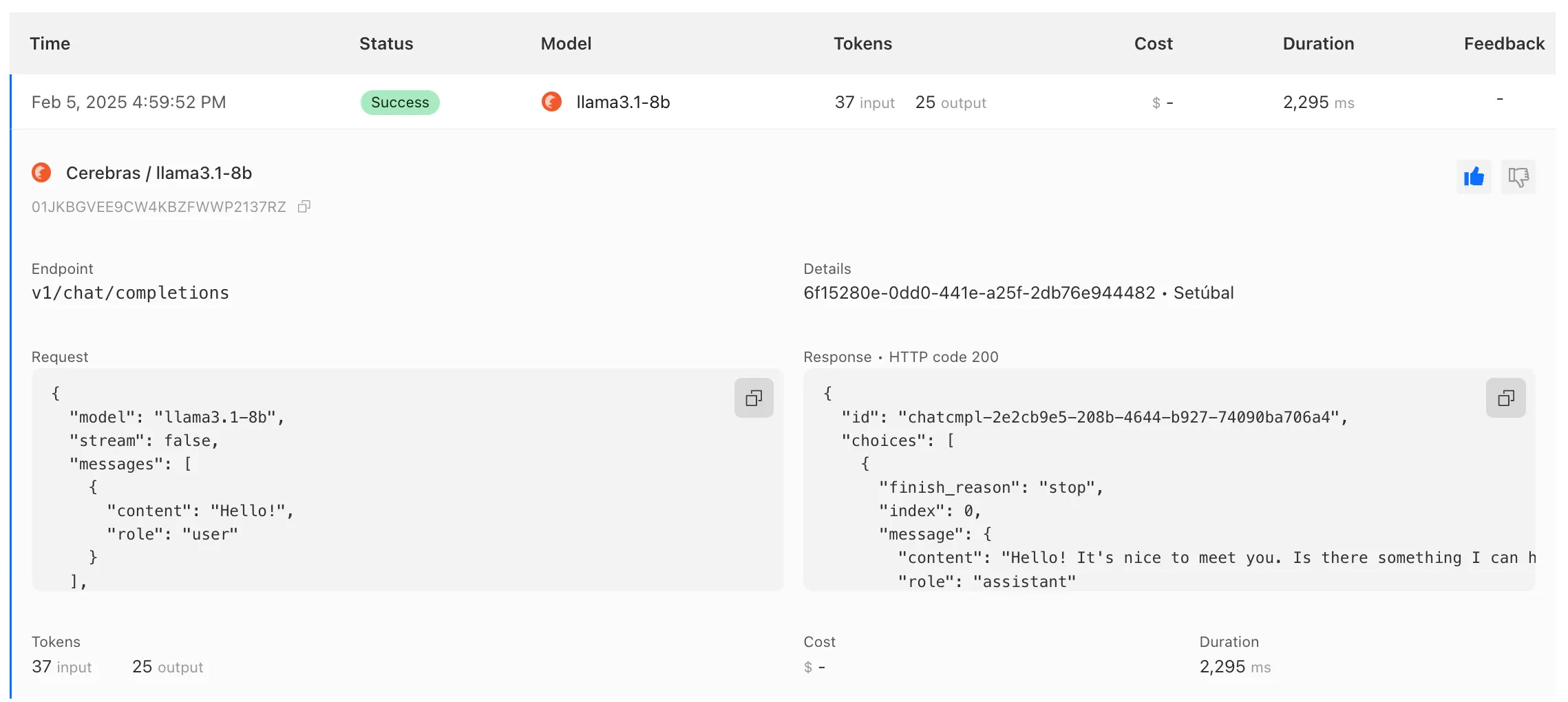
Log Explorer is now GA, providing native observability and forensics for traffic flowing through Cloudflare.
Search and analyze your logs, natively in the Cloudflare dashboard. These logs are also stored in Cloudflare's network, eliminating many of the costs associated with other log providers.
With Log Explorer, you can now:
Monitor security and performance issues with custom dashboards – use natural language to define charts for measuring response time, error rates, top statistics and more.
Investigate and troubleshoot issues with Log Search – use data type-aware search filters or custom sql to investigate detailed logs.
Save time and collaborate with saved queries – save Log Search queries for repeated use or sharing with other users in your account.
Access Log Explorer at the account and zone level – easily find Log Explorer at the account and zone level for querying any dataset.
This release contains new improvements in addition to the features and improvements introduced in Beta client version 2025.5.735.1.
Changes and improvements
Improvement to better handle multi-user fast user switching.
Fix for an issue causing WARP connectivity to fail without full system reboot.
Known issues
Microsoft has confirmed a regression with Windows 11 starting around 24H2 that may cause performance issues for some users. These performance issues could manifest as mouse lag, audio cracking, or other slowdowns. A fix from Microsoft is expected in early July.
Devices with KB5055523 installed may receive a warning about Win32/ClickFix.ABA being present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
This release contains new improvements in addition to the features and improvements introduced in Beta client version 2025.5.735.1.
Changes and improvements
Improvement for WARP connectivity issues on macOS due to the operating system not accepting DNS server configurations.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
For those building Single Page Applications (SPAs) on Workers, you can now explicitly define which routes invoke your Worker script in Wrangler configuration. The run_worker_first config option has now been expanded to accept an array of route patterns, allowing you to more granularly specify when your Worker script runs.
This new routing control was done in partnership with our community and customers who provided great feedback on our public proposal ↗. Thank you to everyone who brought forward use-cases and feedback on the design!
Prerequisites
To use advanced routing control with run_worker_first, you'll need:
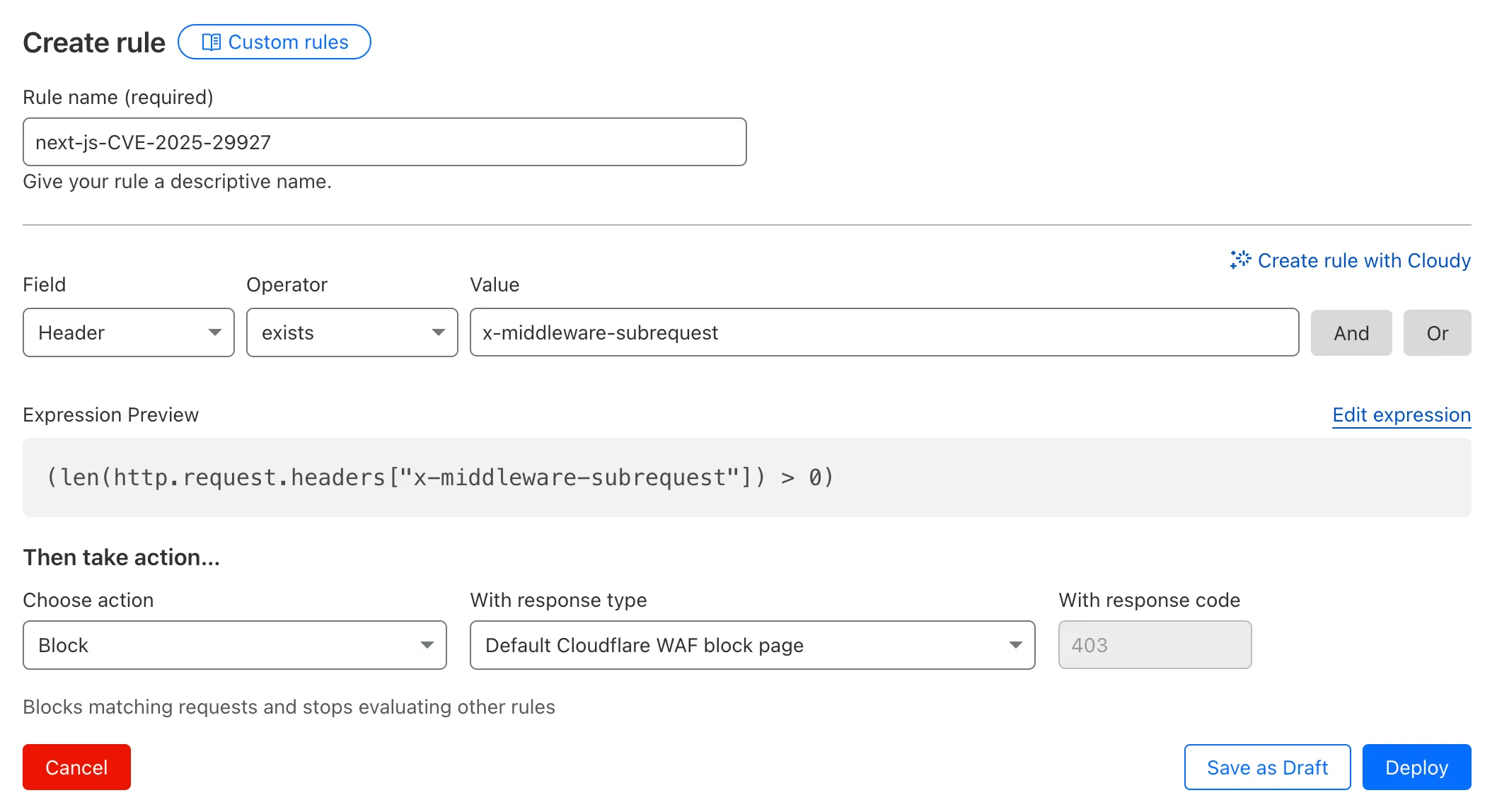
Mitigations have been put in place for all existing and future deployments of sites with the Cloudflare adapter for Open Next in response to an identified Server-Side Request Forgery (SSRF) vulnerability in the @opennextjs/cloudflare package.
The vulnerability stemmed from an unimplemented feature in the Cloudflare adapter for Open Next, which allowed users to proxy arbitrary remote content via the /_next/image endpoint.
This issue allowed attackers to load remote resources from arbitrary hosts under the victim site's domain for any site deployed using the Cloudflare adapter for Open Next. For example: https://victim-site.com/_next/image?url=https://attacker.com. In this example, attacker-controlled content from attacker.com is served through the victim site's domain (victim-site.com), violating the same-origin policy and potentially misleading users or other services.
Potential internal service exposure or phishing risks through domain abuse
Mitigation
The following mitigations have been put in place:
Server side updates to Cloudflare's platform to restrict the content loaded via the /_next/image endpoint to images. The update automatically mitigates the issue for all existing and any future sites deployed to Cloudflare using the affected version of the Cloudflare adapter for Open Next
Root cause fix: Pull request #727 ↗ to the Cloudflare adapter for Open Next. The patched version of the adapter has been released as @opennextjs/cloudflare@1.3.0
Package dependency update: Pull request cloudflare/workers-sdk#9608 ↗ to create-cloudflare (c3) to use the fixed version of the Cloudflare adapter for Open Next. The patched version of create-cloudflare has been published as create-cloudflare@2.49.3.
In addition to the automatic mitigation deployed on Cloudflare's platform, we encourage affected users to upgrade to @opennext/cloudflare v1.3.0 and use the remotePatterns ↗ filter in Next config if they need to allow-list external urls with images assets.
Earlier this year, we announced the launch of the new Terraform v5 Provider.
Unlike the earlier Terraform providers, v5 is automatically generated based on the OpenAPI Schemas for our REST APIs. Since
launch, we have seen an unexpectedly high number of issues ↗
reported by customers. These issues currently impact about 15% of resources. We have been working diligently to address
these issues across the company, and have released the v5.6.0 release which includes a number of bug fixes. Please keep an
eye on this changelog for more information about upcoming releases.
Changes
Broad fixes across resources with recurring diffs, including, but not limited to:
cloudflare_zero_trust_access_identity_provider
cloudflare_zone
cloudflare_page_rules runtime panic when setting cache_level to cache_ttl_by_status
Failure to serialize requests in cloudflare_zero_trust_tunnel_cloudflared_config
Undocumented field 'priority' on zone_lockdown resource
Missing importability for cloudflare_zero_trust_device_default_profile_local_domain_fallback and cloudflare_account_subscription
New resources:
cloudflare_schema_validation_operation_settings
cloudflare_schema_validation_schemas
cloudflare_schema_validation_settings
cloudflare_zero_trust_device_settings
Other bug fixes
For a more detailed look at all of the changes, see the
changelog ↗ in GitHub.
If you have an unaddressed issue with the provider, we encourage you to check the
open issues ↗ and open a new one if one does not already
exist for what you are experiencing.
Upgrading
If you are evaluating a move from v4 to v5, please make use of the
migration guide ↗. We have
provided automated migration scripts using Grit which simplify the transition, although these do not support implementations which
use Terraform modules, so customers making use of modules need to migrate manually. Please make use of terraform plan to test
your changes before applying, and let us know if you encounter any additional issues by reporting to our
GitHub repository ↗.
You can now grant members of your Cloudflare account read-only access to the Workers
Platform.
The new "Workers Platform (Read-only)" role grants read-only access to all products typically used as part of Cloudflare's Developer Platform, including Workers, Pages, Durable Objects, KV, R2, Zones, Zone Analytics and Page Rules. When Cloudflare introduces new products to the Workers platform, we will add additional read-only permissions to this role.
Additionally, the role previously named "Workers Admin" has been renamed to "Workers Platform Admin". This
change ensures that the name more accurately reflects the permissions granted — this
role has always granted access to more than just
Workers — it grants read and write access to the products mentioned above, and similarly, as new products are added to the Workers platform, we will add additional read and write permissions to this role.
Enterprise customers can now select NSEC3 as method for proof of non-existence on their zones.
What's new:
NSEC3 support for live-signed zones – For both primary and secondary zones that are configured to be live-signed (also known as "on-the-fly signing"), NSEC3 can now be selected as proof of non-existence.
NSEC3 support for pre-signed zones – Secondary zones that are transferred to Cloudflare in a pre-signed setup now also support NSEC3 as proof of non-existence.
For more information and how to enable NSEC3, refer to the NSEC3 documentation.
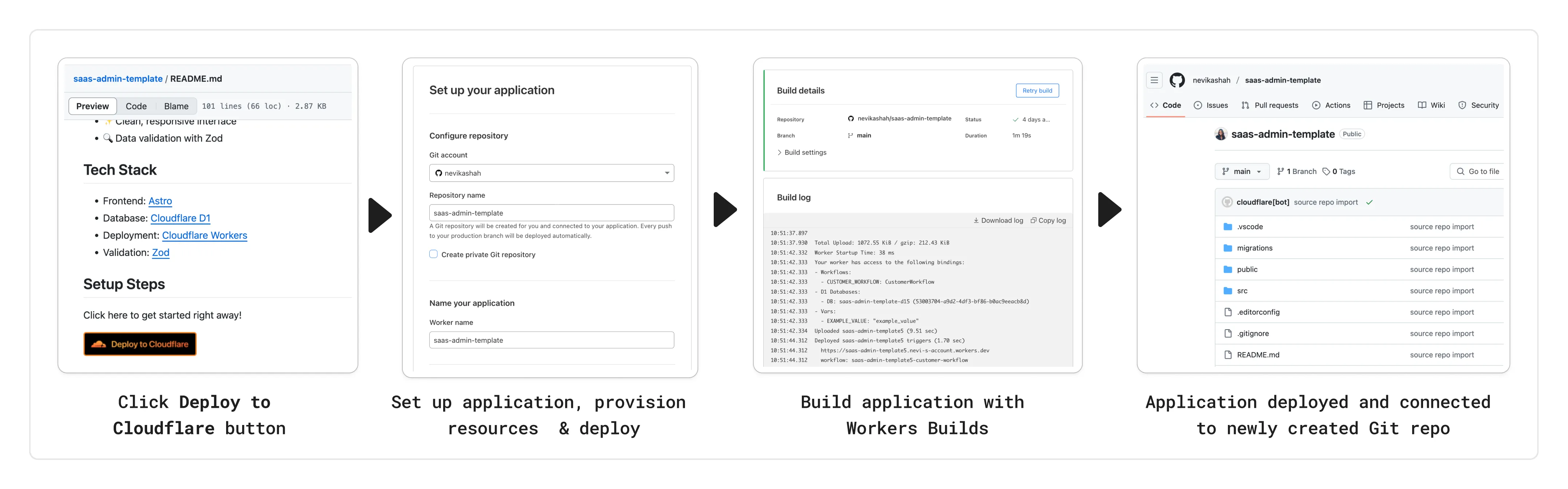
Workers Builds connects your Worker to a Git repository, and automates building and deploying your code on each pushed change.
To make CI/CD pipelines even more flexible, Workers Builds now automatically injects default environment variables into your build process (much like the defaults in Cloudflare Pages projects). You can use these variables to customize your build process based on the deployment context, such as the branch or commit.
The following environment variables are injected by default:
Environment Variable
Injected value
Example use-case
CI
true
Changing build behavior when run on CI versus locally
WORKERS_CI
1
Changing build behavior when run on Workers Builds versus locally
WORKERS_CI_BUILD_UUID
<build-uuid-of-current-build>
Passing the Build UUID along to custom workflows
WORKERS_CI_COMMIT_SHA
<sha1-hash-of-current-commit>
Passing current commit ID to error reporting, for example, Sentry
WORKERS_CI_BRANCH
<branch-name-from-push-event
Customizing build based on branch, for example, disabling debug logging on production
You can override these default values and add your own custom environment variables by navigating to your Worker > Settings > Environment variables.
Workers native integrations were originally launched in May 2023 ↗ to connect to popular database and observability providers with your Worker in just a few clicks. We are changing how developers connect Workers to these external services. The Integrations tab in the dashboard has been removed in favor of a more direct, command-line-based approach using Wrangler secrets.
What's changed
Integrations tab removed: The integrations setup flow is no longer available in the Workers dashboard.
Manual secret configuration: New connections should be configured by adding credentials as secrets to your Workers using npx wrangler secret put commands.
Impact on existing integrations
Existing integrations will continue to work without any changes required. If you have integrations that were previously created through the dashboard, they will remain functional.
Updating existing integrations
If you'd like to modify your existing integration, you can update the secrets, environment variables, or Tail Workers that were created from the original integration setup.
Update secrets: Use npx wrangler secret put <SECRET_NAME> to update credential values.
Modify environment variables: Update variables through the dashboard or Wrangler configuration.
Dashboard management: Access your Worker's settings in the Cloudflare dashboard ↗ to modify connections created by our removed native integrations feature.
If you have previously set up an observability integration with Sentry ↗, the following environment variables were set and are still modifiable:
BLOCKED_HEADERS: headers to exclude sending to Sentry
EXCEPTION_SAMPLING_RATE: number from 0 - 100, where 0 = no events go through to Sentry, and 100 = all events go through to Sentry
STATUS_CODES_TO_SAMPLING_RATES: a map of status codes -- like 400 or with wildcards like 4xx -- to sampling rates described above
Setting up new database and observability connections
For new connections, refer to our step-by-step guides on connecting to popular database and observability providers including: Sentry, Turso, Neon, Supabase, PlanetScale, Upstash, Xata.
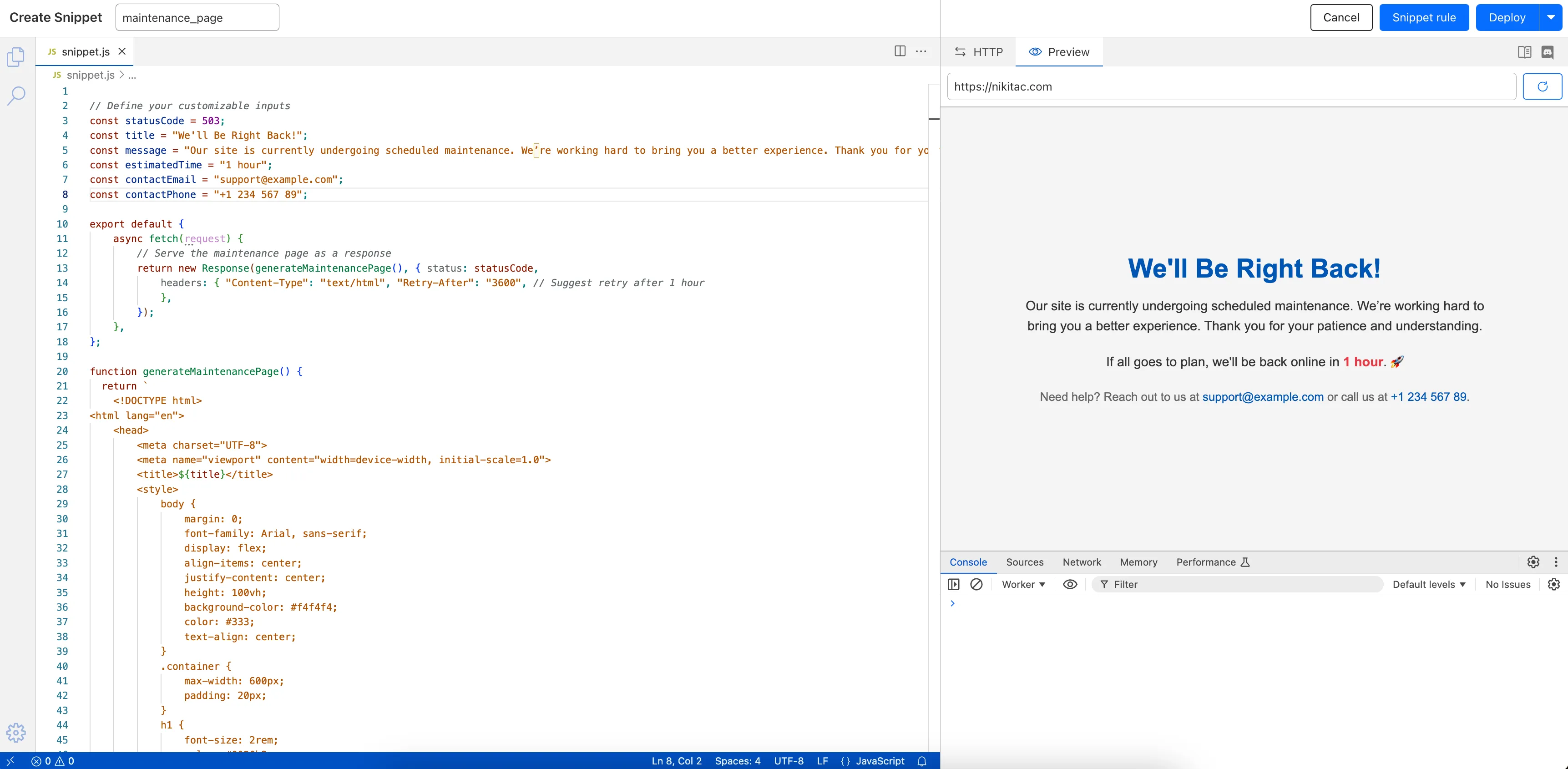
Custom Errors can now fetch and store assets and error pages from your origin even if they are served with a 4xx or 5xx HTTP status code — previously, only 200 OK responses were allowed.
What’s new:
You can now upload error pages and error assets that return error status codes (for example, 403, 500, 502, 503, 504) when fetched.
These assets are stored and minified at the edge, so they can be reused across multiple Custom Error rules without triggering requests to the origin.
This is especially useful for retrieving error content or downtime banners from your backend when you can’t override the origin status code.
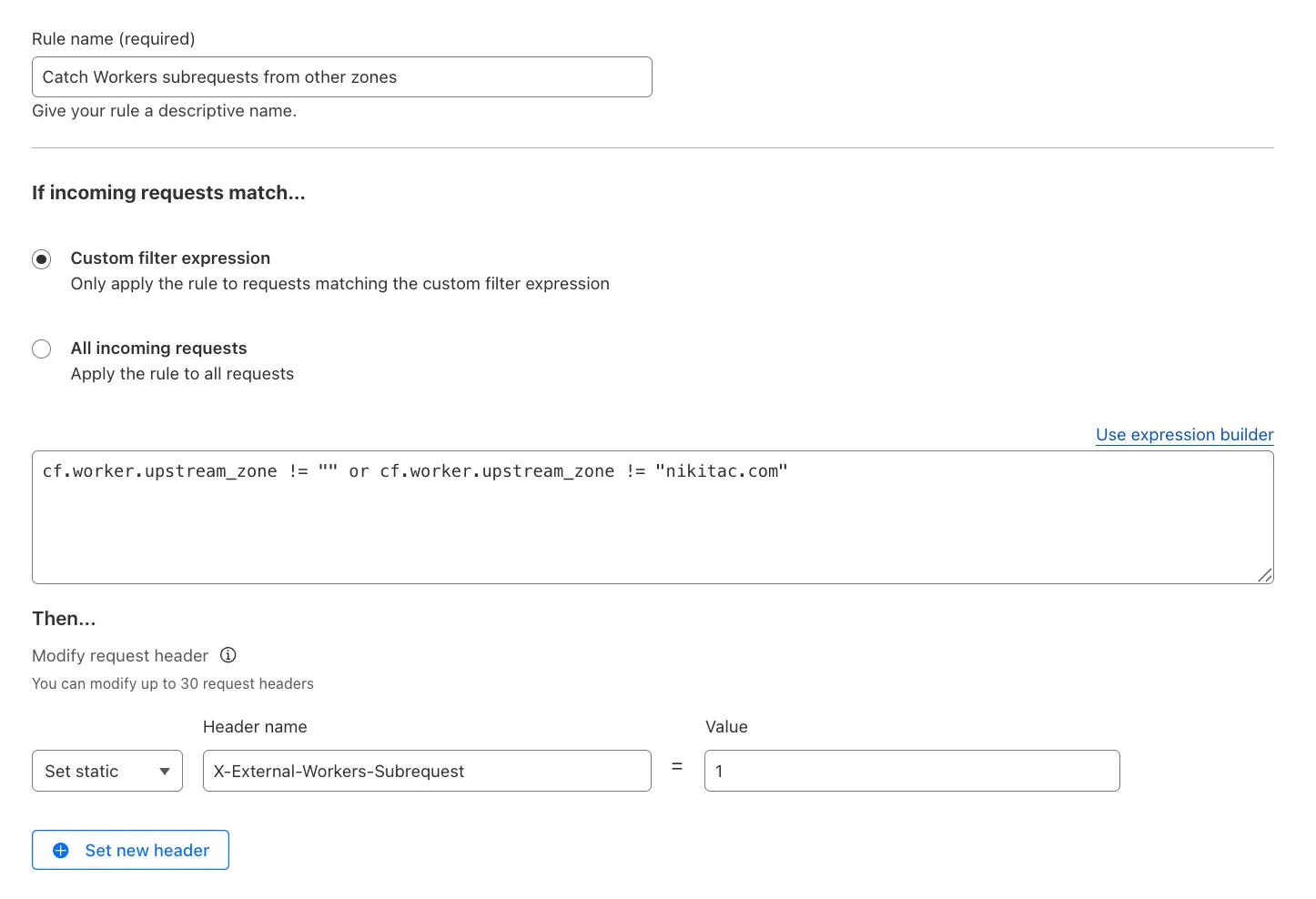
You can now use the cf.worker.upstream_zone field in Transform Rules to control rule execution based on whether a request originates from Workers, including subrequests issued by Workers in other zones.
What's new:
cf.worker.upstream_zone is now supported in Transform Rules expressions.
This release contains improvements and new exciting features, including SCCM VPN boundary support and post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
Fixed a device registration issue causing WARP connection failures when changing networks.
Captive portal improvements including showing connectivity status in the client and sending system notifications for captive portal sign in.
Fixed a bug where in Gateway with DoH mode, connection to DNS servers was not automatically restored after reconnecting WARP.
The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Improvement to gracefully handle changes made by MDM while WARP is not running.
Improvement for multi-user mode to avoid unnecessary key rotations when transitioning from a pre-login to a logged-in state.
Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
Added SCCM VPN boundary support to device profile settings. With SCCM VPN boundary support enabled, operating systems will register WARP's local interface IP with the on-premise DNS server when reachable.
Known issues
Microsoft has confirmed a regression with Windows 11 starting around 24H2 that may cause performance issues for some users. These performance issues could manifest as mouse lag, audio cracking, or other slowdowns. A fix from Microsoft is expected in early July.
Devices with KB5055523 installed may receive a warning about Win32/ClickFix.ABA being present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
This release contains improvements and new exciting features, including post-quantum cryptography. By tunneling your corporate network traffic over Cloudflare, you can now gain the immediate protection of post-quantum cryptography without needing to upgrade any of your individual corporate applications or systems.
Changes and improvements
Fixed an issue where the Cloudflare WARP application may not have automatically relaunched after an update.
Fixed a device registration issue causing WARP connection failures when changing networks.
Captive portal improvements including showing connectivity status in the client and sending system notifications for captive portal sign in.
The WARP client now applies post-quantum cryptography end-to-end on enabled devices accessing resources behind a Cloudflare Tunnel. This feature can be enabled by MDM.
Improvement to gracefully handle changes made by MDM while WARP is not running.
Fixed an issue affecting Split Tunnel Include mode, where traffic outside the tunnel was blocked when switching between Wi-Fi and Ethernet networks.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
Redesigned the user interface, now centralized at the account level.
Introduced Private Load Balancers to the UI, enabling you to manage traffic for all of your external and internal applications in a single spot.
This update streamlines how you manage load balancers across multiple zones and extends robust traffic management to your private network infrastructure.
Key Enhancements:
Account-Level UI Consolidation:
Unified Management: Say goodbye to navigating individual zones for load balancing tasks. You can now view, configure, and monitor all your load balancers across every zone in your account from a single, intuitive interface at the account level.
Improved Efficiency: This centralized approach provides a more streamlined workflow, making it faster and easier to manage both your public-facing and internal traffic distribution.
Private Network Load Balancing:
Secure Internal Application Access: Create Private Load Balancers to distribute traffic to applications hosted within your private network, ensuring they are not exposed to the public Internet.
WARP & Magic WAN Integration: Effortlessly direct internal traffic from users connected via Cloudflare WARP or through your Magic WAN infrastructure to the appropriate internal endpoint pools.
Enhanced Security for Internal Resources: Combine reliable Load Balancing with Zero Trust access controls to ensure your internal services are both performant and only accessible by verified users.
Users can now use an OpenAI Compatible endpoint in AI Gateway to easily switch between providers, while keeping the exact same request and response formats. We're launching now with the chat completions endpoint, with the embeddings endpoint coming up next.
To get started, use the OpenAI compatible chat completions endpoint URL with your own account id and gateway id and switch between providers by changing the model and apiKey parameters.
OpenAI SDK Example
import OpenAI from "openai";
constclient=newOpenAI({
apiKey:"YOUR_PROVIDER_API_KEY",// Provider API key
messages: [{ role:"user", content:"What is Cloudflare?"}],
});
console.log(response.choices[0].message.content);
Additionally, the OpenAI Compatible endpoint can be combined with our Universal Endpoint to add fallbacks across multiple providers. That means AI Gateway will return every response in the same standardized format, no extra parsing logic required!
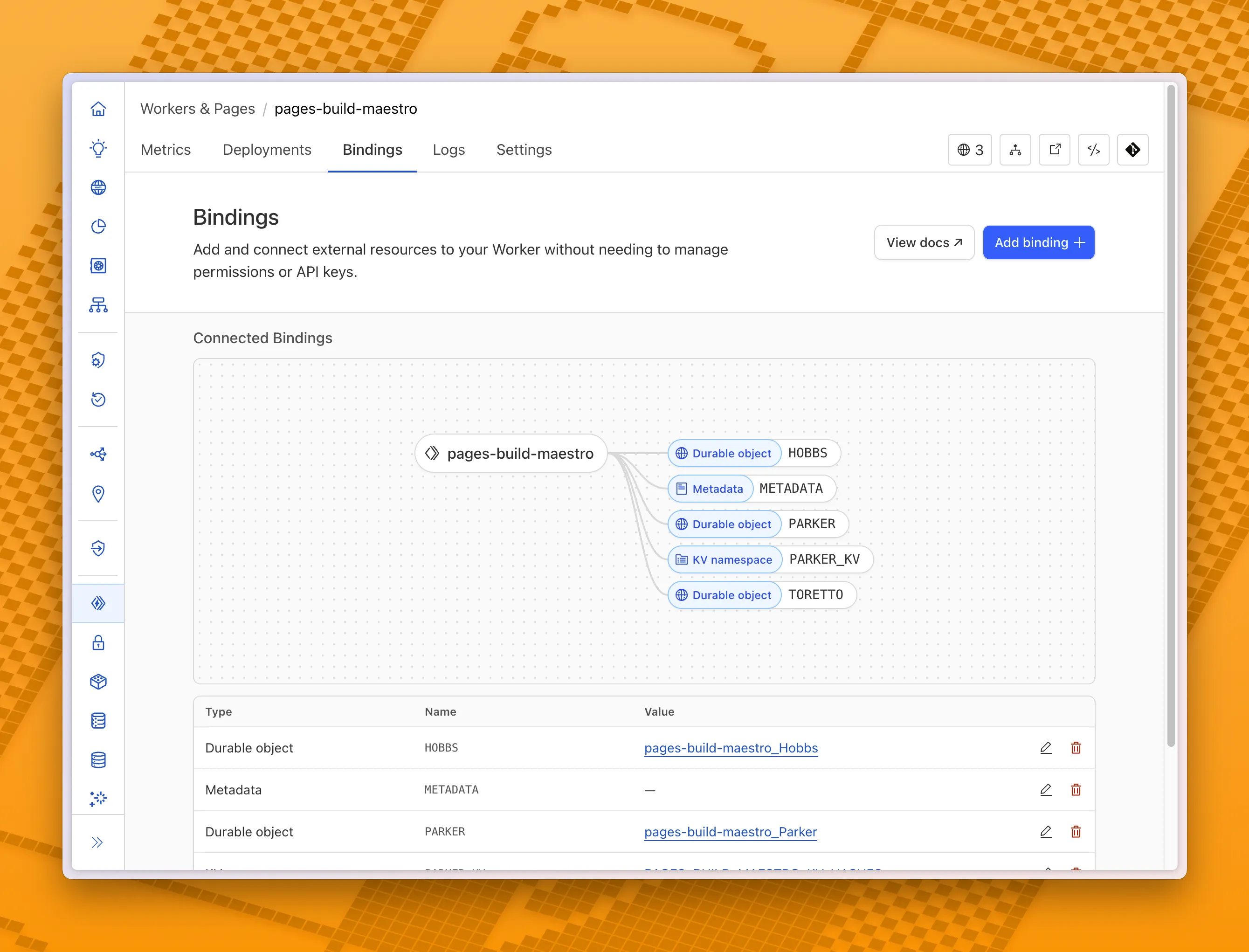
You can now visualize, explore and modify your Worker’s architecture directly in the Cloudflare dashboard, making it easier to understand how your application connects to Cloudflare resources like D1 databases, Durable Objects, KV namespaces, and more.
With this new view, you can easily:
Explore existing bindings in a visual, architecture-style diagram
Add and manage bindings directly from the same interface
Discover the full range of compute, storage, AI, and media resources you can attach to your Workers application.
To get started, head to the Cloudflare dashboard ↗ and open the Bindings tab of any Workers application.
We're excited to announce the Public Beta launch of User Groups for Cloudflare Dashboard and System for Cross Domain Identity Management (SCIM) User Groups, expanding our RBAC capabilities to simplify user and group management at scale.
We've also visually overhauled the Permission Policies UI to make defining permissions more intuitive.
What's New
User Groups [BETA]: User Groups are a new Cloudflare IAM primitive that enable administrators to create collections of account members that are treated equally from an access control perspective. User Groups can be assigned permission policies, with individual members in the group inheriting all permissions granted to the User Group. User Groups can be created manually or via our APIs.
SCIM User Groups [BETA]: Centralize & simplify your user and group management at scale by syncing memberships directly from your upstream identity provider (like Okta or Entra ID) to the Cloudflare Platform. This ensures Cloudflare stays in sync with your identity provider, letting you apply Permission Policies to those synced groups directly within the Cloudflare Dashboard.
Revamped Permission Policies UI [BETA]: As Cloudflare's services have grown, so has the need for precise, role-based access control. We've given the Permission Policies builder a visual overhaul to make it much easier for administrators to find and define the exact permissions they want for specific principals.
You can now enable Polish with the webp format directly in Configuration Rules, allowing you to optimize image delivery for specific routes, user agents, or A/B tests — without applying changes zone-wide.
What’s new:
WebP is now a supported value in the Polish setting for Configuration Rules.
This gives you more precise control over how images are compressed and delivered, whether you're targeting modern browsers, running experiments, or tailoring performance by geography or device type.
Previously, this was only possible if your Worker ran locally using the Wrangler CLI ↗, and now you can do all the same things if your Worker uses Vite ↗.
When you run vite, you'll now see a debug URL in your console:
VITE v6.3.5 ready in 461 ms
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ Debug: http://localhost:5173/__debug
➜ press h + enter to show help
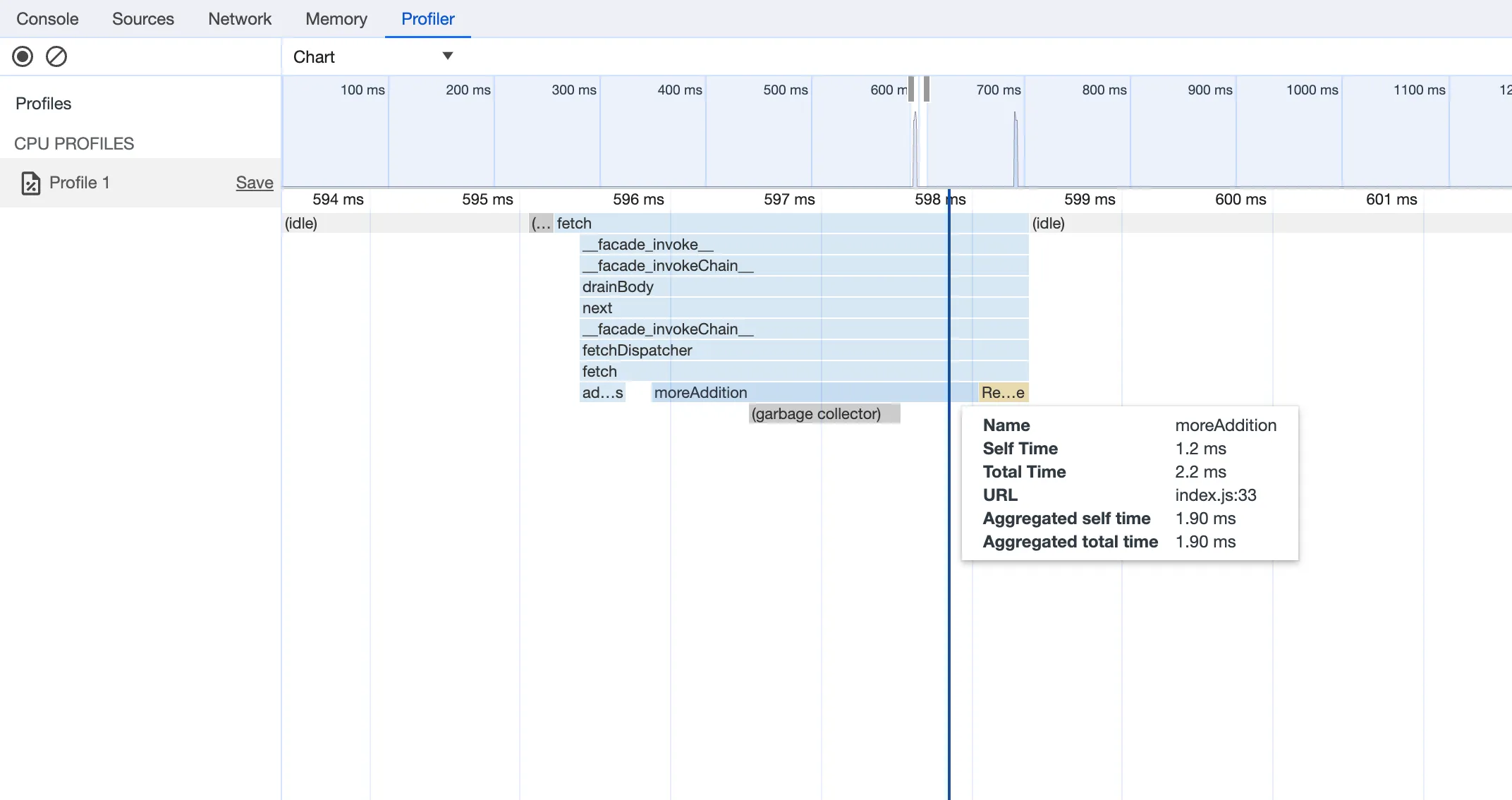
Open the URL in Chrome, and an instance of Chrome Devtools will open and connect to your Worker running locally. You can then use Chrome Devtools to debug and introspect performance issues. For example, you can navigate to the Performance tab to understand where CPU time is spent in your Worker:
For more information on how to get the most out of Chrome Devtools, refer to the following docs:
Users using Cloudflare's REST API to query their D1 database can see lower end-to-end request latency now that D1 authentication is performed at the closest Cloudflare network data center that received the request. Previously, authentication required D1 REST API requests to proxy to Cloudflare's core, centralized data centers, which added network round trips and latency.
Latency improvements range from 50-500 ms depending on request location and database location and only apply to the REST API. REST API requests and databases outside the United States see a bigger benefit since Cloudflare's primary core data centers reside in the United States.
D1 query endpoints like /query and /raw have the most noticeable improvements since they no longer access Cloudflare's core data centers. D1 control plane endpoints such as those to create and delete databases see smaller improvements, since they still require access to Cloudflare's core data centers for other control plane metadata.
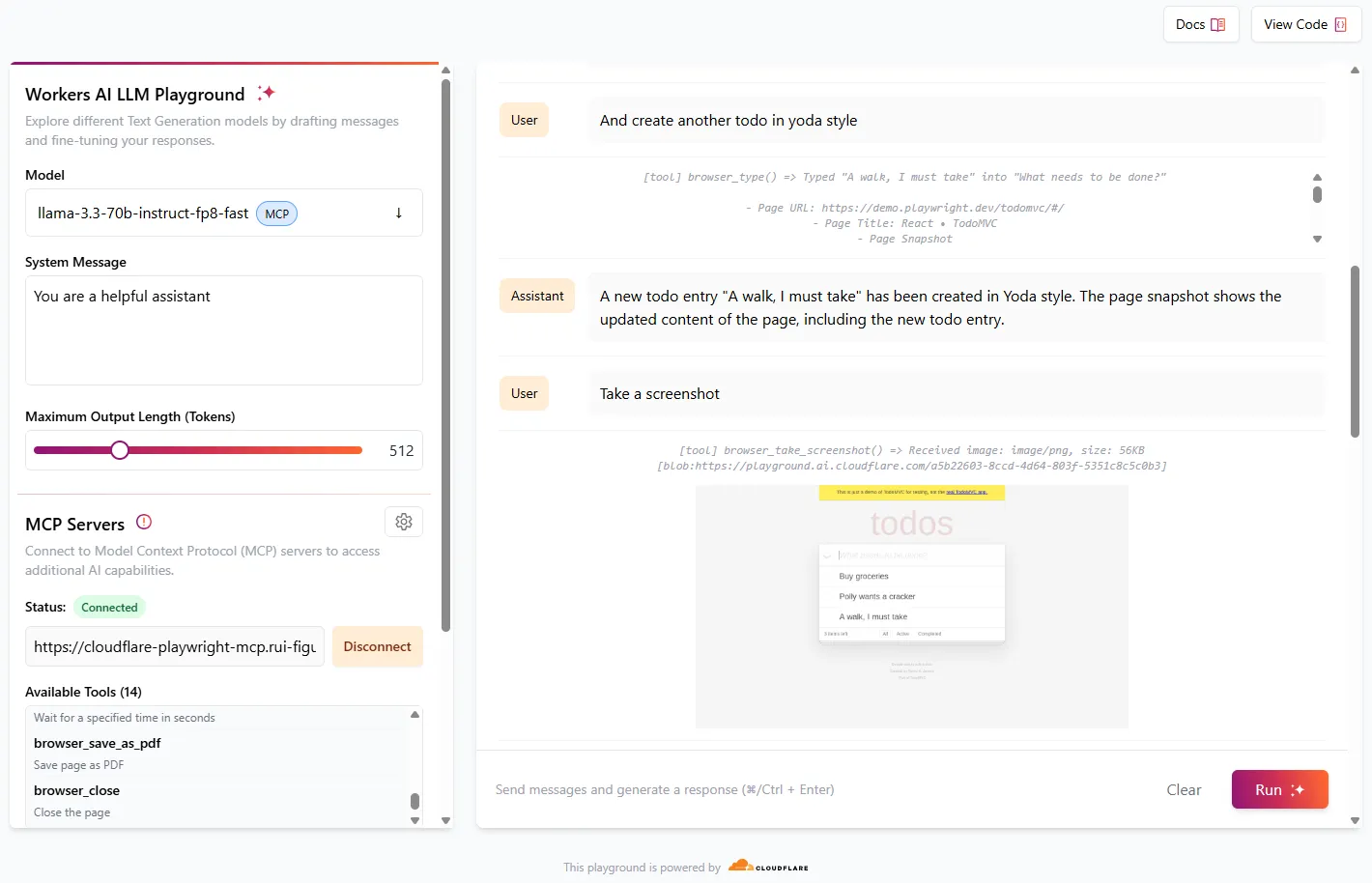
We're excited to share that you can now use the Playwright MCP ↗ server with Browser Rendering.
Once you deploy the server, you can use any MCP client with it to interact with Browser Rendering. This allows you to run AI models that can automate browser tasks, such as taking screenshots, filling out forms, or scraping data.
All Cloudflare One Gateway users can now use Protocol detection logging and filtering, including those on Pay-as-you-go and Free plans.
With Protocol Detection, admins can identify and enforce policies on traffic proxied through Gateway based on the underlying network protocol (for example, HTTP, TLS, or SSH), enabling more granular traffic control and security visibility no matter your plan tier.
This feature is available to enable in your account network settings for all accounts. For more information on using Protocol Detection, refer to the Protocol detection documentation.
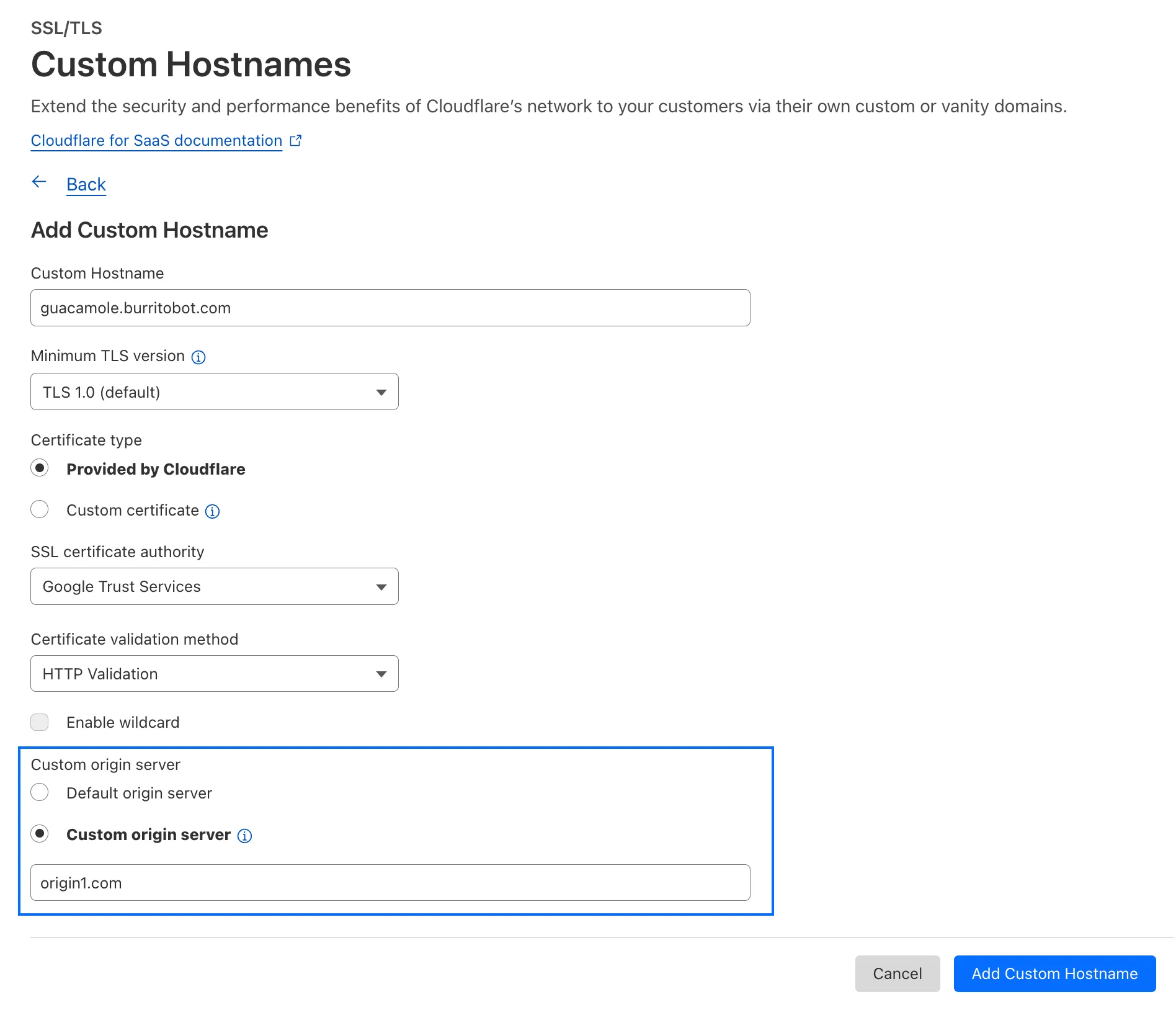
Cloudflare for SaaS ↗ allows you to extend the benefits of Cloudflare to your customers via their own custom or vanity domains. Now, the limit for custom hostnames ↗ on a Cloudflare for SaaS pay-as-you-go plan has been raised from 5,000 custom hostnames to 50,000 custom hostnames.
With custom origin server -- previously an enterprise-only feature -- you can route traffic from one or more custom hostnames somewhere other than your default proxy fallback. Custom origin server ↗ is now available to Cloudflare for SaaS customers on Free, Pro, and Business plans.
You can enable custom origin server on a per-custom hostname basis via the API ↗ or the UI:
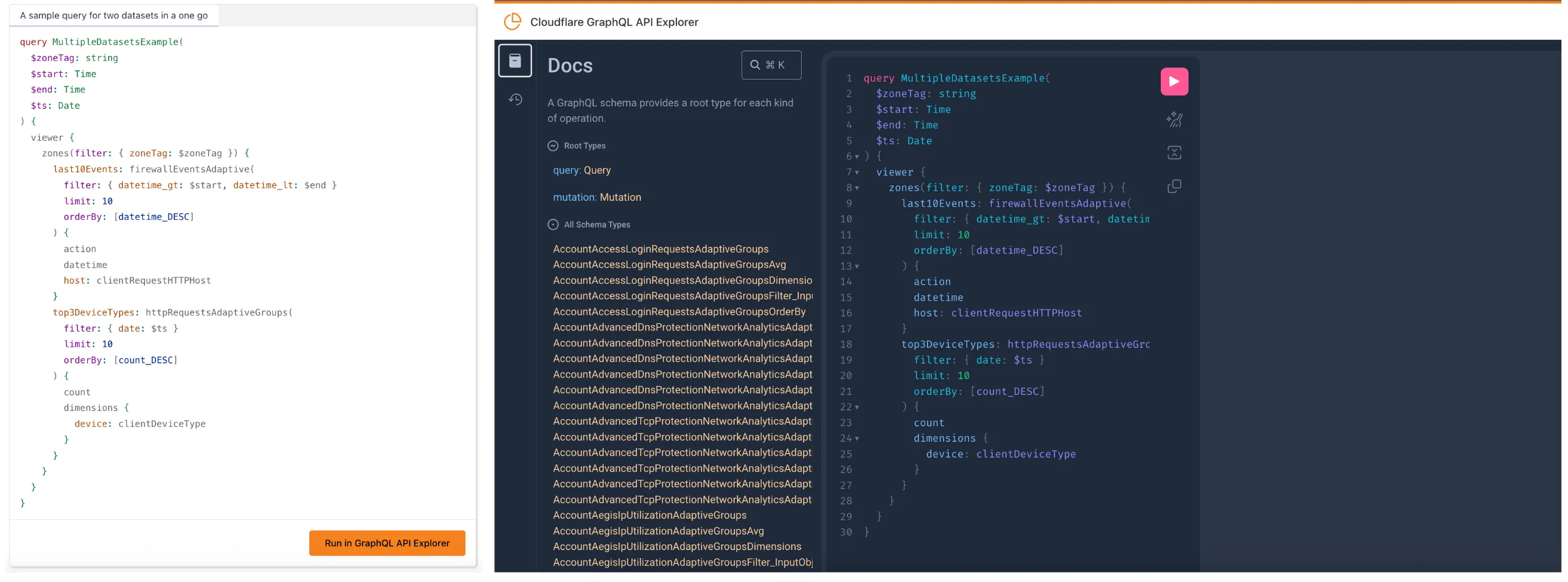
We’ve launched two powerful new tools to make the GraphQL Analytics API more accessible:
GraphQL API Explorer
The new GraphQL API Explorer ↗ helps you build, test, and run queries directly in your browser. Features include:
In-browser schema documentation to browse available datasets and fields
Interactive query editor with autocomplete and inline documentation
A "Run in GraphQL API Explorer" button to execute example queries from our docs
Seamless OAuth authentication — no manual setup required
GraphQL Model Context Protocol (MCP) Server
MCP Servers let you use natural language tools like Claude to generate structured queries against your data. See our blog post ↗ for details on how they work and which servers are available. The new GraphQL MCP server ↗ helps you discover and generate useful queries for the GraphQL Analytics API. With this server, you can:
Explore what data is available to query
Generate and refine queries using natural language, with one-click links to run them in the API Explorer
Build dashboards and visualizations from structured query outputs
Example prompts include:
“Show me HTTP traffic for the last 7 days for example.com”
“What GraphQL node returns firewall events?”
“Can you generate a link to the Cloudflare GraphQL API Explorer with a pre-populated query and variables?”
We’re continuing to expand these tools, and your feedback helps shape what’s next. Explore the documentation to learn more and get started.
This release contains a hotfix for managed networks for the 2025.4.929.0 release.
Changes and improvements
Fixed an issue where it could take up to 3 minutes for the correct device profile to be applied in some circumstances. In the worst case, it should now only take up to 40 seconds. This will be improved further in a future release.
Known issues
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
Microsoft has confirmed a regression with Windows 11 starting around 24H2 that may cause performance issues for some users. These performance issues could manifest as mouse lag, audio cracking, or other slowdowns. A fix from Microsoft is expected in early July.
Devices with KB5055523 installed may receive a warning about Win32/ClickFix.ABA being present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.
This release contains a hotfix for managed networks for the 2025.4.929.0 release.
Changes and improvements
Fixed an issue where it could take up to 3 minutes for the correct device profile to be applied in some circumstances. In the worst case, it should now only take up to 40 seconds. This will be improved further in a future release.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
This release contains a hotfix for managed networks for the 2025.4.929.0 release.
Changes and improvements
Fixed an issue where it could take up to 3 minutes for the correct device profile to be applied in some circumstances. In the worst case, it should now only take up to 40 seconds. This will be improved further in a future release.
In Cloudflare Workers, you can now attach an event listener to Request objects, using the signal property ↗. This allows you to perform tasks when the request to your Worker is canceled by the client. To use this feature, you must set the enable_request_signal compatibility flag.
You can use a listener to perform cleanup tasks or write to logs before your Worker's invocation ends. For example, if you run the Worker below, and then abort the request from the client, a log will be written:
Earlier this year, we announced the launch of the new Terraform v5 Provider. Unlike the earlier Terraform providers, v5 is automatically generated based on the OpenAPI Schemas for our REST APIs. Since launch, we have seen an unexpectedly high number of issues ↗ reported by customers. These issues currently impact about 15% of resources. We have been working diligently to address these issues across the company, and have released the v5.5.0 release which includes a number of bug fixes. Please keep an eye on this changelog for more information about upcoming releases.
Changes
Broad fixes across resources with recurring diffs, including, but not limited to:
cloudflare_zero_trust_gateway_policy
cloudflare_zero_trust_access_application
cloudflare_zero_trust_tunnel_cloudflared_route
cloudflare_zone_setting
cloudflare_ruleset
cloudflare_page_rule
Zone settings can be re-applied without client errors
Page rules conversion errors are fixed
Failure to apply changes to cloudflare_zero_trust_tunnel_cloudflared_route
Other bug fixes
For a more detailed look at all of the changes, see the changelog ↗ in GitHub.
If you have an unaddressed issue with the provider, we encourage you to check the open issues ↗ and open a new one if one does not already exist for what you are experiencing.
Upgrading
If you are evaluating a move from v4 to v5, please make use of the migration guide ↗. We have provided automated migration scripts using Grit which simplify the transition, although these do not support implementations which use Terraform modules, so customers making use of modules need to migrate manually. Please make use of terraform plan to test your changes before applying, and let us know if you encounter any additional issues by reporting to our GitHub repository ↗.
You can now create Durable Objects using
Python Workers. A Durable Object is a special kind of
Cloudflare Worker which uniquely combines compute with storage, enabling stateful
long-running applications which run close to your users. For more info see
here ↗.
You can define a Durable Object in Python in a similar way to JavaScript:
from workers import DurableObject, Response, handler
from urllib.parse import urlparse
classMyDurableObject(DurableObject):
def__init__(self,ctx,env):
self.ctx = ctx
self.env = env
defon_fetch(self,request):
result =self.ctx.storage.sql.exec("SELECT 'Hello, World!' as greeting").one()
returnResponse(result.greeting)
@handler
asyncdefon_fetch(request,env,ctx):
url =urlparse(request.url)
id= env.MY_DURABLE_OBJECT.idFromName(url.path)
stub = env.MY_DURABLE_OBJECT.get(id)
greeting =await stub.fetch(request.url)
return greeting
Define the Durable Object in your Wrangler configuration file:
A new Access Analytics dashboard is now available to all Cloudflare One customers. Customers can apply and combine multiple filters to dive into specific slices of their Access metrics. These filters include:
You can now safely open links in emails to view and investigate them.
From Investigation → View details, look for the Links identified section. Next to each link, an Open in Browser Isolation icon allows your team to safely open the link in a clientless, isolated browser with no risk to the analyst or your environment. Learn more about this feature on our docs.
To use this feature, you must:
Enable Clientless Web Isolation in your Zero Trust settings.
Have Browser Isolation (BISO) seats assigned.
For more details, refer to our setup guide.
This feature is available across all CES packages:
This release contains two significant changes all customers should be aware of:
All DNS traffic now flows inside the WARP tunnel. Customers are no longer required to configure their local firewall rules to allow our DoH IP addresses and domains.
When using MASQUE, the connection will fall back to HTTP/2 (TCP) when we detect that HTTP/3 traffic is blocked. This allows for a much more reliable connection on some public WiFi networks.
Changes and improvements
Fixed an issue causing reconnection loops when captive portals are detected.
Fixed an issue that caused WARP client disk encryption posture checks to fail due to missing drive names.
Fixed an issue where managed network policies could incorrectly report network location beacons as missing.
Improved DEX test error reporting.
Fixed an issue where some parts of the WARP Client UI were missing in high contrast mode.
Fixed an issue causing client notifications to fail in IPv6 only environments which prevented the client from receiving configuration changes to settings like device profile.
Added a TCP fallback for the MASQUE tunnel protocol to improve connectivity on networks that block UDP or HTTP/3 specifically.
Added new IP addresses for tunnel connectivity checks. If your organization uses a firewall or other policies you will need to exempt these IPs.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
Improved the error message displayed in the client GUI when the rate limit for entering an incorrect admin override code is met.
Improved handling of non-SLAAC IPv6 interface addresses for better connectivity in IPv6 only environments.
Fixed an issue where frequent network changes could cause WARP to become unresponsive.
Improvement for WARP to check if tunnel connectivity fails or times out at device wake before attempting to reconnect.
Fixed an issue causing WARP connection disruptions after network changes.
Known issues
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
Microsoft has confirmed a regression with Windows 11 starting around 24H2 that may cause performance issues for some users. These performance issues could manifest as mouse lag, audio cracking, or other slowdowns. A fix from Microsoft is expected in early July.
Devices with KB5055523 installed may receive a warning about Win32/ClickFix.ABA being present in the installer. To resolve this false positive, update Microsoft Security Intelligence to version 1.429.19.0 or later.
Hyperdrive has been approved for FedRAMP Authorization and is now available in the FedRAMP Marketplace ↗.
FedRAMP is a U.S. government program that provides standardized assessment and authorization for cloud products and services. As a result of this product update,
Hyperdrive has been approved as an authorized service to be used by U.S. federal agencies at the Moderate Impact level.
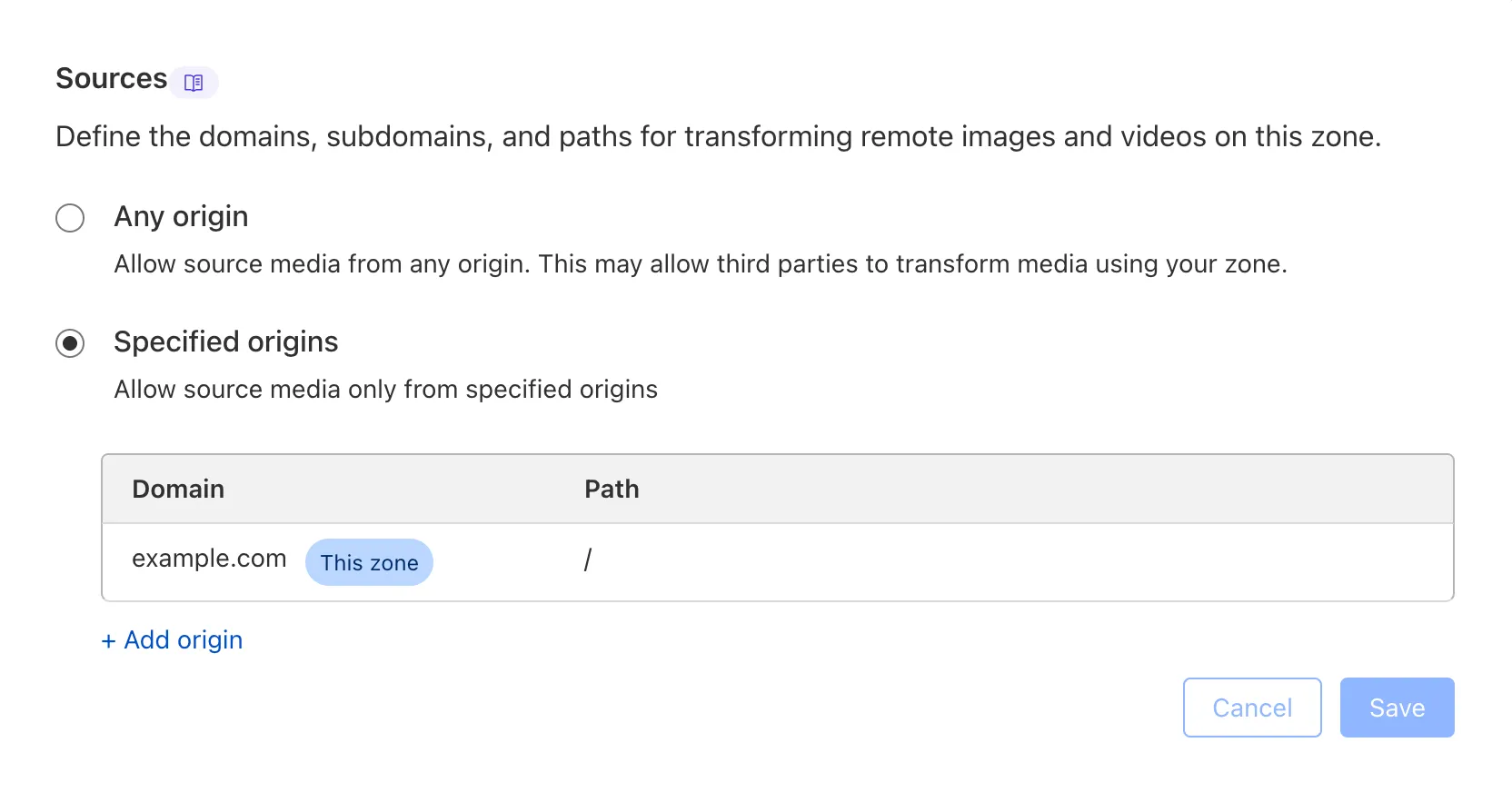
We are adding source origin restrictions to
the Media Transformations beta. This allows customers to restrict what sources
can be used to fetch images and video for transformations. This feature is the
same as --- and uses the same settings as ---
Image Transformations sources.
When transformations is first enabled, the default setting only allows
transformations on images and media from the same website or domain being used to make
the transformation request. In other words, by default, requests to
example.com/cdn-cgi/media can only reference originals on example.com.
Adding access to other sources, or allowing any source,
is easy to do
in the Transformations tab under Stream. Click each domain enabled for
Transformations and set its sources list to match the needs of your content. The
user making this change will need permission to edit zone settings.
You can now create DNS policies to manage outbound traffic for an expanded list of applications.
This update adds support for 273 new applications, giving you more control over your organization's outbound traffic.
With this update, you can:
Create DNS policies for a wider range of applications
Manage outbound traffic more effectively
Improve your organization's security and compliance posture
Remote Browser Isolation (RBI) now supports SAML HTTP-POST bindings, enabling seamless authentication for SSO-enabled applications that rely on POST-based SAML responses from Identity Providers (IdPs) within a Remote Browser Isolation session. This update resolves a previous limitation that caused 405 errors during login and improves compatibility with multi-factor authentication (MFA) flows.
With expanded support for major IdPs like Okta and Azure AD, this enhancement delivers a more consistent and user-friendly experience across authentication workflows. Learn how to set up Remote Browser Isolation.
This release contains two significant changes all customers should be aware of:
All DNS traffic now flows inside the WARP tunnel. Customers are no longer required to configure their local firewall rules to allow our DoH IP addresses and domains.
When using MASQUE, the connection will fall back to HTTP/2 (TCP) when we detect that HTTP/3 traffic is blocked. This allows for a much more reliable connection on some public WiFi networks.
Changes and improvements
Fixed an issue where the managed network policies could incorrectly report network location beacons as missing.
Improved DEX test error reporting.
Fixed an issue causing client notifications to fail in IPv6 only environments which prevented the client from receiving configuration changes to settings like device profile.
Added a TCP fallback for the MASQUE tunnel protocol to improve connectivity on networks that block UDP or HTTP/3 specifically.
Added new IP addresses for tunnel connectivity checks. If your organization uses a firewall or other policies you will need to exempt these IPs.
Fixed an issue where frequent network changes could cause WARP to become unresponsive.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
Improvement for WARP to check if tunnel connectivity fails or times out at device wake before attempting to reconnect.
Fixed an issue causing WARP connection disruptions after network changes.
This release contains two significant changes all customers should be aware of:
All DNS traffic now flows inside the WARP tunnel. Customers are no longer required to configure their local firewall rules to allow our DoH IP addresses and domains.
When using MASQUE, the connection will fall back to HTTP/2 (TCP) when we detect that HTTP/3 traffic is blocked. This allows for a much more reliable connection on some public WiFi networks.
Changes and improvements
Fixed an issue where the managed network policies could incorrectly report network location beacons as missing.
Improved DEX test error reporting.
Fixed an issue causing client notifications to fail in IPv6 only environments which prevented the client from receiving configuration changes to settings like device profile.
Improved captive portal detection.
Added a TCP fallback for the MASQUE tunnel protocol to improve connectivity on networks that block UDP or HTTP/3 specifically.
Added new IP addresses for tunnel connectivity checks. If your organization uses a firewall or other policies you will need to exempt these IPs.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
Improved the error message displayed in the client GUI when the rate limit for entering an incorrect admin override code is met.
Improved handling of non-SLAAC IPv6 interface addresses for better connectivity in IPv6 only environments.
Fixed an issue where frequent network changes could cause WARP to become unresponsive.
Improvement for WARP to check if tunnel connectivity fails or times out at device wake before attempting to reconnect.
Fixed an issue causing WARP connection disruptions after network changes.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
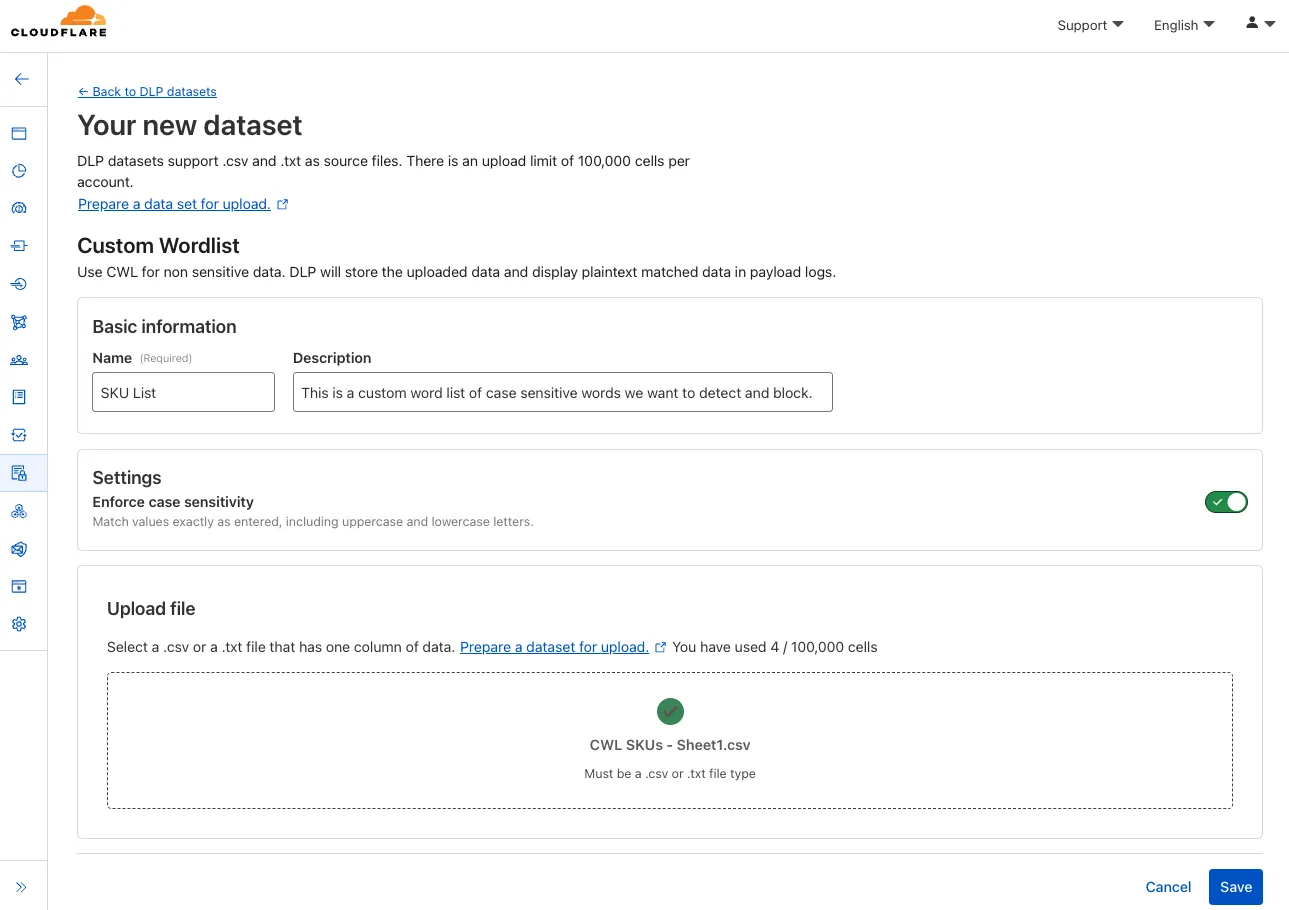
You can now configure custom word lists to enforce case sensitivity. This setting supports flexibility where needed and aims to reduce false positives where letter casing is critical.
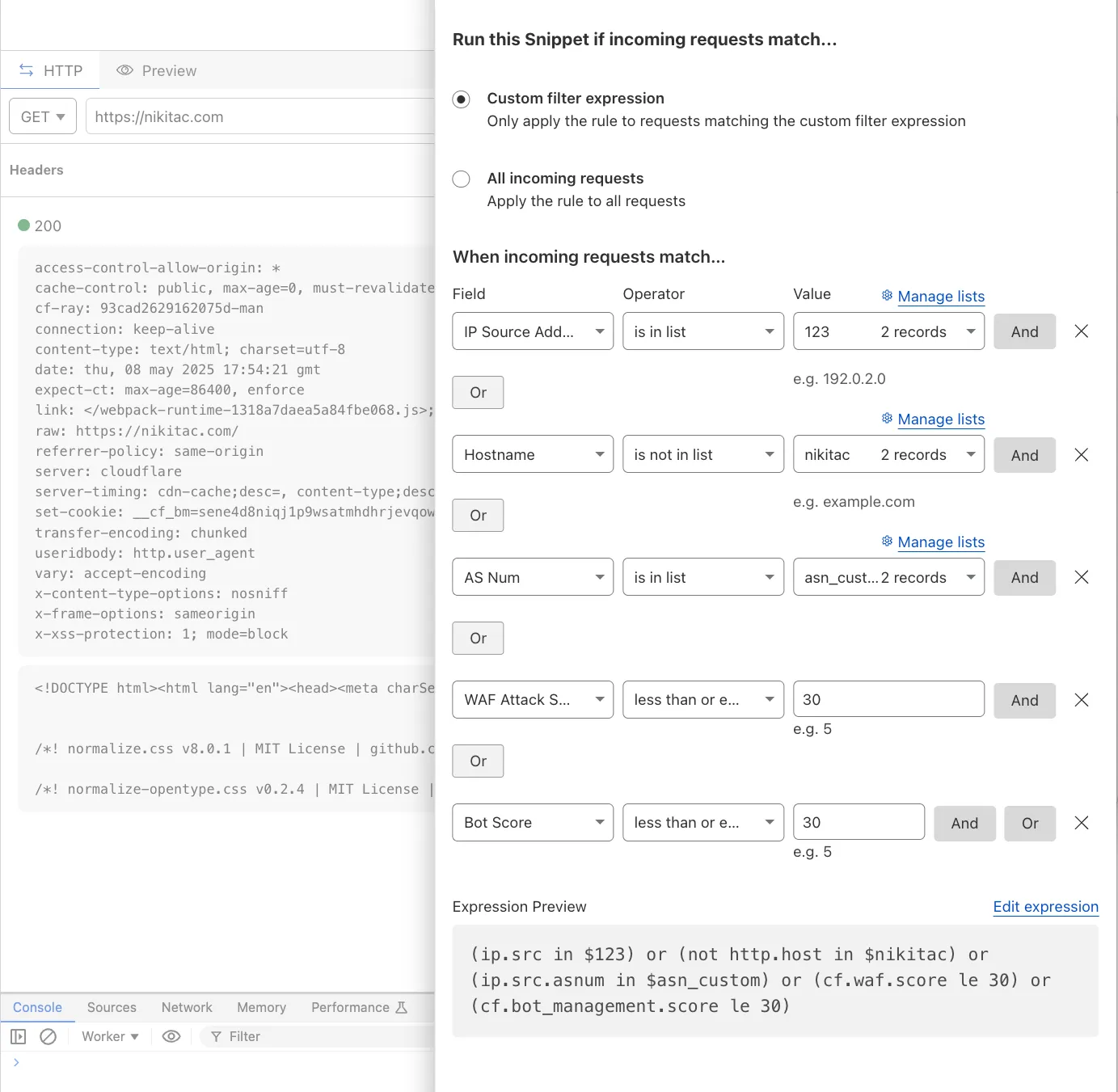
You can now use IP, Autonomous System (AS), and Hostname custom lists to route traffic to Snippets and Cloud Connector, giving you greater precision and control over how you match and process requests at the edge.
In Snippets, you can now also match on Bot Score and WAF Attack Score, unlocking smarter edge logic for everything from request filtering and mitigation to tarpitting and logging.
What’s new:
Custom lists matching – Snippets and Cloud Connector now support user-created IP, AS, and Hostname lists via dashboard or Lists API. Great for shared logic across zones.
Bot Score and WAF Attack Score – Use Cloudflare’s intelligent traffic signals to detect bots or attacks and take advanced, tailored actions with just a few lines of code.
These enhancements unlock new possibilities for building smarter traffic workflows with minimal code and maximum efficiency.
You can now safely open email attachments to view and investigate them.
What this means is that messages now have a Attachments section. Here, you can view processed attachments and their classifications (for example, Malicious, Suspicious, Encrypted). Next to each attachment, a Browser Isolation icon allows your team to safely open the file in a clientless, isolated browser with no risk to the analyst or your environment.
To use this feature, you must:
Enable Clientless Web Isolation in your Zero Trust settings.
Some attachment types may not render in Browser Isolation. If there is a file type that you would like to be opened with Browser Isolation, reach out to your Cloudflare contact.
This feature is available across all CES packages:
Enterprise customers can now choose the geographic location from which a URL scan is performed — either via Security Center in the Cloudflare dashboard or via the URL Scanner API.
This feature gives security teams greater insight into how a website behaves across different regions, helping uncover targeted, location-specific threats.
What’s new:
Location Picker: Select a location for the scan via Security Center → Investigate in the dashboard or through the API.
Region-aware scanning: Understand how content changes by location — useful for detecting regionally tailored attacks.
Default behavior: If no location is set, scans default to the user’s current geographic region.
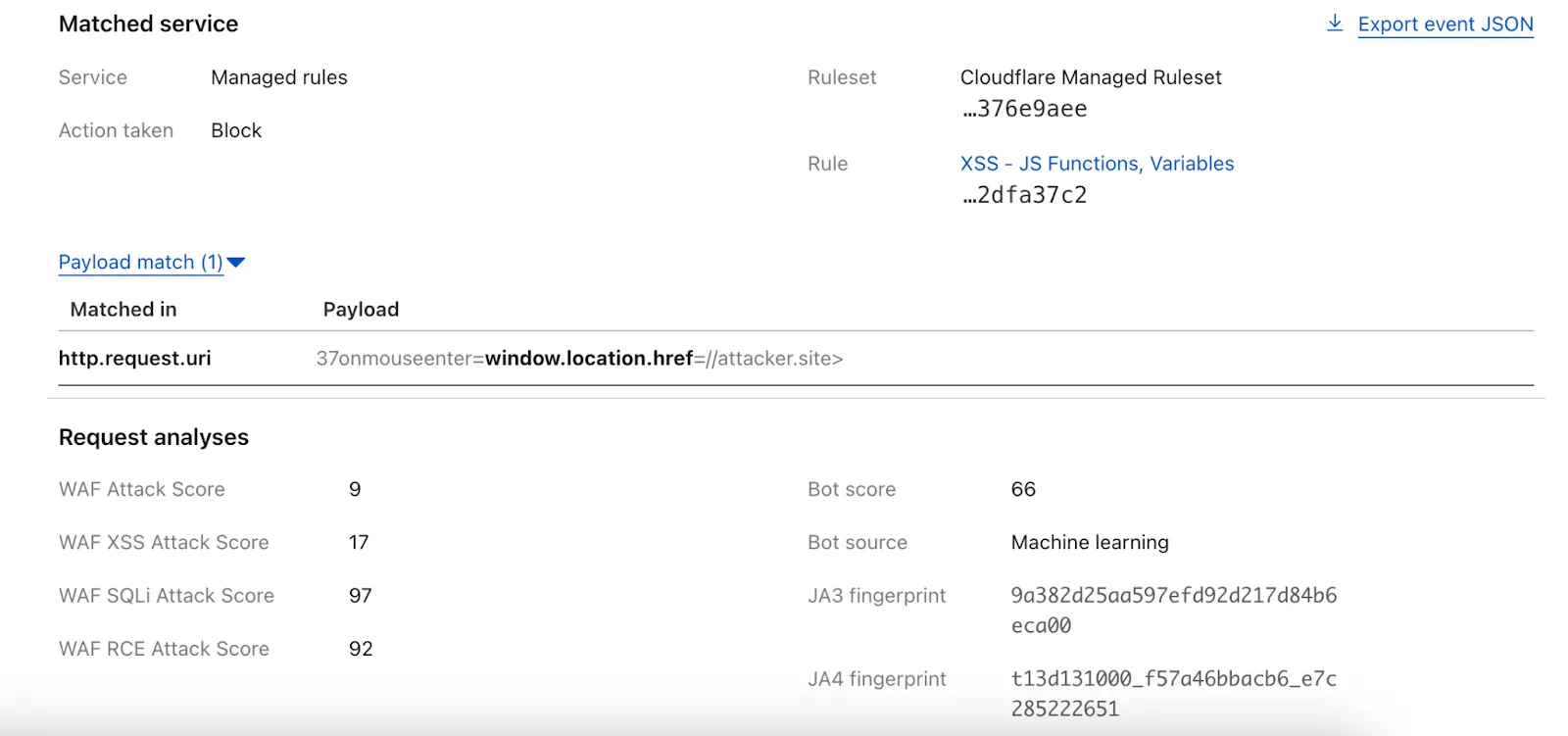
We have upgraded WAF Payload Logging to enhance rule diagnostics and usability:
Targeted logging: Logs now capture only the specific portions of requests that triggered WAF rules, rather than entire request segments.
Visual highlighting: Matched content is visually highlighted in the UI for faster identification.
Enhanced context: Logs now include surrounding context to make diagnostics more effective.
Payload Logging is available to all Enterprise customers. If you have not used Payload Logging before, check how you can get started.
Note: The structure of the encrypted_matched_data field in Logpush has changed from Map<Field, Value> to Map<Field, {Before: bytes, Content: Value, After: bytes}>. If you rely on this field in your Logpush jobs, you should review and update your processing logic accordingly.
This can reduce memory leaks when using WebAssembly-based Workers, which includes Python Workers and Rust Workers. The FinalizationRegistry works by enabling toolchains such as Emscripten ↗ and wasm-bindgen ↗ to automatically free WebAssembly heap allocations. If you are using WASM and seeing Exceeded Memory errors and cannot determine a cause using memory profiling, you may want to enable the FinalizationRegistry.
For more information refer to the enable_weak_ref compatibility flag documentation.
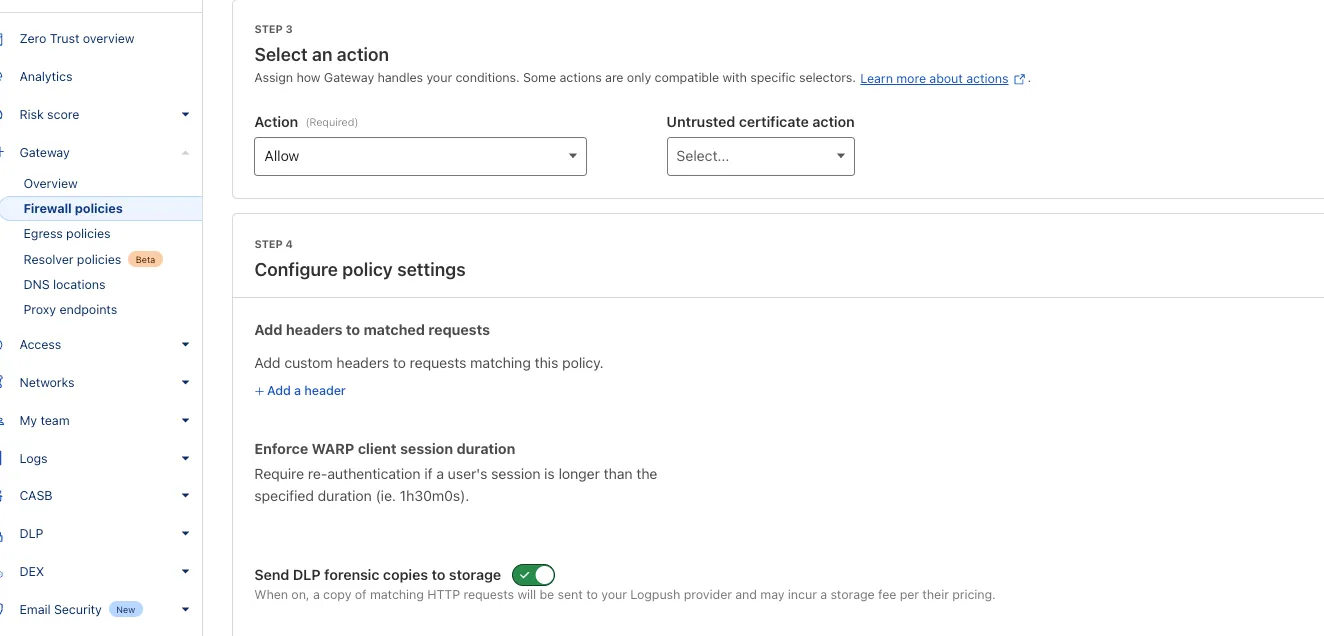
You can now send DLP forensic copies to third-party storage for any HTTP policy with an Allow or Block action, without needing to include a DLP profile. This change increases flexibility for data handling and forensic investigation use cases.
By default, Gateway will send all matched HTTP requests to your configured DLP Forensic Copy jobs.
Earlier this year, we announced the launch of the new Terraform v5 Provider. Unlike the earlier Terraform providers, v5 is automatically generated based on the OpenAPI Schemas for our REST APIs. Since launch, we have seen an unexpectedly high number of issues ↗ reported by customers. These issues currently impact about 15% of resources. We have been working diligently to address these issues across the company, and have released the v5.4.0 release which includes a number of bug fixes. Please keep an eye on this changelog for more information about upcoming releases.
Changes
Removes the worker_platforms_script_secret resource from the provider (see migration guide ↗ for alternatives—applicable to both Workers and Workers for Platforms)
Removes duplicated fields in cloudflare_cloud_connector_rules resource
If you are evaluating a move from v4 to v5, please make use of the migration guide ↗. We have provided automated migration scripts using Grit which simplify the transition, although these do not support implementations which use Terraform modules, so customers making use of modules need to migrate manually. Please make use of terraform plan to test your changes before applying, and let us know if you encounter any additional issues either by reporting to our GitHub repository ↗, or by opening a support ticket ↗.
Cloudflare Load Balancing now supports UDP (Layer 4) and ICMP (Layer 3) health monitors for private endpoints. This makes it simple to track the health and availability of internal services that don’t respond to HTTP, TCP, or other protocol probes.
What you can do:
Set up ICMP ping monitors to check if your private endpoints are reachable.
Use UDP monitors for lightweight health checks on non-TCP workloads, such as DNS, VoIP, or custom UDP-based services.
Gain better visibility and uptime guarantees for services running behind Private Network Load Balancing, without requiring public IP addresses.
This enhancement is ideal for internal applications that rely on low-level protocols, especially when used in conjunction with Cloudflare Tunnel, WARP, and Magic WAN to create a secure and observable private network.
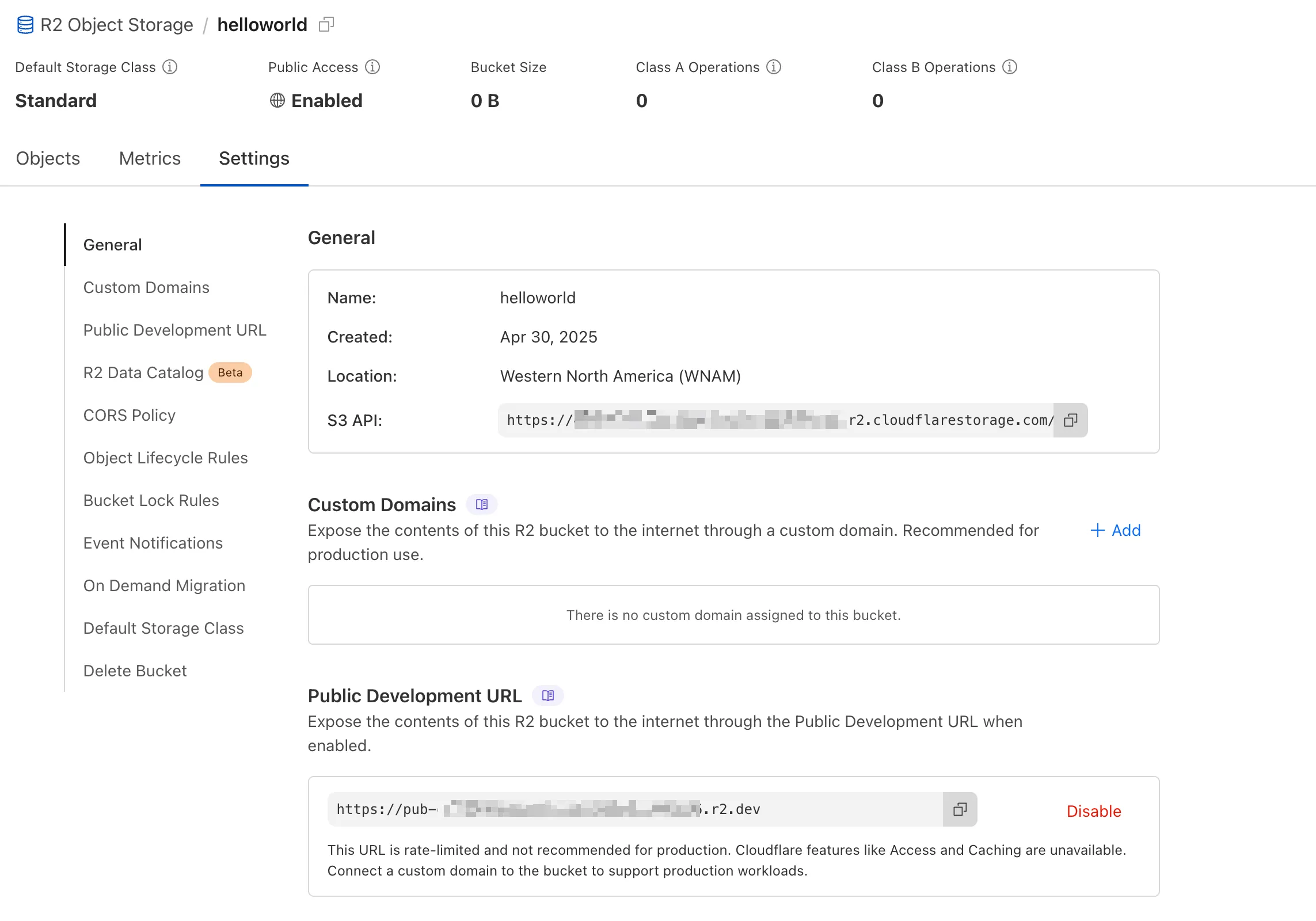
We're excited to announce several improvements to the Cloudflare R2 dashboard experience that make managing your object storage easier and more intuitive:
All-new settings page
We've redesigned the bucket settings page, giving you a centralized location to manage all your bucket configurations in one place.
Improved navigation and sharing
Deeplink support for prefix directories: Navigate through your bucket hierarchy without losing your state. Your browser's back button now works as expected, and you can share direct links to specific prefix directories with teammates.
Objects as clickable links: Objects are now proper links that you can copy or CMD + Click to open in a new tab.
Clearer public access controls
Renamed "r2.dev domain" to "Public Development URL" for better clarity when exposing bucket contents for non-production workloads.
Public Access status now clearly displays "Enabled" when your bucket is exposed to the internet (via Public Development URL or Custom Domains).
We've also made numerous other usability improvements across the board to make your R2 experience smoother and more productive.
A new Browser Isolation Overview page is now available in the Cloudflare Zero Trust dashboard. This centralized view simplifies the management of Remote Browser Isolation (RBI) deployments, providing:
Streamlined Onboarding: Easily set up and manage isolation policies from one location.
Centralized Monitoring: Track aggregate usage and blocked actions.
This update consolidates previously disparate settings, accelerating deployment, improving visibility into isolation activity, and making it easier to ensure your protections are working effectively.
To access the new overview, log in to your Cloudflare Zero Trust dashboard ↗ and find Browser Isolation in the side navigation bar.
Zero Trust Dashboard will automatically accept your user-level preferences for system settings, so if your Dashboard appearance is set to 'system' or 'dark', the Zero Trust dashboard will enter dark mode whenever the rest of your Cloudflare account does.
Cloudflare One administrators can now control which egress IP is used based on a destination's fully qualified domain name (FDQN) within Gateway Egress policies.
Host, Domain, Content Categories, and Application selectors are now available in the Gateway Egress policy builder in beta.
During the beta period, you can use these selectors with traffic on-ramped to Gateway with the WARP client, proxy endpoints (commonly deployed with PAC files), or Cloudflare Browser Isolation.
This will help apply egress IPs to your users' traffic when an upstream application or network requires it, while the rest of their traffic can take the most performant egress path.
Custom Errors are now generally available for all paid plans — bringing a unified and powerful experience for customizing error responses at both the zone and account levels.
You can now manage Custom Error Rules, Custom Error Assets, and redesigned Error Pages directly from the Cloudflare dashboard. These features let you deliver tailored messaging when errors occur, helping you maintain brand consistency and improve user experience — whether it’s a 404 from your origin or a security challenge from Cloudflare.
What's new:
Custom Errors are now GA – Available on all paid plans and ready for production traffic.
UI for Custom Error Rules and Assets – Manage your zone-level rules from the Rules > Overview and your zone-level assets from the Rules > Settings tabs.
Define inline content or upload assets – Create custom responses directly in the rule builder, upload new or reuse previously stored assets.
Refreshed UI and new name for Error Pages – Formerly known as “Custom Pages,” Error Pages now offer a cleaner, more intuitive experience for both zone and account-level configurations.
Powered by Ruleset Engine – Custom Error Rules support conditional logic and override Error Pages for 500 and 1000 class errors, as well as errors originating from your origin or other Cloudflare products. You can also configure Response Header Transform Rules to add, change, or remove HTTP headers from responses returned by Custom Error Rules.
You can now filter AutoRAG search results by folder and timestamp using metadata filtering to narrow down the scope of your query.
This makes it easy to build multitenant experiences where each user can only access their own data. By organizing your content into per-tenant folders and applying a folder filter at query time, you ensure that each tenant retrieves only their own documents.
You can use metadata filtering by creating a new AutoRAG or reindexing existing data. To reindex all content in an existing AutoRAG, update any chunking setting and select Sync index. Metadata filtering is available for all data indexed on or after April 21, 2025.
Fixed an issue causing reconnection loops when captive portals are detected.
Fixed an issue that caused WARP client disk encryption posture checks to fail due to missing drive names.
Fixed an issue where managed network policies could incorrectly report network location beacons as missing.
Improved error reporting for DEX tests.
Improved WARP client UI high contrast mode.
Fixed an issue causing client notifications to fail in IPv6 only environments which prevented the client from receiving configuration changes to settings like device profile.
Added a TCP fallback for the MASQUE tunnel protocol to improve compatibility with networks on MASQUE.
Added new IP addresses for tunnel connectivity checks. If your organization uses a firewall or other policies you will need to exempt these IPs.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
Improved the error message displayed in the client GUI when the rate limit for entering an incorrect admin override code is met.
Added a Collect Captive Portal Diag button in the client GUI to make it easier for users to collect captive portal debugging diagnostics.
Improved handling of non-SLAAC IPv6 interface addresses for better connectivity in IPv6 only environments.
Fixed an issue where frequent network changes could cause WARP to become unresponsive.
Known issues
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
Fixed an issue where managed network policies could incorrectly report network location beacons as missing.
Improved DEX test error reporting.
Fixed an issue causing client notifications to fail in IPv6 only environments which prevented the client from receiving configuration changes to settings like device profile.
Improved captive portal detection.
Added a TCP fallback for the MASQUE tunnel protocol to improve compatibility with networks on MASQUE.
Added new IP addresses for tunnel connectivity checks. If your organization uses a firewall or other policies you will need to exempt these IPs.
DNS over HTTPS traffic is now included in the WARP tunnel by default.
Improved the error message displayed in the client GUI when the rate limit for entering an incorrect admin override code is met.
Added a Collect Captive Portal Diag button in the client GUI to make it easier for users to collect captive portal debugging diagnostics.
Improved handling of non-SLAAC IPv6 interface addresses for better connectivity in IPv6 only environments.
Fixed an issue where frequent network changes could cause WARP to become unresponsive.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
The Access bulk policy tester is now available in the Cloudflare Zero Trust dashboard. The bulk policy tester allows you to simulate Access policies against your entire user base before and after deploying any changes. The policy tester will simulate the configured policy against each user's last seen identity and device posture (if applicable).
Custom Fields now support logging both raw and transformed values for request and response headers in the HTTP requests dataset.
These fields are configured per zone and apply to all Logpush jobs in that zone that include request headers, response headers. Each header can be logged in only one format—either raw or transformed—not both.
By default:
Request headers are logged as raw values
Response headers are logged as transformed values
These defaults can be overidden to suit your logging needs.
For more information refer to Custom fields documentation
You can now retrieve up to 100 keys in a single bulk read request made to Workers KV using the binding.
This makes it easier to request multiple KV pairs within a single Worker invocation. Retrieving many key-value pairs using the bulk read operation is more performant than making individual requests since bulk read operations are not affected by Workers simultaneous connection limits.
// Read single key
constkey="key-a";
constvalue=awaitenv.NAMESPACE.get(key);
// Read multiple keys
constkeys= ["key-a","key-b","key-c",...] // up to 100 keys
Queues pull consumers can now pull and acknowledge up to 5,000 messages / second per queue. Previously, pull consumers were rate limited to 1,200 requests / 5 minutes, aggregated across all queues.
Pull consumers allow you to consume messages over HTTP from any environment—including outside of Cloudflare Workers. They’re also useful when you need fine-grained control over how quickly messages are consumed.
To setup a new queue with a pull based consumer using Wrangler, run:
Create a queue with a pull based consumer
npxwranglerqueuescreatemy-queue
npxwranglerqueuesconsumerhttpaddmy-queue
You can also configure a pull consumer using the REST API or the Queues dashboard.
Once configured, you can pull messages from the queue using any HTTP client. You'll need a Cloudflare API Token with queues_read and queues_write permissions. For example:
To learn more about how to acknowledge messages, pull batches at once, and setup multiple consumers, refer to the pull consumer documentation.
As always, Queues doesn't charge for data egress. Pull operations continue to be billed at the existing rate, of $0.40 / million operations. The increased limits are available now, on all new and existing queues. If you're new to Queues, get started with the Cloudflare Queues guide.
Previously, a request to the Workers Create Route API always returned null for "script" and an empty string for "pattern" even if the request was successful.
The Workers and Workers for Platforms secrets APIs are now properly documented in the Cloudflare OpenAPI docs. Previously, these endpoints were not publicly documented, leaving users confused on how to directly manage their secrets via the API. Now, you can find the proper endpoints in our public documentation, as well as in our API Library SDKs such as cloudflare-typescript ↗ (>4.2.0) and cloudflare-python ↗ (>4.1.0).
Note the cloudflare_workers_secret and cloudflare_workers_for_platforms_script_secretTerraform resources ↗ are being removed in a future release. This resource is not recommended for managing secrets. Users should instead use the:
Secrets Store with the "Secrets Store Secret" binding on Workers and Workers for Platforms Script Upload
Happy Developer Week 2025! Workers AI is excited to announce a couple of new features and improvements available today. Check out our blog ↗ for all the announcement details.
Faster inference + New models
We’re rolling out some in-place improvements to our models that can help speed up inference by 2-4x! Users of the models below will enjoy an automatic speed boost starting today:
@cf/meta/llama-3.3-70b-instruct-fp8-fast gets a speed boost of 2-4x, leveraging techniques like speculative decoding, prefix caching, and an updated inference backend.
With the bge models, we’re also announcing a new parameter called pooling which can take cls or mean as options. We highly recommend using pooling: cls which will help generate more accurate embeddings. However, embeddings generated with cls pooling are not backwards compatible with mean pooling. For this to not be a breaking change, the default remains as mean pooling. Please specify pooling: cls to enjoy more accurate embeddings going forward.
We’re also excited to launch a few new models in our catalog to help round out your experience with Workers AI. We’ll be deprecating some older models in the future, so stay tuned for a deprecation announcement. Today’s new models include:
@cf/mistralai/mistral-small-3.1-24b-instruct: a 24B parameter model achieving state-of-the-art capabilities comparable to larger models, with support for vision and tool calling.
@cf/google/gemma-3-12b-it: well-suited for a variety of text generation and image understanding tasks, including question answering, summarization and reasoning, with a 128K context window, and multilingual support in over 140 languages.
@cf/qwen/qwq-32b: a medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.
Introducing a new batch inference feature that allows you to send us an array of requests, which we will fulfill as fast as possible and send them back as an array. This is really helpful for large workloads such as summarization, embeddings, etc. where you don’t have a human-in-the-loop. Using the batch API will guarantee that your requests are fulfilled eventually, rather than erroring out if we don’t have enough capacity at a given time.
Check out the tutorial to get started! Models that support batch inference today include:
We’ve upgraded our LoRA experience to include 8 newer models, and can support ranks of up to 32 with a 300MB safetensors file limit (previously limited to rank of 8 and 100MB safetensors) Check out our LoRAs page to get started. Models that support LoRAs now include:
You can now use more flexible redirect capabilities in Cloudflare One with Gateway.
A new Redirect action is available in the HTTP policy builder, allowing admins to redirect users to any URL when their request matches a policy. You can choose to preserve the original URL and query string, and optionally include policy context via query parameters.
For Block actions, admins can now configure a custom URL to display when access is denied. This block page redirect is set at the account level and can be overridden in DNS or HTTP policies. Policy context can also be passed along in the URL.
Cloudflare Stream has completed an infrastructure upgrade for our Live WebRTC beta support which brings increased scalability and improved playback performance to all customers. WebRTC allows broadcasting directly from a browser (or supported WHIP client) with ultra-low latency to tens of thousands of concurrent viewers across the globe.
Additionally, as part of this upgrade, the WebRTC beta now supports Signed URLs to protect playback, just like our standard live stream options (HLS/DASH).
Today, we're launching R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket.
If you're not already familiar with it, Apache Iceberg ↗ is an open table format designed to handle large-scale analytics datasets stored in object storage, offering ACID transactions and schema evolution. R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect engines like Spark, Snowflake, and PyIceberg to start querying your tables using the tools you already know.
To enable a data catalog on your R2 bucket, find R2 Data Catalog in your buckets settings in the dashboard, or run:
Terminal window
npxwranglerr2bucketcatalogenablemy-bucket
And that's it. You'll get a catalog URI and warehouse you can plug into your favorite Iceberg engines.
Visit our getting started guide for step-by-step instructions on enabling R2 Data Catalog, creating tables, and running your first queries.
Pipelines let you ingest high volumes of real time data, without managing the underlying infrastructure. A single pipeline can ingest up to 100 MB of data per second, via HTTP or from a Worker. Ingested data is automatically batched, written to output files, and delivered to an R2 bucket in your account. You can use Pipelines to build a data lake of clickstream data, or to store events from a Worker.
D1 read replication is available in public beta to help lower average latency and increase overall throughput for read-heavy applications like e-commerce websites or content management tools.
Workers can leverage read-only database copies, called read replicas, by using D1 Sessions API. A session encapsulates all the queries from one logical session for your application. For example, a session may correspond to all queries coming from a particular web browser session. With Sessions API, D1 queries in a session are guaranteed to be sequentially consistent to avoid data consistency pitfalls. D1 bookmarks can be used from a previous session to ensure logical consistency between sessions.
// retrieve bookmark from previous session stored in HTTP header
Read replicas are automatically created by Cloudflare (currently one in each supported D1 region), are active/inactive based on query traffic, and are transparently routed to by Cloudflare at no additional cost.
To checkout D1 read replication, deploy the following Worker code using Sessions API, which will prompt you to create a D1 database and enable read replication on said database.
To learn more about how read replication was implemented, go to our blog post ↗.
Hyperdrive now supports more SSL/TLS security options for your database connections:
Configure Hyperdrive to verify server certificates with verify-ca or verify-full SSL modes and protect against man-in-the-middle attacks
Configure Hyperdrive to provide client certificates to the database server to authenticate itself (mTLS) for stronger security beyond username and password
Use the new wrangler cert commands to create certificate authority (CA) certificate bundles or client certificate pairs:
Cloudflare Snippets are now generally available at no extra cost across all paid plans — giving you a fast, flexible way to programmatically control HTTP traffic using lightweight JavaScript.
You can now use Snippets to modify HTTP requests and responses with confidence, reliability, and scale. Snippets are production-ready and deeply integrated with Cloudflare Rules, making them ideal for everything from quick dynamic header rewrites to advanced routing logic.
What's new:
Snippets are now GA – Available at no extra cost on all Pro, Business, and Enterprise plans.
Ready for production – Snippets deliver a production-grade experience built for scale.
Part of the Cloudflare Rules platform – Snippets inherit request modifications from other Cloudflare products and support sequential execution, allowing you to run multiple Snippets on the same request and apply custom modifications step by step.
Trace integration – Use Cloudflare Trace to see which Snippets were triggered on a request — helping you understand traffic flow and debug more effectively.
Cloudflare Secrets Store is available today in Beta. You can now store, manage, and deploy account level secrets from a secure, centralized platform to your Workers.
To spin up your Cloudflare Secrets Store, simply click the new Secrets Store tab in the dashboard ↗ or use this Wrangler command:
Terminal window
wranglersecrets-storestorecreate<name>--remote
The following are supported in the Secrets Store beta:
Secrets Store UI & API: create your store & create, duplicate, update, scope, and delete a secret
Workers UI: bind a new or existing account level secret to a Worker and deploy in code
Wrangler: create your store & create, duplicate, update, scope, and delete a secret
Account Management UI & API: assign Secrets Store permissions roles & view audit logs for actions taken in Secrets Store core platform
Cloudflare Zero Trust SCIM provisioning now has a full audit log of all create, update and delete event from any SCIM Enabled IdP. The SCIM logs support filtering by IdP, Event type, Result and many more fields. This will help with debugging user and group update issues and questions.
SCIM logs can be found on the Zero Trust Dashboard under Logs -> SCIM provisioning.
The Overview tab shows logs from all your Workers in one place. The Invocations view groups logs together by invocation, which refers to the specific trigger that started the execution of the Worker (i.e. fetch). The Events view shows logs in the order they were produced, based on timestamp. Previously, you could only view logs for a single Worker.
The Investigate tab presents a Query Builder, which helps you write structured queries to investigate and visualize your logs. The Query Builder can help answer questions such as:
Which paths are experiencing the most 5XX errors?
What is the wall time distribution by status code for my Worker?
What are the slowest requests, and where are they coming from?
Who are my top N users?
The Query Builder can use any field that you store in your logs as a key to visualize, filter, and group by. Use the Query Builder to quickly access your data, build visualizations, save queries, and share them with your team.
Workers Logs is now Generally Available
Workers Logs is now Generally Available. With a small change to your Wrangler configuration, Workers Logs ingests, indexes, and stores all logs emitted from your Workers for up to 7 days.
We've introduced a number of changes during our beta period, including:
Dashboard enhancements with customizable fields as columns in the Logs view and support for invocation-based grouping
Performance improvements to ensure no adverse impact
The API documents three endpoints: list the keys in the telemetry dataset, run a query, and list the unique values for a key. For more, visit our REST API documentation ↗.
Visit the docs to learn more about the capabilities and methods exposed by the Query Builder. Start using Workers Logs and the Query Builder today by enabling observability for your Workers:
For Workers Logpush, CPU and Wall time are surfaced at the top level of the Workers Trace Events object. All new jobs will have these new fields included by default. Existing jobs need to be updated to include CPU time and Wall time.
You can use a Workers Logs filter to search for logs where Wall time exceeds 100ms.
You can also use the Workers Observability Query Builder ↗ to find the median CPU time and median Wall time for all of your Workers.
This release contains a hotfix for captive portal detection and PF state tables for the 2025.2.600.0 release.
Changes and improvements
Fix to reduce the number of browser tabs opened during captive portal logins.
Improvement to exclude local DNS traffic entries from PF state table to reduce risk of connectivity issues from exceeding table capacity.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
Hyperdrive is now available on the Free plan of Cloudflare Workers, enabling you to build Workers that connect to PostgreSQL or MySQL databases without compromise.
Low-latency access to SQL databases is critical to building full-stack Workers applications. We want you to be able to build on fast, global apps on Workers,
regardless of the tools you use. So we made Hyperdrive available for all, to make it easier to build Workers that connect to PostgreSQL and MySQL.
If you want to learn more about how Hyperdrive works, read the deep dive ↗ on how Hyperdrive can make your database queries up to 4x faster.
Visit the docs to get started with Hyperdrive for PostgreSQL or MySQL.
When you use @cloudflare/vite-plugin, you can use Vite's local development server and build tooling, while ensuring that while developing, your code runs in workerd ↗, the open-source Workers runtime.
This lets you get the best of both worlds for a full-stack app — you can use Hot Module Replacement ↗ from Vite right alongside Durable Objects and other runtime APIs and bindings that are unique to Cloudflare Workers.
You can build any type of application with @cloudflare/vite-plugin, using any rendering mode, from single page applications (SPA) and static sites to server-side rendered (SSR) pages and API routes.
React Router v7 (Remix) is the first full-stack framework to provide full support for Cloudflare Vite plugin, allowing you to use all parts of Cloudflare's developer platform, without additional build steps.
You can also build complete full-stack apps on Workers without a framework — "just use Vite" ↗ and React together, and build a back-end API in the same Worker. Follow our React SPA with an API tutorial to learn how.
Configuration
If you're already using Vite ↗ in your build and development toolchain, you can start using our plugin with minimal changes to your vite.config.ts:
vite.config.ts
import {defineConfig} from "vite";
import {cloudflare} from "@cloudflare/vite-plugin";
Email Workers enables developers to programmatically take action on anything that hits their email inbox. If you're building with Email Workers, you can now test the behavior of an Email Worker script, receiving, replying and sending emails in your local environment using wrangler dev.
Below is an example that shows you how you can receive messages using the email() handler and parse them using postal-mime ↗:
Now when you run npx wrangler dev, wrangler will expose a local /cdn-cgi/handler/email endpoint that you can POST email messages to and trigger your Worker's email() handler:
Local development is a critical part of the development flow, and also works for sending, replying and forwarding emails. See our documentation for more information.
Hyperdrive now supports connecting to MySQL and MySQL-compatible databases, including Amazon RDS and Aurora MySQL, Google Cloud SQL for MySQL, Azure Database for MySQL, PlanetScale and MariaDB.
Hyperdrive makes your regional, MySQL databases fast when connecting from Cloudflare Workers. It eliminates unnecessary network roundtrips during connection setup, pools database connections globally, and can cache query results to provide the fastest possible response times.
Best of all, you can connect using your existing drivers, ORMs, and query builders with Hyperdrive's secure credentials, no code changes required.
import {createConnection} from "mysql2/promise";
exportinterfaceEnv{
HYPERDRIVE:Hyperdrive;
}
exportdefault{
asyncfetch(request,env,ctx):Promise<Response>{
constconnection=awaitcreateConnection({
host:env.HYPERDRIVE.host,
user:env.HYPERDRIVE.user,
password:env.HYPERDRIVE.password,
database:env.HYPERDRIVE.database,
port:env.HYPERDRIVE.port,
disableEval: true,// Required for Workers compatibility
You can now add a Deploy to Cloudflare button to the README of your Git repository containing a Workers application — making it simple for other developers to quickly set up and deploy your project!
The Deploy to Cloudflare button:
Creates a new Git repository on your GitHub/ GitLab account: Cloudflare will automatically clone and create a new repository on your account, so you can continue developing.
Automatically provisions resources the app needs: If your repository requires Cloudflare primitives like a Workers KV namespace, a D1 database, or an R2 bucket, Cloudflare will automatically provision them on your account and bind them to your Worker upon deployment.
Configures Workers Builds (CI/CD): Every new push to your production branch on your newly created repository will automatically build and deploy courtesy of Workers Builds.
To create a Deploy to Cloudflare button in your README, you can add the following snippet, including your Git repository URL:
[](https://deploy.workers.cloudflare.com/?url=<YOUR_GIT_REPO_URL>)
Check out our documentation for more information on how to set up a deploy button for your application and best practices to ensure a successful deployment for other developers.
The Agents SDK now includes built-in support for building remote MCP (Model Context Protocol) servers directly as part of your Agent. This allows you to easily create and manage MCP servers, without the need for additional infrastructure or configuration.
The SDK includes a new MCPAgent class that extends the Agent class and allows you to expose resources and tools over the MCP protocol, as well as authorization and authentication to enable remote MCP servers.
See the example ↗ for the full code and as the basis for building your own MCP servers, and the client example ↗ for how to build an Agent that acts as an MCP client.
To learn more, review the announcement blog ↗ as part of Developer Week 2025.
Agents SDK updates
We've made a number of improvements to the Agents SDK, including:
Support for building MCP servers with the new MCPAgent class.
The ability to export the current agent, request and WebSocket connection context using import { context } from "agents", allowing you to minimize or avoid direct dependency injection when calling tools.
Fixed a bug that prevented query parameters from being sent to the Agent server from the useAgent React hook.
Automatically converting the agent name in useAgent or useAgentChat to kebab-case to ensure it matches the naming convention expected by routeAgentRequest.
To install or update the Agents SDK, run npm i agents@latest in an existing project, or explore the agents-starter project:
Workflows is now Generally Available (or "GA"): in short, it's ready for production workloads. Alongside marking Workflows as GA, we've introduced a number of changes during the beta period, including:
A new waitForEvent API that allows a Workflow to wait for an event to occur before continuing execution.
Improved observability, including new CPU time metrics that allow you to better understand which Workflow instances are consuming the most resources and/or contributing to your bill.
Support for vitest for testing Workflows locally and in CI/CD pipelines.
Workflows also supports the new increased CPU limits that apply to Workers, allowing you to run more CPU-intensive tasks (up to 5 minutes of CPU time per instance), not including the time spent waiting on network calls, AI models, or other I/O bound tasks.
Human-in-the-loop
The new step.waitForEvent API allows a Workflow instance to wait on events and data, enabling human-in-the-the-loop interactions, such as approving or rejecting a request, directly handling webhooks from other systems, or pushing event data to a Workflow while it's running.
Because Workflows are just code, you can conditionally execute code based on the result of a waitForEvent call, and/or call waitForEvent multiple times in a single Workflow based on what the Workflow needs.
For example, if you wanted to implement a human-in-the-loop approval process, you could use waitForEvent to wait for a user to approve or reject a request, and then conditionally execute code based on the result.
AutoRAG is now in open beta, making it easy for you to build fully-managed retrieval-augmented generation (RAG) pipelines without managing infrastructure. Just upload your docs to R2, and AutoRAG handles the rest: embeddings, indexing, retrieval, and response generation via API.
With AutoRAG, you can:
Customize your pipeline: Choose from Workers AI models, configure chunking strategies, edit system prompts, and more.
Instant setup: AutoRAG provisions everything you need from Vectorize, AI gateway, to pipeline logic for you, so you can go from zero to a working RAG pipeline in seconds.
Keep your index fresh: AutoRAG continuously syncs your index with your data source to ensure responses stay accurate and up to date.
Ask questions: Query your data and receive grounded responses via a Workers binding or API.
Whether you're building internal tools, AI-powered search, or a support assistant, AutoRAG gets you from idea to deployment in minutes.
Get started in the Cloudflare dashboard ↗ or check out the guide for instructions on how to build your RAG pipeline today.
We’re excited to announce Browser Rendering is now available on the Workers Free plan ↗, making it even easier to prototype and experiment with web search and headless browser use-cases when building applications on Workers.
The Browser Rendering REST API is now Generally Available, allowing you to control browser instances from outside of Workers applications. We've added three new endpoints to help automate more browser tasks:
Extract structured data – Use /json to retrieve structured data from a webpage.
Retrieve links – Use /links to pull all links from a webpage.
Convert to Markdown – Use /markdown to convert webpage content into Markdown format.
For example, to fetch the Markdown representation of a webpage:
We also recently landed support for Playwright in Browser Rendering for browser automation from Cloudflare Workers, in addition to Puppeteer, giving you more flexibility to test across different browser environments.
Visit the Browser Rendering docs to learn more about how to use headless browsers in your applications.
SQLite in Durable Objects is now generally available (GA) with 10GB SQLite database per Durable Object. Since the public beta ↗ in September 2024, we've added feature parity and robustness for the SQLite storage backend compared to the preexisting key-value (KV) storage backend for Durable Objects.
SQLite-backed Durable Objects are recommended for all new Durable Object classes, using new_sqlite_classesWrangler configuration. Only SQLite-backed Durable Objects have access to Storage API's SQL and point-in-time recovery methods, which provide relational data modeling, SQL querying, and better data management.
exportclassMyDurableObjectextendsDurableObject{
sql:SqlStorage
constructor(ctx:DurableObjectState,env:Env){
super(ctx,env);
this.sql=ctx.storage.sql;
}
asyncsayHello(){
letresult=this.sql
.exec("SELECT 'Hello, World!' AS greeting")
.one();
returnresult.greeting;
}
}
KV-backed Durable Objects remain for backwards compatibility, and a migration path from key-value storage to SQL storage for existing Durable Object classes will be offered in the future.
Durable Objects can now be used with zero commitment on the Workers Free plan allowing you to build AI agents with Agents SDK, collaboration tools, and real-time applications like chat or multiplayer games.
Durable Objects let you build stateful, serverless applications with millions of tiny coordination instances that run your application code alongside (in the same thread!) your durable storage. Each Durable Object can access its own SQLite database through a Storage API. A Durable Object class is defined in a Worker script encapsulating the Durable Object's behavior when accessed from a Worker. To try the code below, click the button:
import {DurableObject} from "cloudflare:workers";
// Durable Object
exportclassMyDurableObjectextendsDurableObject{
...
asyncsayHello(name){
return`Hello, ${name}!`;
}
}
// Worker
exportdefault{
asyncfetch(request,env){
// Every unique ID refers to an individual instance of the Durable Object class
constid=env.MY_DURABLE_OBJECT.idFromName("foo");
// A stub is a client used to invoke methods on the Durable Object
conststub=env.MY_DURABLE_OBJECT.get(id);
// Methods on the Durable Object are invoked via the stub
constresponse=awaitstub.sayHello("world");
returnresponse;
},
};
Free plan limits apply to Durable Objects compute and storage usage. Limits allow developers to build real-world applications, with every Worker request able to call a Durable Object on the free plan.
You can now capture a maximum of 256 KB of log events per Workers invocation, helping you gain better visibility into application behavior.
All console.log() statements, exceptions, request metadata, and headers are automatically captured during the Worker invocation and emitted
as JSON object. Workers Logs deserializes
this object before indexing the fields and storing them. You can also capture, transform, and export the JSON object in a
Tail Worker.
256 KB is a 2x increase from the previous 128 KB limit. After you exceed this limit, further context associated with the request will not be
recorded in your logs.
This limit is automatically applied to all Workers.
We're excited to share that you can now use Playwright's browser automation capabilities ↗ from Cloudflare Workers.
Playwright ↗ is an open-source package developed by Microsoft that can do browser automation tasks; it's commonly used to write software tests, debug applications, create screenshots, and crawl pages. Like Puppeteer, we forked ↗ Playwright and modified it to be compatible with Cloudflare Workers and Browser Rendering ↗.
Below is an example of how to use Playwright with Browser Rendering to test a TODO application using assertions:
Assertion example
import {launch, type BrowserWorker} from '@cloudflare/playwright';
import {expect} from '@cloudflare/playwright/test';
You can now access all Cloudflare cache purge methods — no matter which plan you’re on. Whether you need to update a single asset or instantly invalidate large portions of your site’s content, you now have the same powerful tools previously reserved for Enterprise customers.
Anyone on Cloudflare can now:
Purge Everything: Clears all cached content associated with a website.
Purge by Tag: Uses Cache-Tag response headers to invalidate grouped assets, offering flexibility for complex cache management scenarios.
Want to learn how each purge method works, when to use them, or what limits apply to your plan? Dive into our purge cache documentation and API reference ↗ for all the details.
This release contains support for a new WARP setting, Global WARP override. It also includes significant improvements to our captive portal / public Wi-Fi detection logic. If you have experienced captive portal issues in the past, re-test and give this version a try.
Changes and improvements
Improved captive portal detection to make more public networks compatible and have faster detection.
Improved error messages shown in the app.
WARP tunnel protocol details can now be viewed using the warp-cli tunnel stats command.
Fixed an issue with device revocation and re-registration when switching configurations.
Added a new Global WARP override setting. This setting puts account administrators in control of disabling and enabling WARP across all devices registered to an account from the dashboard. Global WARP override is disabled by default.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.3 or later.
This release contains support for a new WARP setting, Global WARP override. It also includes significant improvements to our captive portal / public Wi-Fi detection logic. If you have experienced captive portal issues in the past, re-test and give this version a try.
Changes and improvements
Improved captive portal detection to make more public networks compatible and have faster detection.
Removed DNS logs view from the Windows client GUI. DNS logs can be viewed as part of warp-diag or by viewing the log file on the user's local directory.
Fixed an issue that would result in a user receiving multiple re-authentication requests when waking their device from sleep.
WARP tunnel protocol details can now be viewed using the warp-cli tunnel stats command.
Improvements to Windows multi-user including support for fast user switching. If you are interested in testing this feature, reach out to your Cloudflare account team.
Fixed an issue with device revocation and re-registration when switching configurations.
Fixed an issue where DEX tests would run during certain sleep states where the networking stack was not fully up. This would result in failures that would be ignored.
Added a new Global WARP override setting. This setting puts account administrators in control of disabling and enabling WARP across all devices registered to an account from the dashboard. Global WARP override is disabled by default.
Known issues
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
This release contains support for a new WARP setting, Global WARP override. It also includes significant improvements to our captive portal / public Wi-Fi detection logic. If you have experienced captive portal issues in the past, re-test and give this version a try.
Changes and improvements
Improved captive portal detection to make more public networks compatible and have faster detection.
WARP tunnel protocol details can now be viewed using the warp-cli tunnel stats command.
Fixed an issue with device revocation and re-registration when switching configurations.
Added a new Global WARP override setting. This setting puts account administrators in control of disabling and enabling WARP across all devices registered to an account from the dashboard. Global WARP override is disabled by default.
Queues now supports the ability to pause message delivery and/or purge (delete) messages on a queue. These operations can be useful when:
Your consumer has a bug or downtime, and you want to temporarily stop messages from being processed while you fix the bug
You have pushed invalid messages to a queue due to a code change during development, and you want to clean up the backlog
Your queue has a backlog that is stale and you want to clean it up to allow new messages to be consumed
To pause a queue using Wrangler, run the pause-delivery command. Paused queues continue to receive messages. And you can easily unpause a queue using the resume-delivery command.
Pause and resume a queue
$wranglerqueuespause-deliverymy-queue
Pausingmessagedeliveryforqueuemy-queue.
Pausedmessagedeliveryforqueuemy-queue.
$wranglerqueuesresume-deliverymy-queue
Resumingmessagedeliveryforqueuemy-queue.
Resumedmessagedeliveryforqueuemy-queue.
Purging a queue permanently deletes all messages in the queue. Unlike pausing, purging is an irreversible operation:
The latest version of audit logs streamlines audit logging by automatically capturing all user and system actions performed through the Cloudflare Dashboard or public APIs. This update leverages Cloudflare’s existing API Shield to generate audit logs based on OpenAPI schemas, ensuring a more consistent and automated logging process.
Availability: Audit logs (version 2) is now in Beta, with support limited to API access.
Use the following API endpoint to retrieve audit logs:
You can access detailed documentation for audit logs (version 2) Beta API release here ↗.
Key Improvements in the Beta Release:
Automated & standardized logging: Logs are now generated automatically using a standardized system, replacing manual, team-dependent logging. This ensures consistency across all Cloudflare services.
Expanded product coverage: Increased audit log coverage from 75% to 95%. Key API endpoints such as /accounts, /zones, and /organizations are now included.
Granular filtering: Logs now follow a uniform format, enabling precise filtering by actions, users, methods, and resources—allowing for faster and more efficient investigations.
Enhanced context and traceability: Each log entry now includes detailed context, such as the authentication method used, the interface (API or Dashboard) through which the action was performed, and mappings to Cloudflare Ray IDs for better traceability.
Comprehensive activity capture: Expanded logging to include GET requests and failed attempts, ensuring that all critical activities are recorded.
Known Limitations in Beta
Error handling for the API is not implemented.
There may be gaps or missing entries in the available audit logs.
UI is unavailable in this Beta release.
System-level logs and User-Activity logs are not included.
Support for these features is coming as part of the GA release later this year. For more details, including a sample audit log, check out our blog post: Introducing Automatic Audit Logs ↗
Cloudflare Registrar now supports .ai and .shop domains. These are two of our most highly-requested top-level domains (TLDs) and are great additions to the 300+ other TLDs we support ↗.
Starting today, customers can:
Register and renew these domains at cost without any markups or add-on fees
Enjoy best-in-class security and performance with native integrations with Cloudflare DNS, CDN, and SSL services like one-click DNSSEC
We can't wait to see what AI and e-commerce projects you deploy on Cloudflare. To get started, transfer your domains to Cloudflare or search for new ones to register ↗.
You can now run a Worker for up to 5 minutes of CPU time for each request.
Previously, each Workers request ran for a maximum of 30 seconds of CPU time — that is the time that a Worker is actually performing a task (we still allowed unlimited wall-clock time, in case you were waiting on slow resources). This
meant that some compute-intensive tasks were impossible to do with a Worker. For instance,
you might want to take the cryptographic hash of a large file from R2. If
this computation ran for over 30 seconds, the Worker request would have timed out.
By default, Workers are still limited to 30 seconds of CPU time. This protects developers
from incurring accidental cost due to buggy code.
By changing the cpu_ms value in your Wrangler configuration, you can opt in to
any value up to 300,000 (5 minutes).
Recently, Account Home has been updated to streamline your workflows:
Recent Workers projects: You'll now find your projects readily accessible from a new Developer Platform tab on Account Home. See recently-modified projects and explore what you can work our developer-focused products.
Traffic and security insights: Get a snapshot of domain performance at a glance with key metrics and trends.
Quick actions: You can now perform common actions for your account, domains, and even Workers in just 1-2 clicks from the 3-dot menu.
Keep starred domains front and center: Now, when you filter for starred domains on Account Home, we'll save your preference so you'll continue to only see starred domains by default.
We can't wait for you to take the new Account Home for a spin.
Source maps are now Generally Available (GA). You can now be uploaded with a maximum gzipped size of 15 MB.
Previously, the maximum size limit was 15 MB uncompressed.
Source maps help map between the original source code and the transformed/minified code that gets deployed
to production. By uploading your source map, you allow Cloudflare to map the stack trace from exceptions
onto the original source code making it easier to debug.
With no source maps uploaded: notice how all the Javascript has been minified to one file, so the stack trace is missing information on file name, shows incorrect line numbers, and incorrectly references js instead of ts.
With source maps uploaded: all methods reference the correct files and line numbers.
Uploading source maps and stack trace remapping happens out of band from the Worker execution,
so source maps do not affect upload speed, bundle size, or cold starts. The remapped stack
traces are accessible through Tail Workers, Workers Logs, and Workers Logpush.
To enable source maps, add the following to your
Pages Function's or Worker's wrangler configuration:
Update: Mon Mar 24th, 11PM UTC: Next.js has made further changes to address a smaller vulnerability introduced in the patches made to its middleware handling. Users should upgrade to Next.js versions 15.2.4, 14.2.26, 13.5.10 or 12.3.6. If you are unable to immediately upgrade or are running an older version of Next.js, you can enable the WAF rule described in this changelog as a mitigation.
Update: Mon Mar 24th, 8PM UTC: Next.js has now backported the patch for this vulnerability ↗ to cover Next.js v12 and v13. Users on those versions will need to patch to 13.5.9 and 12.3.5 (respectively) to mitigate the vulnerability.
Update: Sat Mar 22nd, 4PM UTC: We have changed this WAF rule to opt-in only, as sites that use auth middleware with third-party auth vendors were observing failing requests.
We strongly recommend updating your version of Next.js (if eligible) to the patched versions, as your app will otherwise be vulnerable to an authentication bypass attack regardless of auth provider.
Enable the Managed Rule (strongly recommended)
This rule is opt-in only for sites on the Pro plan or above in the WAF managed ruleset.
To enable the rule:
Head to Security > WAF > Managed rules in the Cloudflare dashboard for the zone (website) you want to protect.
Click the three dots next to Cloudflare Managed Ruleset and choose Edit
Scroll down and choose Browse Rules
Search for CVE-2025-29927 (ruleId: 34583778093748cc83ff7b38f472013e)
Change the Status to Enabled and the Action to Block. You can optionally set the rule to Log, to validate potential impact before enabling it. Log will not block requests.
Click Next
Scroll down and choose Save
This will enable the WAF rule and block requests with the x-middleware-subrequest header regardless of Next.js version.
Create a WAF rule (manual)
For users on the Free plan, or who want to define a more specific rule, you can create a Custom WAF rule to block requests with the x-middleware-subrequest header regardless of Next.js version.
To create a custom rule:
Head to Security > WAF > Custom rules in the Cloudflare dashboard for the zone (website) you want to protect.
Give the rule a name - e.g. next-js-CVE-2025-29927
Set the matching parameters for the rule match any request where the x-middleware-subrequest header exists per the rule expression below.
Set the action to 'block'. If you want to observe the impact before blocking requests, set the action to 'log' (and edit the rule later).
Deploy the rule.
Next.js CVE-2025-29927
We've made a WAF (Web Application Firewall) rule available to all sites on Cloudflare to protect against the Next.js authentication bypass vulnerability ↗ (CVE-2025-29927) published on March 21st, 2025.
Note: This rule is not enabled by default as it blocked requests across sites for specific authentication middleware.
This managed rule protects sites using Next.js on Workers and Pages, as well as sites using Cloudflare to protect Next.js applications hosted elsewhere.
This rule has been made available (but not enabled by default) to all sites as part of our WAF Managed Ruleset and blocks requests that attempt to bypass authentication in Next.js applications.
The vulnerability affects almost all Next.js versions, and has been fully patched in Next.js 14.2.26 and 15.2.4. Earlier, interim releases did not fully patch this vulnerability.
Users on older versions of Next.js (11.1.4 to 13.5.6) did not originally have a patch available, but this the patch for this vulnerability and a subsequent additional patch have been backported to Next.js versions 12.3.6 and 13.5.10 as of Monday, March 24th. Users on Next.js v11 will need to deploy the stated workaround or enable the WAF rule.
The managed WAF rule mitigates this by blocking external user requests with the x-middleware-subrequest header regardless of Next.js version, but we recommend users using Next.js 14 and 15 upgrade to the patched versions of Next.js as an additional mitigation.
Smart Placement is a unique Cloudflare feature that can make decisions to move your Worker to run in a more optimal location (such as closer to a database). Instead of always running in the default location (the one closest to where the request is received), Smart Placement uses certain “heuristics” (rules and thresholds) to decide if a different location might be faster or more efficient.
Previously, if these heuristics weren't consistently met, your Worker would revert to running in the default location—even after it had been optimally placed. This meant that if your Worker received minimal traffic for a period of time, the system would reset to the default location, rather than remaining in the optimal one.
Now, once Smart Placement has identified and assigned an optimal location, temporarily dropping below the heuristic thresholds will not force a return to default locations. For example in the previous algorithm, a drop in requests for a few days might return to default locations and heuristics would have to be met again. This was problematic for workloads that made requests to a geographically located resource every few days or longer. In this scenario, your Worker would never get placed optimally. This is no longer the case.
We're excited to introduce the Cloudflare Zero Trust Secure DNS Locations Write role, designed to provide DNS filtering customers with granular control over third-party access when configuring their Protective DNS (PDNS) solutions.
Many DNS filtering customers rely on external service partners to manage their DNS location endpoints. This role allows you to grant access to external parties to administer DNS locations without overprovisioning their permissions.
Require source network filtering for IPv4/IPv6/DoT endpoints; token authentication or source network filtering for the DoH endpoint.
You can assign the new role via Cloudflare Dashboard (Manage Accounts > Members) or via API. For more information, refer to the Secure DNS Locations documentation ↗.
This new capability allows developers to establish persistent, low-latency connections between their applications and AI models, enabling natural, real-time conversational AI experiences, including speech-to-speech interactions.
In Cloudflare Terraform Provider ↗ versions 5.2.0 and above, dozens of resources now have proper drift detection. Before this fix, these resources would indicate they needed to be updated or replaced — even if there was no real change. Now, you can rely on your terraform plan to only show what resources are expected to change.
This issue affected resources ↗ related to these products and features:
In the Cloudflare Terraform Provider ↗ versions 5.2.0 and above, sensitive properties of resources are redacted in logs. Sensitive properties in Cloudflare's OpenAPI Schema ↗ are now annotated with x-sensitive: true. This results in proper auto-generation of the corresponding Terraform resources, and prevents sensitive values from being shown when you run Terraform commands.
This issue affected resources ↗ related to these products and features:
Document conversion plays an important role when designing and developing AI applications and agents. Workers AI now provides the toMarkdown utility method that developers can use to for quick, easy, and convenient conversion and summary of documents in multiple formats to Markdown language.
You can call this new tool using a binding by calling env.AI.toMarkdown() or the using the REST API endpoint.
In this example, we fetch a PDF document and an image from R2 and feed them both to env.AI.toMarkdown(). The result is a list of converted documents. Workers AI models are used automatically to detect and summarize the image.
"data":"# somatosensory.pdf\n## Metadata\n- PDFFormatVersion=1.4\n- IsLinearized=false\n- IsAcroFormPresent=false\n- IsXFAPresent=false\n- IsCollectionPresent=false\n- IsSignaturesPresent=false\n- Producer=Prince 20150210 (www.princexml.com)\n- Title=Anatomy of the Somatosensory System\n\n## Contents\n### Page 1\nThis is a sample document to showcase..."
},
{
"name":"cat.jpeg",
"mimeType":"image/jpeg",
"format":"markdown",
"tokens":0,
"data":"The image is a close-up photograph of Grumpy Cat, a cat with a distinctive grumpy expression and piercing blue eyes. The cat has a brown face with a white stripe down its nose, and its ears are pointed upright. Its fur is light brown and darker around the face, with a pink nose and mouth. The cat's eyes are blue and slanted downward, giving it a perpetually grumpy appearance. The background is blurred, but it appears to be a dark brown color. Overall, the image is a humorous and iconic representation of the popular internet meme character, Grumpy Cat. The cat's facial expression and posture convey a sense of displeasure or annoyance, making it a relatable and entertaining image for many people."
}
]
See Markdown Conversion for more information on supported formats, REST API and pricing.
If you've already been building with the Agents SDK, you can update your dependencies to use the new package name, and replace references to agents-sdk with agents:
Terminal window
# Install the new package
npmiagents
Terminal window
# Remove the old (deprecated) package
npmuninstallagents-sdk
# Find instances of the old package name in your codebase
grep-r'agents-sdk'.
# Replace instances of the old package name with the new one
All future updates will be pushed to the new agents package, and the older package has been marked as deprecated.
Agents SDK updates New
We've added a number of big new features to the Agents SDK over the past few weeks, including:
You can now set cors: true when using routeAgentRequest to return permissive default CORS headers to Agent responses.
The regular client now syncs state on the agent (just like the React version).
useAgentChat bug fixes for passing headers/credentials, including properly clearing cache on unmount.
Experimental /schedule module with a prompt/schema for adding scheduling to your app (with evals!).
Changed the internal zod schema to be compatible with the limitations of Google's Gemini models by removing the discriminated union, allowing you to use Gemini models with the scheduling API.
We've also fixed a number of bugs with state synchronization and the React hooks.
We've added a new @unstable_callable() decorator for defining methods that can be called directly from clients. This allows you call methods from within your client code: you can call methods (with arguments) and get native JavaScript objects back.
returnthis.sql`SELECT * FROM history ORDER BY created_at DESC LIMIT 10`;
}
}
// server.ts
import {unstable_callable,Agent, type StreamingResponse} from "agents";
import type {Env} from "../server";
exportclassRpcextendsAgent<Env>{
// Use the decorator to define a callable method
@unstable_callable({
description:"rpc test",
})
asyncgetHistory(){
returnthis.sql`SELECT * FROM history ORDER BY created_at DESC LIMIT 10`;
}
}
agents-starter Updated
We've fixed a number of small bugs in the agents-starter ↗ project — a real-time, chat-based example application with tool-calling & human-in-the-loop built using the Agents SDK. The starter has also been upgraded to use the latest wrangler v4 release.
If you're new to Agents, you can install and run the agents-starter project in two commands:
You can use the starter as a template for your own Agents projects: open up src/server.ts and src/client.tsx to see how the Agents SDK is used.
More documentation Updated
We've heard your feedback on the Agents SDK documentation, and we're shipping more API reference material and usage examples, including:
Expanded API reference documentation, covering the methods and properties exposed by the Agents SDK, as well as more usage examples.
More Client API documentation that documents useAgent, useAgentChat and the new @unstable_callable RPC decorator exposed by the SDK.
New documentation on how to call agents and (optionally) authenticate clients before they connect to your Agents.
Note that the Agents SDK is continually growing: the type definitions included in the SDK will always include the latest APIs exposed by the agents package.
Radar has expanded its security insights, providing visibility into aggregate trends in authentication requests,
including the detection of leaked credentials through leaked credentials detection scans.
We have now introduced the following endpoints:
summary: Retrieves summaries of HTTP authentication requests distribution across two different dimensions.
timeseries_group: Retrieves timeseries data for HTTP authentication requests distribution across two different dimensions.
The following dimensions are available, displaying the distribution of HTTP authentication requests based on:
compromised: Credential status (clean vs. compromised).
API Shield will scan for risks on your API inventory daily. Here are the new risks we're scanning for and automatically labelling:
cf-risk-sensitive: applied if the customer is subscribed to the sensitive data detection ruleset and the WAF detects sensitive data returned on an endpoint in the last seven days.
cf-risk-missing-auth: applied if the customer has configured a session ID and no successful requests to the endpoint contain the session ID.
cf-risk-mixed-auth: applied if the customer has configured a session ID and some successful requests to the endpoint contain the session ID while some lack the session ID.
cf-risk-missing-schema: added when a learned schema is available for an endpoint that has no active schema.
cf-risk-error-anomaly: added when an endpoint experiences a recent increase in response errors over the last 24 hours.
cf-risk-latency-anomaly: added when an endpoint experiences a recent increase in response latency over the last 24 hours.
cf-risk-size-anomaly: added when an endpoint experiences a spike in response body size over the last 24 hours.
In addition, API Shield has two new 'beta' scans for Broken Object Level Authorization (BOLA) attacks. If you're in the beta, you will see the following two labels when API Shield suspects an endpoint is suffering from a BOLA vulnerability:
cf-risk-bola-enumeration: added when an endpoint experiences successful responses with drastic differences in the number of unique elements requested by different user sessions.
cf-risk-bola-pollution: added when an endpoint experiences successful responses where parameters are found in multiple places in the request.
We are currently accepting more customers into our beta. Contact your account team if you are interested in BOLA attack detection for your API.
Refer to the blog post ↗ for more information about Cloudflare's expanded posture management capabilities.
Workers AI is excited to add 4 new models to the catalog, including 2 brand new classes of models with a text-to-speech and reranker model. Introducing:
@cf/baai/bge-m3 - a multi-lingual embeddings model that supports over 100 languages. It can also simultaneously perform dense retrieval, multi-vector retrieval, and sparse retrieval, with the ability to process inputs of different granularities.
@cf/baai/bge-reranker-base - our first reranker model! Rerankers are a type of text classification model that takes a query and context, and outputs a similarity score between the two. When used in RAG systems, you can use a reranker after the initial vector search to find the most relevant documents to return to a user by reranking the outputs.
@cf/openai/whisper-large-v3-turbo - a faster, more accurate speech-to-text model. This model was added earlier but is graduating out of beta with pricing included today.
@cf/myshell-ai/melotts - our first text-to-speech model that allows users to generate an MP3 with voice audio from inputted text.
// you can use apiClient or LOG_LEVEL, configured before any request is handled
},
};
Additionally, env was normally accessed as a argument to a Worker's entrypoint handler,
such as fetch.
This meant that if you needed to access a binding from a deeply nested function,
you had to pass env as an argument through many functions to get it to the
right spot. This could be cumbersome in complex codebases.
Now, you can access the bindings from anywhere in your codebase
without passing env as an argument:
You can now retry your Cloudflare Pages and Workers builds directly from GitHub. No need to switch to the Cloudflare Dashboard for a simple retry!
Let’s say you push a commit, but your build fails due to a spurious error like a network timeout. Instead of going to the Cloudflare Dashboard to manually retry, you can now rerun the build with just a few clicks inside GitHub, keeping you inside your workflow.
For Pages and Workers projects connected to a GitHub repository:
When a build fails, go to your GitHub repository or pull request
Select the failed Check Run for the build
Select "Details" on the Check Run
Select "Rerun" to trigger a retry build for that commit
A new GA release for the Android Cloudflare One Agent is now available in the Google Play Store ↗. This release includes a new feature allowing team name insertion by URL during enrollment, as well as fixes and minor improvements.
A new GA release for the iOS Cloudflare One Agent is now available in the iOS App Store ↗. This release includes a new feature allowing team name insertion by URL during enrollment, as well as fixes and minor improvements.
This release contains significant improvements to our captive portal / public Wi-Fi detection logic. If you have experienced captive portal issues in the past, re-test and give this version a try.
Changes and improvements
Improved captive portal detection to make more public networks compatible and have faster detection.
Improved error messages shown in the app.
WARP tunnel protocol details can now be viewed using the warp-cli tunnel stats command.
Fixed issue with device revocation and re-registration when switching configurations.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.3 or later.
This release contains significant improvements to our captive portal / public Wi-Fi detection logic. If you have experienced captive portal issues in the past, re-test and give this version a try.
Changes and improvements
Improved captive portal detection to make more public networks compatible and have faster detection.
Removed DNS logs view from the Windows client GUI. DNS logs can be viewed as part of warp-diag or by viewing the log file on the user's local directory.
Fixed issue that would result in a user receiving multiple re-authentication requests when waking their device from sleep.
WARP tunnel protocol details can now be viewed using the warp-cli tunnel stats command.
Improvements to Windows multi-user including support for fast user switching. If you are interested in testing this feature, reach out to your Cloudflare account team.
Fixed issue with device revocation and re-registration when switching configurations.
Fixed issue where DEX tests would run during certain sleep states where the networking stack was not fully up. This would result in failures that would be ignored.
Known issues
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
You can now debug your Workers tests with our Vitest integration by running the following command:
Terminal window
vitest--inspect--no-file-parallelism
Attach a debugger to the port 9229 and you can start stepping through your Workers tests. This is available with @cloudflare/vitest-pool-workers v0.7.5 or later.
We've released the next major version of Wrangler, the CLI for Cloudflare Workers — wrangler@4.0.0. Wrangler v4 is a major release focused on updates to underlying systems and dependencies, along with improvements to keep Wrangler commands consistent and clear.
You can run the following command to install it in your projects:
Unlike previous major versions of Wrangler, which were foundational rewrites ↗ and rearchitectures ↗ — Version 4 of Wrangler includes a much smaller set of changes. If you use Wrangler today, your workflow is very unlikely to change.
Going forward, we'll continue supporting Wrangler v3 with bug fixes and security updates until Q1 2026, and with critical security updates until Q1 2027, at which point it will be out of support.
We’re removing some of the restrictions in Email Routing so that AI Agents and task automation can better handle email workflows, including how Workers can reply to incoming emails.
It's now possible to keep a threaded email conversation with an Email Worker script as long as:
The email can only be replied to once in the same EmailMessage event.
The recipient in the reply must match the incoming sender.
The outgoing sender domain must match the same domain that received the email.
Every time an email passes through Email Routing or another MTA, an entry is added to the References list. We stop accepting replies to emails with more than 100 References entries to prevent abuse or accidental loops.
Here's an example of a Worker responding to Emails using a Workers AI model:
In Node.js, environment variables are exposed via the global process.env object. Some libraries
assume that this object will be populated, and many developers may be used to accessing variables
in this way.
Previously, the process.env object was always empty unless written to in Worker code. This could
cause unexpected errors or friction when developing Workers using code previously written for Node.js.
After April 1, 2025, populating process.env will become the default behavior when both nodejs_compat is enabled and
your Worker's compatibility_date is after "2025-04-01".
Hyperdrive now pools database connections in one or more regions close to your database. This means that your uncached queries and new database connections have up to 90% less latency as measured from connection pools.
By improving placement of Hyperdrive database connection pools, Workers' Smart Placement is now more effective when used with Hyperdrive, ensuring that your Worker can be placed as close to your database as possible.
With this update, Hyperdrive also uses Cloudflare's standard IP address ranges ↗ to connect to your database. This enables you to configure the firewall policies (IP access control lists) of your database to only allow access from Cloudflare and Hyperdrive.
Digital Experience Monitoring (DEX) provides visibility into device, network, and application performance across your Cloudflare SASE deployment. The latest release of the Cloudflare One agent (v2025.1.861) now includes device endpoint monitoring capabilities
to provide deeper visibility into end-user device performance which can be analyzed directly from the dashboard.
Device health metrics are now automatically collected, allowing administrators to:
View the last network a user was connected to
Monitor CPU and RAM utilization on devices
Identify resource-intensive processes running on endpoints
Today, we are thrilled to announce Media Transformations, a new service that
brings the magic of Image Transformations to
short-form video files, wherever they are stored!
For customers with a huge volume of short video — generative AI output,
e-commerce product videos, social media clips, or short marketing content —
uploading those assets to Stream is not always practical. Sometimes, the
greatest friction to getting started was the thought of all that migrating.
Customers want a simpler solution that retains their current storage strategy to
deliver small, optimized MP4 files. Now you can do that with Media
Transformations.
To transform a video or image,
enable transformations for your
zone, then make a simple request with a specially formatted URL. The result is
an MP4 that can be used in an HTML video element without a player library.
If your zone already has Image Transformations enabled, then it is ready to
optimize videos with Media Transformations, too.
For example, we have a short video of the mobile in Austin's office. The
original is nearly 30 megabytes and wider than necessary for this layout.
Consider a simple width adjustment:
The result is less than 3 megabytes, properly sized, and delivered dynamically
so that customers do not have to manage the creation and storage of these
transformed assets.
We’ve streamlined the Logpush setup process by integrating R2 bucket creation directly into the Logpush workflow!
Now, you no longer need to navigate multiple pages to manually create an R2 bucket or copy credentials. With this update, you can seamlessly configure a Logpush job to R2 in just one click, reducing friction and making setup faster and easier.
This enhancement makes it easier for customers to adopt Logpush and R2.
You can now use bucket locks to set retention policies on your R2 buckets (or specific prefixes within your buckets) for a specified period — or indefinitely. This can help ensure compliance by protecting important data from accidental or malicious deletion.
Locks give you a few ways to ensure your objects are retained (not deleted or overwritten). You can:
Lock objects for a specific duration, for example 90 days.
Lock objects until a certain date, for example January 1, 2030.
Lock objects indefinitely, until the lock is explicitly removed.
Buckets can have up to 1,000 bucket lock rules. Each rule specifies which objects it covers (via prefix) and how long those objects must remain retained.
Here are a couple of examples showing how you can configure bucket lock rules using Wrangler:
Ensure all objects in a bucket are retained for at least 180 days
With these enhanced logs, administrators can gain visibility into end user behavior in the remote browser and track blocked data extraction attempts, along with the websites that triggered them, in an isolated session.
{
"AccountID":"$ACCOUNT_ID",
"Decision":"block",
"DomainName":"www.example.com",
"Timestamp":"2025-02-27T23:15:06Z",
"Type":"copy",
"UserID":"$USER_ID"
}
User Actions available:
Copy & Paste
Downloads & Uploads
Printing
Learn more about how to get started with Logpush in our documentation.
Access for SaaS applications now include more configuration options to support a wider array of SaaS applications.
SAML and OIDC Field Additions
OIDC apps now include:
Group Filtering via RegEx
OIDC Claim mapping from an IdP
OIDC token lifetime control
Advanced OIDC auth flows including hybrid and implicit flows
SAML apps now include improved SAML attribute mapping from an IdP.
SAML transformations
SAML identities sent to Access applications can be fully customized using JSONata expressions. This allows admins to configure the precise identity SAML statement sent to a SaaS application.
Unlike previous major versions of Wrangler, which were foundational rewrites ↗ and rearchitectures ↗ — Version 4 of Wrangler includes a much smaller set of changes. If you use Wrangler today, your workflow is very unlikely to change. Before we release Wrangler v4 and advance past the release candidate stage, we'll share a detailed migration guide in the Workers developer docs. But for the vast majority of cases, you won't need to do anything to migrate — things will just work as they do today. We are sharing this release candidate in advance of the official release of v4, so that you can try it out early and share feedback.
New JavaScript language features that you can now use with Wrangler v4
Version 4 of Wrangler updates the version of esbuild ↗ that Wrangler uses internally, allowing you to use modern JavaScript language features, including:
The using keyword from Explicit Resource Management
// user[Symbol.dispose]() is implicitly called at the end of the scope.
}
Import attributes
Import attributes ↗ allow you to denote the type or other attributes of the module that your code imports. For example, you can import a JSON module, using the following syntax:
import data from "./data.json" with { type:"json"};
Other changes
--local is now the default for all CLI commands
All commands that access resources (for example, wrangler kv, wrangler r2, wrangler d1) now access local datastores by default, ensuring consistent behavior.
Clearer policy for the minimum required version of Node.js required to run Wrangler
Moving forward, the active, maintenance, and current versions of Node.js ↗ will be officially supported by Wrangler. This means the minimum officially supported version of Node.js you must have installed for Wrangler v4 will be Node.js v18 or later. This policy mirrors how many other packages and CLIs support older versions of Node.js, and ensures that as long as you are using a version of Node.js that the Node.js project itself supports, this will be supported by Wrangler as well.
Features previously deprecated in Wrangler v3 are now removed in Wrangler v4
All previously deprecated features in Wrangler v2 ↗ and in Wrangler v3 ↗ have now been removed. Additionally, the following features that were deprecated during the Wrangler v3 release have been removed:
Legacy Assets (using wrangler dev/deploy --legacy-assets or the legacy_assets config file property). Instead, we recommend you migrate to Workers assets ↗.
Legacy Node.js compatibility (using wrangler dev/deploy --node-compat or the node_compat config file property). Instead, use the nodejs_compat compatibility flag ↗. This includes the functionality from legacy node_compat polyfills and natively implemented Node.js APIs.
wrangler version. Instead, use wrangler --version to check the current version of Wrangler.
getBindingsProxy() (via import { getBindingsProxy } from "wrangler"). Instead, use the getPlatformProxy() API ↗, which takes exactly the same arguments.
Radar has expanded its DNS insights, providing visibility into aggregated traffic and usage trends observed by our 1.1.1.1 DNS resolver.
In addition to global, location, and ASN traffic trends, we are also providing perspectives on protocol usage, query/response characteristics, and DNSSEC usage.
Previously limited to the top locations and ASes endpoints, we have now introduced the following endpoints:
We've released a new REST API for Browser Rendering in open beta, making interacting with browsers easier than ever. This new API provides endpoints for common browser actions, with more to be added in the future.
With the REST API you can:
Capture screenshots – Use /screenshot to take a screenshot of a webpage from provided URL or HTML.
Generate PDFs – Use /pdf to convert web pages into PDFs.
Extract HTML content – Use /content to retrieve the full HTML from a page.
Snapshot (HTML + Screenshot) – Use /snapshot to capture both the page's HTML and a screenshot in one request
Scrape Web Elements – Use /scrape to extract specific elements from a page.
Workers AI now supports structured JSON outputs with JSON mode, which allows you to request a structured output response when interacting with AI models.
This makes it much easier to retrieve structured data from your AI models, and avoids the (error prone!) need to parse large unstructured text responses to extract your data.
JSON mode in Workers AI is compatible with the OpenAI SDK's structured outputs ↗response_format API, which can be used directly in a Worker:
Workflows now supports up to 4,500 concurrent (running) instances, up from the previous limit of 100. This limit will continue to increase during the Workflows open beta. This increase applies to all users on the Workers Paid plan, and takes effect immediately.
We've released the Agents SDK ↗, a package and set of tools that help you build and ship AI Agents.
You can get up and running with a chat-based AI Agent ↗ (and deploy it to Workers) that uses the Agents SDK, tool calling, and state syncing with a React-based front-end by running the following command:
Super Slurper can now migrate data from any S3-compatible object storage provider to Cloudflare R2. This includes transfers from services like MinIO, Wasabi, Backblaze B2, and DigitalOcean Spaces.
For more information on Super Slurper and how to migrate data from your existing S3-compatible storage buckets to R2, refer to our documentation.
This allows more fine-grained control over transformation request flows and cache behavior. For example, you can resize, manipulate, and overlay images without requiring them to be accessible through a URL.
The Images binding can be configured in the Cloudflare dashboard for your Worker or in the wrangler.toml file in your project's directory:
We've updated the Workers AI text generation models to include context windows and limits definitions and changed our APIs to estimate and validate the number of tokens in the input prompt, not the number of characters.
This update allows developers to use larger context windows when interacting with Workers AI models, which can lead to better and more accurate results.
Our catalog page provides more information about each model's supported context window.
Previously, you could only configure Zaraz by going to each individual zone under your Cloudflare account. Now, if you’d like to get started with Zaraz or manage your existing configuration, you can navigate to the Tag Management ↗ section on the Cloudflare dashboard – this will make it easier to compare and configure the same settings across multiple zones.
These changes will not alter any existing configuration or entitlements for zones you already have Zaraz enabled on. If you’d like to edit existing configurations, you can go to the Tag Setup ↗ section of the dashboard, and select the zone you'd like to edit.
We've updated the Workers AI pricing to include the latest models and how model usage maps to Neurons.
Each model's core input format(s) (tokens, audio seconds, images, etc) now include mappings to Neurons, making it easier to understand how your included Neuron volume is consumed and how you are charged at scale
Per-model pricing, instead of the previous bucket approach, allows us to be more flexible on how models are charged based on their size, performance and capabilities. As we optimize each model, we can then pass on savings for that model.
You will still only pay for what you consume: Workers AI inference is serverless, and not billed by the hour.
Going forward, models will be launched with their associated Neuron costs, and we'll be updating the Workers AI dashboard and API to reflect consumption in both raw units and Neurons. Visit the Workers AI pricing page to learn more about Workers AI pricing.
Small misconfigurations shouldn’t break your deployments. Cloudflare is introducing automatic error detection and fixes in Workers Builds, identifying common issues in your wrangler.toml or wrangler.jsonc and proactively offering fixes, so you spend less time debugging and more time shipping.
Here's how it works:
Before running your build, Cloudflare checks your Worker's Wrangler configuration file (wrangler.toml or wrangler.jsonc) for common errors.
Once you submit a build, if Cloudflare finds an error it can fix, it will submit a pull request to your repository that fixes it.
Once you merge this pull request, Cloudflare will run another build.
We're starting with fixing name mismatches between your Wrangler file and the Cloudflare dashboard, a top cause of build failures.
This is just the beginning, we want your feedback on what other errors we should catch and fix next. Let us know in the Cloudflare Developers Discord, #workers-and-pages-feature-suggestions ↗.
This release contains minor fixes and improvements.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.3 or later. With macOS 15.3, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0.x.
Changes and improvements
Improved command line interface for Access for Infrastructure with added function for filtering and ordering.
Fixed client connectivity issues when switching between managed network profiles that use different WARP protocols.
Improved OS version posture checks on macOS for greater reliability and availability.
Added support for WARP desktop to use additional DoH endpoints to help reduce NAT congestion.
Improved Wireguard connection stability on reconnections.
Added additional HTTP/3 QUIC connectivity test to warp-diag.
Added support for collection of system health metrics for enhanced device Digital Experience Monitoring.
Automated the removal of active registrations for devices with multiple registrations with the same Zero Trust organization.
Fixes issues with deleted registration at start up.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.3 or later.
You can use this prompt with your favorite AI model, including Claude 3.5 Sonnet, OpenAI's o3-mini, Gemini 2.0 Flash, or Llama 3.3 on Workers AI. Models with large context windows will allow you to paste the prompt directly: provide your own prompt within the <user_prompt></user_prompt> tags.
Super Slurper now transfers data from cloud object storage providers like AWS S3 and Google Cloud Storage to Cloudflare R2 up to 5x faster than it did before.
We moved from a centralized service to a distributed system built on the Cloudflare Developer Platform — using Cloudflare Workers, Durable Objects, and Queues — to both improve performance and increase system concurrency capabilities (and we'll share more details about how we did it soon!)
Time to copy 75,000 objects from AWS S3 to R2 decreased from 15 minutes 30 seconds (old) to 3 minutes 25 seconds (after performance improvements)
For more information on Super Slurper and how to migrate data from existing object storage to R2, refer to our documentation.
You can now customize a queue's message retention period, from a minimum of 60 seconds to a maximum of 14 days. Previously, it was fixed to the default of 4 days.
You can customize the retention period on the settings page for your queue, or using Wrangler:
Previously, all viewers watched "the live edge," or the latest content of the
broadcast, synchronously. If a viewer paused for more than a few seconds,
the player would automatically "catch up" when playback started again. Seeking
through the broadcast was only available once the recording was available after
it concluded.
Starting today, customers can make a small adjustment to the player
embed or manifest URL to enable the DVR experience for their viewers. By
offering this feature as an opt-in adjustment, our customers are empowered to
pick the best experiences for their applications.
When building a player embed code or manifest URL, just add dvrEnabled=true as
a query parameter. There are some things to be aware of when using this option.
For more information, refer to DVR for Live.
You can now locally configure your Magic WAN Connector to work in a static IP configuration.
This local method does not require having access to a DHCP Internet connection. However, it does require being comfortable with using tools to access the serial port on Magic WAN Connector as well as using a serial terminal client to access the Connector's environment.
Cloudflare has supported both RSA and ECDSA certificates across our platform for a number of years. Both certificates offer the same security, but ECDSA is more performant due to a smaller key size. However, RSA is more widely adopted and ensures compatibility with legacy clients. Instead of choosing between them, you may want both – that way, ECDSA is used when clients support it, but RSA is available if not.
Now, you can upload both an RSA and ECDSA certificate on a custom hostname via the API.
curl -X POST https://api.cloudflare.com/client/v4/zones/$ZONE_ID/custom_hostnames \
-H 'Content-Type: application/json' \
-H "X-Auth-Email: $CLOUDFLARE_EMAIL" \
-H "X-Auth-Key: $CLOUDFLARE_API_KEY" \
-d '{
"hostname": "hostname",
"ssl": {
"custom_cert_bundle": [
{
"custom_certificate": "RSA Cert",
"custom_key": "RSA Key"
},
{
"custom_certificate": "ECDSA Cert",
"custom_key": "ECDSA Key"
}
],
"bundle_method": "force",
"wildcard": false,
"settings": {
"min_tls_version": "1.0"
}
}
}’
You can also:
Upload an RSA or ECDSA certificate to a custom hostname with an existing ECDSA or RSA certificate, respectively.
Replace the RSA or ECDSA certificate with a certificate of its same type.
Delete the RSA or ECDSA certificate (if the custom hostname has both an RSA and ECDSA uploaded).
This feature is available for Business and Enterprise customers who have purchased custom certificates.
We're introducing Custom Errors (beta), which builds on our existing Custom Error Responses feature with new asset storage capabilities.
This update allows you to store externally hosted error pages on Cloudflare and reference them in custom error rules, eliminating the need to supply inline content.
This brings the following new capabilities:
Custom error assets – Fetch and store external error pages at the edge for use in error responses.
Account-Level custom errors – Define error handling rules and assets at the account level for consistency across multiple zones. Zone-level rules take precedence over account-level ones, and assets are not shared between levels.
You can use Cloudflare API to upload your existing assets for use with Custom Errors:
This release contains only a hotfix from the 2025.1.447.1 release.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.2 or later. With macOS 15.2, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0.x.
Changes and improvements - Improved device registration retrieval for graceful restarts
Known issues - macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.2 or later.
Importing a Git repository: Choose an existing Git repo on your GitHub/GitLab account and set up Workers Builds to deploy your Worker.
Deploying a template with Git: Choose from a brand new selection of production ready examples ↗ to help you get started with popular frameworks like Astro ↗, Remix ↗ and Next ↗ or build stateful applications with Cloudflare resources like D1 databases, Workers AI or Durable Objects! When you're ready to deploy, Cloudflare will set up your project by cloning the template to your GitHub/GitLab account, provisioning any required resources and deploying your Worker.
With every push to your chosen branch, Cloudflare will automatically build and deploy your Worker.
These new features are available today in the Cloudflare dashboard to a subset of Cloudflare customers, and will be coming to all customers in the next few weeks. Don't see it in your dashboard, but want early access? Add your Cloudflare Account ID to this form ↗.
AI Gateway adds additional ways to handle requests - Request Timeouts and Request Retries, making it easier to keep your applications responsive and reliable.
AI Gateway has added three new providers: Cartesia, Cerebras, and ElevenLabs, giving you more even more options for providers you can use through AI Gateway. Here's a brief overview of each:
Cartesia provides text-to-speech models that produce natural-sounding speech with low latency.
Cerebras delivers low-latency AI inference to Meta's Llama 3.1 8B and Llama 3.3 70B models.
ElevenLabs offers text-to-speech models with human-like voices in 32 languages.
To get started with AI Gateway, just update the base URL. Here's how you can send a request to Cerebras using cURL:
You can now implement our child safety tooling, the CSAM Scanning Tool, more easily. Instead of requiring external reporting credentials, you only need a verified email address for notifications to onboard. This change makes the tool more accessible to a wider range of customers.
Radar has expanded its AI insights with new API endpoints for Internet services rankings, robots.txt analysis, and AI inference data.
Internet services ranking
Radar now provides rankings for Internet services, including Generative AI platforms, based on anonymized 1.1.1.1 resolver data.
Previously limited to the annual Year in Review, these insights are now available daily via the API, through the following endpoints:
Radar now analyzes robots.txt files from the top 10,000 domains, identifying AI bot access rules.
AI-focused user agents from ai.robots.txt ↗ are categorized as:
Fully allowed/disallowed if directives apply to all paths (*).
Partially allowed/disallowed if restrictions apply to specific paths.
These insights are now available weekly via the API, through the following endpoints:
Radar now provides insights into public AI inference models from Workers AI, tracking usage trends across models and tasks.
These insights are now available via the API, through the following endpoints:
summary to view aggregated model and task popularity.
Now you can easily compare metrics across Worker versions, understand the current state of a gradual deployment, and review key Workers metrics in a single view. This new interface enables you to:
Drag-and-select using a graphical timepicker for precise metric selection.
Use histograms to visualize cumulative metrics, allowing you to bucket and compare rates over time.
Focus on Worker versions by directly interacting with the version numbers in the legend.
Monitor and compare active gradual deployments.
Track error rates across versions with grouping both by version and by invocation status.
Cloudflare's v5 Terraform Provider is now generally available. With this release, Terraform resources are now automatically generated based on OpenAPI Schemas. This change brings alignment across our SDKs, API documentation, and now Terraform Provider. The new provider boosts coverage by increasing support for API properties to 100%, adding 25% more resources, and more than 200 additional data sources. Going forward, this will also reduce the barriers to bringing more resources into Terraform across the broader Cloudflare API. This is a small, but important step to making more of our platform manageable through GitOps, making it easier for you to manage Cloudflare just like you do your other infrastructure.
Cloudflare is removing five fields from the meta object of DNS records. These fields have been unused for more than a year and are no longer set on new records. This change may take up to four weeks to fully roll out.
The affected fields are:
the auto_added boolean
the managed_by_apps boolean and corresponding apps_install_id
the managed_by_argo_tunnel boolean and corresponding argo_tunnel_id
An example record returned from the API would now look like the following:
Workers for Platforms customers can now attach static assets (HTML, CSS, JavaScript, images) directly to User Workers, removing the need to host separate infrastructure to serve the assets.
This allows your platform to serve entire front-end applications from Cloudflare's global edge, utilizing caching for fast load times, while supporting dynamic logic within the same Worker. Cloudflare automatically scales its infrastructure to handle high traffic volumes, enabling you to focus on building features without managing servers.
What you can build
Static Sites: Host and serve HTML, CSS, JavaScript, and media files directly from Cloudflare's network, ensuring fast loading times worldwide. This is ideal for blogs, landing pages, and documentation sites because static assets can be efficiently cached and delivered closer to the user, reducing latency and enhancing the overall user experience.
Full-Stack Applications: Combine asset hosting with Cloudflare Workers to power dynamic, interactive applications. If you're an e-commerce platform, you can serve your customers' product pages and run inventory checks from within the same Worker.
Get Started:
Upload static assets using the Workers for Platforms API or Wrangler. For more information, visit our Workers for Platforms documentation. ↗
This can be helpful in a variety of situations. For instance, you may have a Worker in front of an origin,
and want to replace an element with content from a different source. Prior to this change, you would have to load
all of the content from the upstream URL and convert it into a string before replacing the element. This slowed
down overall response times.
Now, you can pass the Response object directly into the replace method, and HTMLRewriter will immediately
start replacing the content as it is streamed in. This makes responses faster.
We have released new Workers bindings API methods, allowing you to connect Workers applications to AI Gateway directly. These methods simplify how Workers calls AI services behind your AI Gateway configurations, removing the need to use the REST API and manually authenticate.
Stream's generated captions
leverage Workers AI to automatically transcribe audio and provide captions to
the player experience. We have added support for these languages:
The new Snippets code editor lets you edit Snippet code and rule in one place, making it easier to test and deploy changes without switching between pages.
What’s new:
Single-page editing for code and rule – No need to jump between screens.
Auto-complete & syntax highlighting – Get suggestions and avoid mistakes.
Code formatting & refactoring – Write cleaner, more readable code.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.2 or later. With macOS 15.2, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0.x.
Changes and improvements
Improved command line interface for Access for Infrastructure with added function for filtering and ordering.
Fixed client connectivity issues when switching between managed network profiles that use different WARP protocols.
Improved OS version posture checks on macOS for greater reliability and availability.
Added support for WARP desktop to use additional DoH endpoints to help reduce NAT congestion.
Improved Wireguard connection stability on reconnections.
Added additional HTTP/3 QUIC connectivity test to warp-diag.
Known issues
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.2 or later.
Hyperdrive now automatically configures your Cloudflare Tunnel to connect to your private database.
When creating a Hyperdrive configuration for a private database, you only need to provide your database credentials and set up a Cloudflare Tunnel within the private network where your database is accessible. Hyperdrive will automatically create the Cloudflare Access, Service Token, and Policies needed to secure and restrict your Cloudflare Tunnel to the Hyperdrive configuration.
To create a Hyperdrive for a private database, you can follow the Hyperdrive documentation. You can still manually create the Cloudflare Access, Service Token, and Policies if you prefer.
This feature is available from the Cloudflare dashboard.
You can now have up to 1000 Workers KV namespaces per account.
Workers KV namespace limits were increased from 200 to 1000 for all accounts. Higher limits for Workers KV namespaces enable better organization of key-value data, such as by category, tenant, or environment.
All node:dns functions are available, except lookup, lookupService, and resolve which throw "Not implemented" errors when called.
node:timers
You can use node:timers ↗ to schedule functions to be called at some future period of time.
This includes setTimeout ↗ for calling a function after a delay,
setInterval ↗ for calling a function repeatedly,
and setImmediate ↗ for calling a function in the next iteration of the event loop.
Cloudflare now allows you to send SSH command logs to storage destinations configured in Logpush, including third-party destinations. Once exported, analyze and audit the data as best fits your organization! For a list of available data fields, refer to the SSH logs dataset.
Workflows (beta) now allows you to define up to 1024 steps. sleep steps do not count against this limit.
We've also added:
instanceId as property to the WorkflowEvent type, allowing you to retrieve the current instance ID from within a running Workflow instance
Improved queueing logic for Workflow instances beyond the current maximum concurrent instances, reducing the cases where instances are stuck in the queued state.
Support for pause and resume for Workflow instances in a queued state.
We're continuing to work on increases to the number of concurrent Workflow instances, steps, and support for a new waitForEvent API over the coming weeks.
Users making D1 requests via the Workers API can see up to a 60% end-to-end latency improvement due to the removal of redundant network round trips needed for each request to a D1 database.
p50, p90, and p95 request latency aggregated across entire D1 service. These latencies are a reference point and should not be viewed as your exact workload improvement.
This performance improvement benefits all D1 Worker API traffic, especially cross-region requests where network latency is an outsized latency factor. For example, a user in Europe talking to a database in North America. D1 location hints can be used to influence the geographic location of a database.
For more details on how D1 removed redundant round trips, see the D1 specific release note entry.
AI Gateway now supports DeepSeek, including their cutting-edge DeepSeek-V3 model. With this addition, you have even more flexibility to manage and optimize your AI workloads using AI Gateway. Whether you're leveraging DeepSeek or other providers, like OpenAI, Anthropic, or Workers AI, AI Gateway empowers you to:
Monitor: Gain actionable insights with analytics and logs.
Control: Implement caching, rate limiting, and fallbacks.
Optimize: Improve performance with feedback and evaluations.
To get started, simply update the base URL of your DeepSeek API calls to route through AI Gateway. Here's how you can send a request using cURL:
Workers Builds, the integrated CI/CD system for Workers (currently in beta), now lets you cache artifacts across builds, speeding up build jobs by eliminating repeated work, such as downloading dependencies at the start of each build.
Build Caching: Cache dependencies and build outputs between builds with a shared project-wide cache, ensuring faster builds for the entire team.
Build Watch Paths: Define paths to include or exclude from the build process, ideal for monorepos to target only the files that need to be rebuilt per Workers project.
To get started, select your Worker on the Cloudflare dashboard ↗ then go to Settings > Builds, and connect a GitHub or GitLab repository. Once connected, you'll see options to configure Build Caching and Build Watch Paths.
This release contains improvements to support custom Gateway certificate installation in addition to the changes and improvements included in version 2024.12.492.0.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.2 or later. With macOS 15.2, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0 and 15.1.
Changes and improvements:
Adds support for installing all available custom Gateway certificates from an account to the system store.
Users can now get a list of installed certificates by running warp-cli certs.
Known issues:
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.2 or later.
This release contains improvements to support custom Gateway certificate installation in addition to the changes and improvements included in version 2024.12.492.0.
Changes and improvements:
Adds support for installing all available custom Gateway certificates from an account to the system store.
Users can now get a list of installed certificates by running warp-cli certs.
Known issues:
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
The latest cloudflared build 2024.12.2 ↗ introduces the ability to collect all the diagnostic logs needed to troubleshoot a cloudflared instance.
A diagnostic report collects data from a single instance of cloudflared running on the local machine and outputs it to a cloudflared-diag file.
The cloudflared-diag-YYYY-MM-DDThh-mm-ss.zip archive contains the files listed below. The data in a file either applies to the cloudflared instance being diagnosed (diagnosee) or the instance that triggered the diagnosis (diagnoser). For example, if your tunnel is running in a Docker container, the diagnosee is the Docker instance and the diagnoser is the host instance.
JSON traceroutes to Cloudflare's global network using IPv4 and IPv6
diagnoser
raw-network.txt
Raw traceroutes to Cloudflare's global network using IPv4 and IPv6
diagnoser
systeminformation.json
Operating system information and resource usage
diagnosee
task-result.json
Result of each diagnostic task
diagnoser
tunnelstate.json
Tunnel connections at the time of diagnosis
diagnosee
Footnotes
If the log file is blank, you may need to set --loglevel to debug when you start the tunnel. The --loglevel parameter is only required if you ran the tunnel from the CLI using a cloudflared tunnel run command. It is not necessary if the tunnel runs as a Linux/macOS service or runs in Docker/Kubernetes. ↩
You now have more transparency about team and user submissions for phishing emails through a Reclassification tab in the Zero Trust dashboard.
Reclassifications happen when users or admins submit a phish to Email Security. Cloudflare reviews and - in some cases - reclassifies these emails based on improvements to our machine learning models.
This new tab increases your visibility into this process, allowing you to view what submissions you have made and what the outcomes of those submissions are.
This release contains minor fixes and improvements.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.2 or later. With macOS 15.2, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0 and 15.1.
Changes and improvements:
Consumers can now set the tunnel protocol using warp-cli tunnel protocol set <protocol>.
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Improved captive portal support by disabling the firewall during captive portal login flows.
Improved reliability of connection establishment logic under degraded network conditions.
Improved reconnection speed when a Cloudflare server is in a degraded state.
Improved captive portal detection on certain public networks.
Fixed an issue where admin override displayed an incorrect override end time.
Reduced connectivity interruptions on WireGuard Split Tunnel Include mode configurations.
Fixed connectivity issues switching between managed network profiles with different configured protocols.
QLogs are now disabled by default and can be enabled with warp-cli debug qlog enable. The QLog setting from previous releases will no longer be respected.
Known issues:
macOS Sequoia: Due to changes Apple introduced in macOS 15.0, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.2 or later.
This release includes fixes and minor improvements.
Changes and improvements
Consumers can now set the tunnel protocol using warp-cli tunnel protocol set <protocol>.
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Improved captive portal support by disabling the firewall during captive portal login flows.
Improved reliability of connection establishment logic under degraded network conditions.
Improved reconnection speed when a Cloudflare server is in a degraded state.
Improved captive portal detection on certain public networks.
Reduced connectivity interruptions on WireGuard Split Tunnel Include mode configurations.
Fixed connectivity issues switching between managed network profiles with different configured protocols.
QLogs are now disabled by default and can be enabled with warp-cli debug qlog enable. The QLog setting from previous releases will no longer be respected.
This release contains minor fixes and improvements.
Changes and improvements:
Consumers can now set the tunnel protocol using warp-cli tunnel protocol set <protocol>.
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Improved captive portal support by disabling the firewall during captive portal login flows.
Improved captive portal detection on certain public networks.
Improved reconnection speed when a Cloudflare server is in a degraded state.
Fixed an issue where WARP may fail to remove certificates from the user store in Device Information Only mode.
Ensured at most one Powershell instance is opened when fetching the device serial number for posture checks.
Fixed an issue to prevent the daemon from following Windows junctions created by non-admin users that could be used to delete files as SYSTEM user and potentially gain SYSTEM user privileges.
Improved reliability of connection establishment logic under degraded network conditions.
Fixed an issue that caused high memory usage when viewing connection statistics for extended periods of time.
Improved WARP connectivity in environments with virtual interfaces from VirtualBox, VMware, and similar tools.
Reduced connectivity interruptions on WireGuard Split Tunnel Include mode configurations.
Fixed connectivity issues switching between managed network profiles with different configured protocols.
QLogs are now disabled by default and can be enabled with warp-cli debug qlog enable. The QLog setting from previous releases will no longer be respected.
Known issues:
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
Magic WAN and Magic Transit customers can use the Cloudflare dashboard to configure and manage BGP peering between their networks and their Magic routing table when using a Direct CNI on-ramp.
Using BGP peering with a CNI allows customers to:
Automate the process of adding or removing networks and subnets.
Take advantage of failure detection and session recovery features.
With this functionality, customers can:
Establish an eBGP session between their devices and the Magic WAN / Magic Transit service when connected via CNI.
Secure the session by MD5 authentication to prevent misconfigurations.
Exchange routes dynamically between their devices and their Magic routing table.
This release contains minor fixes and improvements.
Changes and improvements:
Fixed connectivity issues switching between managed network profiles with different configured protocols.
Added support for multiple users on shared Windows 10 and Windows 11 devices. Once a user completes the Windows login, all traffic to Cloudflare will be attributed to the currently active Windows user account. Contact your Customer Success Manager to request participation in this beta.
Known issues:
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
Hyperdrive now caches queries in all Cloudflare locations, decreasing cache hit latency by up to 90%.
When you make a query to your database and Hyperdrive has cached the query results, Hyperdrive will now return the results from the nearest cache. By caching data closer to your users, the latency for cache hits reduces by up to 90%.
This reduction in cache hit latency is reflected in a reduction of the session duration for all queries (cached and uncached) from Cloudflare Workers to Hyperdrive, as illustrated below.
P50, P75, and P90 Hyperdrive session latency for all client connection sessions (both cached and uncached queries) for Hyperdrive configurations with caching enabled during the rollout period.
This performance improvement is applied to all new and existing Hyperdrive configurations that have caching enabled.
For more details on how Hyperdrive performs query caching, refer to the Hyperdrive documentation.
Now, you can manage Cloudflare Snippets with Terraform. Use infrastructure-as-code to deploy and update Snippet code and rules without manual changes in the dashboard.
This release contains minor fixes and improvements.
Changes and improvements:
Consumers can now set the tunnel protocol using "warp-cli tunnel protocol set ".
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Improved captive portal support by disabling the firewall during captive portal login flows.
Improved captive portal detection on certain public networks.
Improved reconnection speed when a Cloudflare server is in a degraded state.
Fixed an issue where WARP may fail to remove certificates from the user store in device information only mode.
Ensured at most one powershell instance is opened when fetching the device serial number for posture checks.
Fixed an issue to prevent the daemon from following Windows junctions created by non-admin users that could be used to delete files as SYSTEM user and potentially gain SYSTEM user privileges.
Improved reliability of connection establishment logic under degraded network conditions.
Fixed an issue that caused high memory usage when viewing connection statistics for extended periods of time.
Improved WARP connectivity in environments with virtual interfaces from VirtualBox, VMware, and similar tools.
Reduced connectivity interruptions on WireGuard include split tunnel configurations.
Known issues:
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, please reconnect the WARP client by toggling off and back on.
This release contains minor fixes and improvements.
Note: If using macOS Sequoia, Cloudflare recommends the use of macOS 15.1 or later. With macOS 15.1, Apple addressed several issues that may have caused the WARP client to not behave as expected when used with macOS 15.0.x.
Changes and improvements:
Consumers can now set the tunnel protocol using warp-cli tunnel protocol set <protocol>.
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Improved captive portal support by disabling the firewall during captive portal login flows.
Improved reliability of connection establishment logic under degraded network conditions.
Improved reconnection speed when a Cloudflare server is in a degraded state.
Improved captive portal detection on certain public networks.
Fixed an issue where admin override displayed an incorrect override end time.
Reduced connectivity interruptions on WireGuard Split Tunnel Include mode configurations.
Known issues:
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.1 or later.
You can now generate customized terraform files for building cloud network on-ramps to Magic WAN.
Magic Cloud can scan and discover existing network resources and generate the required terraform files to automate cloud resource deployment using their existing infrastructure-as-code workflows for cloud automation.
You might want to do this to:
Review the proposed configuration for an on-ramp before deploying it with Cloudflare.
Deploy the on-ramp using your own infrastructure-as-code pipeline instead of deploying it with Cloudflare.
You can now use CASB to find security misconfigurations in your AWS cloud environment using Data Loss Prevention.
You can also connect your AWS compute account to extract and scan your S3 buckets for sensitive data while avoiding egress fees. CASB will scan any objects that exist in the bucket at the time of configuration.
To connect a compute account to your AWS integration:
You can now type in languages that use diacritics (like á or ç) and character-based scripts (such as Chinese, Japanese, and Korean) directly within the remote browser. The isolated browser now properly recognizes non-English keyboard input, eliminating the need to copy and paste content from a local browser or device.
This release contains minor fixes and improvements.
Changes and improvements:
Fixed an issue where SSH sessions and other application connections over TCP or UDP could drop when a device that is using MASQUE changes its primary network interface.
Fixed an issue to ensure the Cloudflare root certificate (or custom certificate) is installed in the trust store if not already there.
Fixed an issue with the WARP client becoming unresponsive during startup.
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably.
Fixed an issue that was preventing proper operation of DNS-over-TLS (DoT) for consumer users.
Known issues:
DNS resolution may be broken when the following conditions are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
This release contains reliability improvements and general bug fixes.
Changes and improvements:
Fixed an issue where SSH sessions and other application connections over TCP or UDP could drop when a device that is using MASQUE changes its primary network interface.
Fixed an issue to ensure the Cloudflare root certificate (or custom certificate) is installed in the trust store if not already there.
Fixed an issue with the WARP client becoming unresponsive during startup.
Extended warp-diag to collect system profiler firewall state as part of diagnostics.
Fixed an issue with the WARP client becoming unresponsive while handling LAN inclusion.
Fixed an issue where users were unable to connect with an IPC error message displayed in the UI.
Fixed an issue that was preventing proper operation of DNS-over-TLS (DoT) for consumer users.
Known issues:
macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.1 or later.
When you set the value to no-store on a subrequest made from a Worker, the Cloudflare Workers runtime will not check whether a match exists in the cache, and not add the response to the cache, even if the response includes directives in the Cache-Control HTTP header that otherwise indicate that the response is cacheable.
This increases compatibility with NPM packages and JavaScript frameworks that rely on setting the cache property, which is a cross-platform standard part of the Request interface. Previously, if you set the cache property on Request, the Workers runtime threw an exception.
If you've tried to use @planetscale/database, redis-js, stytch-node, supabase, axiom-js or have seen the error message The cache field on RequestInitializerDict is not implemented in fetch — you should try again, making sure that the Compatibility Date of your Worker is set to on or after 2024-11-11, or the cache_option_enabled compatibility flag is enabled for your Worker.
This release contains an exciting new feature along with reliability improvements and general bug fixes. Please take time over the next few weeks to play with the new functionality and let us know what you think on both the community forum and through your account teams.
New features:
Added the ability for administrators to initiate remote packet capture (PCAP) and warp-diag collection
Changes and improvements:
Improved reliability of connection establishment logic under degraded network conditions
Improved captive portal detection behavior by forcing captive portal checks outside the tunnel
Allow the ability to configure tunnel protocol for consumer registrations
Fixed an issue with the WARP client becoming unresponsive during startup
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably
Known issues:
DNS resolution may be broken when the following condition are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, please reconnect the WARP client by toggling off and back on.
This release contains an exciting new feature along with reliability improvements and general bug fixes. Please take time over the next few weeks to play with the new functionality and let us know what you think on both the community forum and through your account teams.
New features:
Added the ability for administrators to initiate remote packet capture (PCAP) and warp-diag collection
Changes and improvements:
Improved handling of multiple network interfaces on the system
Improved reliability of connection establishment logic under degraded network conditions
Improved captive portal detection behavior by forcing captive portal checks outside the tunnel
Allow the ability to configure tunnel protocol for consumer registrations
Fixed an issue with the WARP client becoming unresponsive during startup
Extended diagnostics collection time in warp-diag to ensure logs are captured reliably
Extended warp-diag to collect system profiler firewall state as part of diagnostics
Fixed an issue with the Cloudflare WARP GUI showing garbled text in some cases
Fixed an issue with the WARP client becoming unresponsive while handling LAN inclusion
Known issues:
The WARP client may not function correctly on macOS 15.0 (Sequoia). We recommend updating to macOS 15.1 to resolve these issues.
Workflows is now in open beta, and available to any developer a free or paid Workers plan.
Workflows allow you to build multi-step applications that can automatically retry, persist state and run for minutes, hours, days, or weeks. Workflows introduces a programming model that makes it easier to build reliable, long-running tasks, observe as they progress, and programmatically trigger instances based on events across your services.
Get started
You can get started with Workflows by following our get started guide and/or using npm create cloudflare to pull down the starter project:
This release contains minor fixes and improvements.
Changes and improvements:
Fixed an issue where SSH sessions and other application connections over TCP or UDP could be dropped when using MASQUE and the device's primary network interface changed.
Fixed an issue to ensure the managed certificate is installed in the trust store if not already there.
Known issues:
DNS resolution may be broken when the following condition are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, please reconnect the WARP client by toggling off and back on.
This release contains minor fixes and improvements.
Changes and improvements:
Fixed an issue where SSH sessions and other application connections over TCP or UDP could be dropped when using MASQUE and the device’s primary network interface changed.
Fixed an issue to ensure the managed certificate is installed in the trust store if not already there.
Known issues:
Cloudflare is investigating temporary networking issues caused by macOS 15 (Sequoia) changes that seem to affect some users and may be seen with any version of the WARP client.
This release contains minor fixes and improvements.
All customers running macOS Ventura 13.0 and above (including macOS Sequoia) are advised to upgrade to this release. This release fixes an incompatibility with the firewall that may sometimes result in the firewall becoming disabled.
Added the ability to customize PCAP options in the warp-cli.
Added a list of installed applications in warp-diag.
Added a tunnel reset mtu subcommand to the warp-cli.
Added the ability for warp-cli to use the team name provided in the MDM file for initial registration.
Added a JSON output option to the warp-cli.
Added the ability to execute a PCAP on multiple interfaces with warp-cli.
Added MASQUE tunnel protocol support for the consumer version of WARP (1.1.1.1 w/ WARP).
Improved the performance of firewall operations when enforcing split tunnel configuration.
Fixed an issue where device posture certificate checks were unexpectedly failing.
Fixed an issue where the Linux GUI fails to open the browser login window when registering a new Zero Trust organization.
Fixed an issue where clients using service tokens failed to retry after a network change.
Fixed an issue where the client, when switching between WireGuard and MASQUE protocols, sometimes required a manual tunnel key reset.
Fixed a known issue which required users to re-register when an older single configuration MDM file was deployed after deploying the newer, multiple configuration format.
Deprecated warp-cli commands have been removed. If you have any workflows that use the deprecated commands, update to the new commands where necessary.
Known issues:
Using MASQUE as the tunnel protocol may be incompatible if your organization has Regional Services is enabled.
Organizations can now eliminate long-lived credentials from their SSH setup and enable strong multi-factor authentication for SSH access, similar to other Access applications, all while generating access and command logs.
SSH with Access for Infrastructure uses short-lived SSH certificates from Cloudflare, eliminating SSH key management and reducing the security risks associated with lost or stolen keys. It also leverages a common deployment model for Cloudflare One customers: WARP-to-Tunnel.
SSH with Access for Infrastructure enables you to:
Author fine-grained policy to control who may access your SSH servers, including specific ports, protocols, and SSH users.
Monitor infrastructure access with Access and SSH command logs, supporting regulatory compliance and providing visibility in case of security breach.
Preserve your end users' workflows. SSH with Access for Infrastructure supports native SSH clients and does not require any modifications to users’ SSH configs.
This release contains minor fixes and improvements.
Notable updates
Added the ability to customize PCAP options in the warp-cli.
Added a list of installed applications in warp-diag.
Added a summary of warp-dex traceroute results in its JSON output.
Improved the performance of firewall operations when enforcing split tunnel configuration.
Reduced the time it takes for a WARP client update to complete.
Fixed an issue where clients using service tokens failed to retry the initial connection when there is no network connectivity on startup.
Fixed issues where incorrect DNS server addresses were being applied following reboots and network changes. Any incorrect static entries set by previous WARP versions must be manually reverted.
Fixed a known issue which required users to re-register when an older single configuration MDM file was deployed after deploying the newer, multiple configuration format.
Deprecated warp-cli commands have been removed. If you have any workflows that use the deprecated commands, please update to the new commands where necessary.
Known issues
Using MASQUE as the tunnel protocol may be incompatible if your organization has Regional Services enabled.
DNS resolution may be broken when the following condition are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, please reconnect the WARP client by toggling off and back on.
This release contains minor fixes and improvements.
Notable updates:
Added the ability to customize PCAP options in warp-cli.
Added a list of installed applications in warp-diag.
Added a summary of warp-dex traceroute results in its JSON output.
Improved the performance of firewall operations when enforcing Split Tunnels configuration.
Fixed an issue where the DNS logs were not being cleared when the user switched configurations.
Fixed an issue where clients using service tokens failed to retry after a network change.
Fixed a known issue which required users to re-register when an older single configuration MDM file was deployed after deploying the newer, multiple configuration format.
Fixed an issue which prevented the use of private IP ranges that overlapped with end users' home networks.
Deprecated warp-cli commands have been removed. If you have any workflows that use the deprecated commands, update to the new commands where necessary.
Known issues:
Cloudflare is investigating temporary networking issues on macOS 15 (Sequoia) that seem to affect some users.
Using MASQUE as the tunnel protocol may be incompatible if your organization has Regional Services enabled.
This is a release focused on fixes and improvements.
Changes and improvements:
Added the ability to customize PCAP options in the warp-cli.
Added a list of installed applications in warp-diag.
Added a summary of warp-dex traceroute results in its JSON output.
Improved the performance of firewall operations when enforcing split tunnel configuration.
Fixed an issue where the DNS logs were not being cleared when the user switched configurations.
Fixed a Known Issue which required users to re-register when an older single configuration MDM file was deployed after deploying the newer, multiple configuration format.
Fixed an issue which prevented the use of private IP ranges that overlapped with end user's home networks.
Deprecated warp-cli commands have been removed. If you have any workflows that use the deprecated commands, please update to the new commands where necessary.
Known issues:
Using MASQUE as the tunnel protocol may be incompatible if your organization has either of the following conditions:
Magic WAN is enabled but not the latest packet flow path for WARP. Please check the migration status with your account team.
This is a release focused on fixes and improvements.
Changes and improvements:
Added the ability to customize PCAP options in the warp-cli.
Added a list of installed applications in warp-diag.
Added a summary of warp-dex traceroute results in its JSON output.
Improved the performance of firewall operations when enforcing split tunnel configuration.
Reduced time it takes for a WARP client update to complete.
Fixed issues where incorrect DNS server addresses were being applied following reboots and network changes. Any incorrect static entries set by previous WARP versions must be manually reverted.
Fixed a Known Issue which required users to re-register when an older single configuration MDM file was deployed after deploying the newer, multiple configuration format.
Deprecated warp-cli commands have been removed. If you have any workflows that use the deprecated commands, please update to the new commands where necessary.
Known issues:
Using MASQUE as the tunnel protocol may be incompatible if your organization has either of the following conditions:
Magic WAN is enabled but not the latest packet flow path for WARP. Please check migration status with your account team.
Regional Services enabled.
DNS resolution may be broken when the following condition are all true:
WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
A custom DNS server address is configured on the primary network adapter.
The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, please reconnect the WARP client by toggling off and back on.
This release includes some exciting new features. It also includes additional fixes and minor improvements.
New features
The WARP client now supports operation on Ubuntu 24.04.
Admins can now elect to have ZT WARP clients connect using the MASQUE protocol; this setting is in Device Profiles. Note: before MASQUE can be used, the global setting for Override local interface IP must be enabled. For more detail, refer to Device tunnel protocol. This feature will be rolled out to customers in stages over approximately the next month.
The Device Posture client certificate check has been substantially enhanced. The primary enhancement is the ability to check for client certificates that have unique common names, made unique by the inclusion of the device serial number or host name (for example, CN = 123456.mycompany, where 123456 is the device serial number).
TCP MSS clamping is now used where necessary to meet the MTU requirements of the tunnel interface. This will be especially helpful in Docker use cases.
Warning
Ubuntu 16.04 and 18.04 are not supported by this version of the client.
This is the last GA release that will be supporting older, deprecated warp-cli commands. There are two methods to identify these commands. One, when used in this release, the command will work but will also return a deprecation warning. And two, the deprecated commands do not appear in the output of warp-cli -h.
Known issues
There are certain known limitations preventing the use of the MASQUE tunnel protocol in certain scenarios. Do not use the MASQUE tunnel protocol if:
A Magic WAN integration is on the account and does not have the latest packet flow path for WARP traffic. To check the migration status, contact your account team.
Your account has Regional Services enabled.
The Linux client GUI does not yet support all GUI features found in the Windows and macOS clients. Future releases of the Linux client will be adding these GUI features.
The Zero Trust team name is not visible in the GUI if you upgraded from the previous GA release using an MDM tool.
Sometimes the WARP icon will remain gray (disconnected state) while in dark mode.
This release only contains a hotfix from the 2024.6.416.0 release.
Notable updates
Fixed an issue which could cause alternate network detections to fail for hosts using TLS 1.2 which do not support TLS Extended Master Secret (EMS).
Improved the stability of device profile switching based on alternate network detection.
Known issues
If a user has an MDM file configured to support multiple profiles (for the switch configurations feature), and then changes to an MDM file configured for a single profile, the WARP client may not connect. The workaround is to use the warp-cli registration delete command to clear the registration, and then re-register the client.
There are certain known limitations preventing the use of the MASQUE tunnel protocol in certain scenarios. Do not use the MASQUE tunnel protocol if:
A Magic WAN integration is on the account and is not yet migrated to the warp_unified_flow. Please check migration status with your account team.
This release only contains a hotfix from the 2024.6.415.0 release.
Notable updates
Fixed an issue which could cause alternate network detections to fail for hosts using TLS 1.2 which do not support TLS Extended Master Secret (EMS).
Improved the stability of device profile switching based on alternate network detection.
Known issues
If a user has an MDM file configured to support multiple profiles (for the switch configurations feature), and then changes to an MDM file configured for a single profile, the WARP client may not connect. The workaround is to use the warp-cli registration delete command to clear the registration, and then re-register the client.
There are certain known limitations preventing the use of the MASQUE tunnel protocol in certain scenarios. Do not use the MASQUE tunnel protocol if:
A Magic WAN integration is on the account and is not yet migrated to the warp_unified_flow. Please check migration status with your account team.
You can now easily enable Real User Monitoring (RUM) monitoring for your hostnames, while safely dropping requests from visitors in the European Union to comply with GDPR and CCPA.
Our Web Analytics product has always been centered on giving you insights into your users' experience that you need to provide the best quality experience, without sacrificing user privacy in the process.
To help with that aim, you can now selectively enable RUM monitoring for your hostname and exclude EU visitor data in a single click. If you opt for this option, we will drop all metrics collected by our EU data centeres automatically.
You can learn more about what metrics are reported by Web Analytics and how it is collected in the Web Analytics documentation. You can enable Web Analytics on any hostname by going to the Web Analytics ↗ section of the dashboard, selecting "Manage Site" for the hostname you want to monitor, and choosing the appropriate enablement option.