
You can now retrieve up to 100 keys in a single bulk read request made to Workers KV using the binding.
This makes it easier to request multiple KV pairs within a single Worker invocation. Retrieving many key-value pairs using the bulk read operation is more performant than making individual requests since bulk read operations are not affected by Workers simultaneous connection limits.
JavaScript // Read single keyconst key = "key-a";const value = await env.NAMESPACE.get(key);// Read multiple keysconst keys = ["key-a", "key-b", "key-c", ...] // up to 100 keysconst values : Map<string, string?> = await env.NAMESPACE.get(keys);// Print the value of "key-a" to the console.console.log(`The first key is ${values.get("key-a")}.`)Consult the Workers KV Read key-value pairs API for full details on Workers KV's new bulk reads support.
-
Previously, a request to the Workers Create Route API always returned
nullfor "script" and an empty string for "pattern" even if the request was successful.Example request curl https://api.cloudflare.com/client/v4/zones/$CF_ACCOUNT_ID/workers/routes \-X PUT \-H "Authorization: Bearer $CF_API_TOKEN" \-H 'Content-Type: application/json' \--data '{ "pattern": "example.com/*", "script": "hello-world-script" }'Example bad response {"result": {"id": "bf153a27ba2b464bb9f04dcf75de1ef9","pattern": "","script": null,"request_limit_fail_open": false},"success": true,"errors": [],"messages": []}Now, it properly returns all values!
Example good response {"result": {"id": "bf153a27ba2b464bb9f04dcf75de1ef9","pattern": "example.com/*","script": "hello-world-script","request_limit_fail_open": false},"success": true,"errors": [],"messages": []}The Workers and Workers for Platforms secrets APIs are now properly documented in the Cloudflare OpenAPI docs. Previously, these endpoints were not publicly documented, leaving users confused on how to directly manage their secrets via the API. Now, you can find the proper endpoints in our public documentation, as well as in our API Library SDKs such as cloudflare-typescript ↗ (>4.2.0) and cloudflare-python ↗ (>4.1.0).
Note the
cloudflare_workers_secretandcloudflare_workers_for_platforms_script_secretTerraform resources ↗ are being removed in a future release. This resource is not recommended for managing secrets. Users should instead use the:- Secrets Store with the "Secrets Store Secret" binding on Workers and Workers for Platforms Script Upload
- "Secret Text" Binding on Workers Script Upload and Workers for Platforms Script Upload
- Workers (and WFP) Secrets API
You now have access to the World Health Organization (WHO) 2025 edition of the International Classification of Diseases 11th Revision (ICD-11) ↗ as a predefined detection entry. The new dataset can be found in the Health Information predefined profile.
ICD-10 dataset remains available for use.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset 100739A Next.js - Auth Bypass - CVE:CVE-2025-29927 - 2 Log Disabled This is a New Detection
You can now use more flexible redirect capabilities in Cloudflare One with Gateway.
- A new Redirect action is available in the HTTP policy builder, allowing admins to redirect users to any URL when their request matches a policy. You can choose to preserve the original URL and query string, and optionally include policy context via query parameters.
- For Block actions, admins can now configure a custom URL to display when access is denied. This block page redirect is set at the account level and can be overridden in DNS or HTTP policies. Policy context can also be passed along in the URL.
Learn more in our documentation for HTTP Redirect and Block page redirect.
Cloudflare Stream has completed an infrastructure upgrade for our Live WebRTC beta support which brings increased scalability and improved playback performance to all customers. WebRTC allows broadcasting directly from a browser (or supported WHIP client) with ultra-low latency to tens of thousands of concurrent viewers across the globe.
Additionally, as part of this upgrade, the WebRTC beta now supports Signed URLs to protect playback, just like our standard live stream options (HLS/DASH).
For more information, learn about the Stream Live WebRTC beta.
Workers AI for Developer Week - faster inference, new models, async batch API, expanded LoRA support
Happy Developer Week 2025! Workers AI is excited to announce a couple of new features and improvements available today. Check out our blog ↗ for all the announcement details.
We’re rolling out some in-place improvements to our models that can help speed up inference by 2-4x! Users of the models below will enjoy an automatic speed boost starting today:
@cf/meta/llama-3.3-70b-instruct-fp8-fastgets a speed boost of 2-4x, leveraging techniques like speculative decoding, prefix caching, and an updated inference backend.@cf/baai/bge-small-en-v1.5,@cf/baai/bge-base-en-v1.5,@cf/baai/bge-large-en-v1.5get an updated back end, which should improve inference times by 2x.- With the
bgemodels, we’re also announcing a new parameter calledpoolingwhich can takeclsormeanas options. We highly recommend usingpooling: clswhich will help generate more accurate embeddings. However, embeddings generated with cls pooling are not backwards compatible with mean pooling. For this to not be a breaking change, the default remains as mean pooling. Please specifypooling: clsto enjoy more accurate embeddings going forward.
- With the
We’re also excited to launch a few new models in our catalog to help round out your experience with Workers AI. We’ll be deprecating some older models in the future, so stay tuned for a deprecation announcement. Today’s new models include:
@cf/mistralai/mistral-small-3.1-24b-instruct: a 24B parameter model achieving state-of-the-art capabilities comparable to larger models, with support for vision and tool calling.@cf/google/gemma-3-12b-it: well-suited for a variety of text generation and image understanding tasks, including question answering, summarization and reasoning, with a 128K context window, and multilingual support in over 140 languages.@cf/qwen/qwq-32b: a medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.@cf/qwen/qwen2.5-coder-32b-instruct: the current state-of-the-art open-source code LLM, with its coding abilities matching those of GPT-4o.
Introducing a new batch inference feature that allows you to send us an array of requests, which we will fulfill as fast as possible and send them back as an array. This is really helpful for large workloads such as summarization, embeddings, etc. where you don’t have a human-in-the-loop. Using the batch API will guarantee that your requests are fulfilled eventually, rather than erroring out if we don’t have enough capacity at a given time.
Check out the tutorial to get started! Models that support batch inference today include:
@cf/meta/llama-3.3-70b-instruct-fp8-fast@cf/baai/bge-small-en-v1.5@cf/baai/bge-base-en-v1.5@cf/baai/bge-large-en-v1.5@cf/baai/bge-m3@cf/meta/m2m100-1.2b
We’ve upgraded our LoRA experience to include 8 newer models, and can support ranks of up to 32 with a 300MB safetensors file limit (previously limited to rank of 8 and 100MB safetensors) Check out our LoRAs page to get started. Models that support LoRAs now include:
@cf/meta/llama-3.2-11b-vision-instruct@cf/meta/llama-3.3-70b-instruct-fp8-fast@cf/meta/llama-guard-3-8b@cf/meta/llama-3.1-8b-instruct-fast(coming soon)@cf/deepseek-ai/deepseek-r1-distill-qwen-32b(coming soon)@cf/qwen/qwen2.5-coder-32b-instruct@cf/qwen/qwq-32b@cf/mistralai/mistral-small-3.1-24b-instruct@cf/google/gemma-3-12b-it
D1 read replication is available in public beta to help lower average latency and increase overall throughput for read-heavy applications like e-commerce websites or content management tools.
Workers can leverage read-only database copies, called read replicas, by using D1 Sessions API. A session encapsulates all the queries from one logical session for your application. For example, a session may correspond to all queries coming from a particular web browser session. With Sessions API, D1 queries in a session are guaranteed to be sequentially consistent to avoid data consistency pitfalls. D1 bookmarks can be used from a previous session to ensure logical consistency between sessions.
TypeScript // retrieve bookmark from previous session stored in HTTP headerconst bookmark = request.headers.get("x-d1-bookmark") ?? "first-unconstrained";const session = env.DB.withSession(bookmark);const result = await session.prepare(`SELECT * FROM Customers WHERE CompanyName = 'Bs Beverages'`).run();// store bookmark for a future sessionresponse.headers.set("x-d1-bookmark", session.getBookmark() ?? "");Read replicas are automatically created by Cloudflare (currently one in each supported D1 region), are active/inactive based on query traffic, and are transparently routed to by Cloudflare at no additional cost.
To checkout D1 read replication, deploy the following Worker code using Sessions API, which will prompt you to create a D1 database and enable read replication on said database.
To learn more about how read replication was implemented, go to our blog post ↗.
Cloudflare Pipelines is now available in beta, to all users with a Workers Paid plan.
Pipelines let you ingest high volumes of real time data, without managing the underlying infrastructure. A single pipeline can ingest up to 100 MB of data per second, via HTTP or from a Worker. Ingested data is automatically batched, written to output files, and delivered to an R2 bucket in your account. You can use Pipelines to build a data lake of clickstream data, or to store events from a Worker.
Create your first pipeline with a single command:
Create a pipeline $ npx wrangler@latest pipelines create my-clickstream-pipeline --r2-bucket my-bucket🌀 Authorizing R2 bucket "my-bucket"🌀 Creating pipeline named "my-clickstream-pipeline"✅ Successfully created pipeline my-clickstream-pipelineId: 0e00c5ff09b34d018152af98d06f5a1xvcName: my-clickstream-pipelineSources:HTTP:Endpoint: https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/Authentication: offFormat: JSONWorker:Format: JSONDestination:Type: R2Bucket: my-bucketFormat: newline-delimited JSONCompression: GZIPBatch hints:Max bytes: 100 MBMax duration: 300 secondsMax records: 100,000🎉 You can now send data to your pipeline!Send data to your pipeline's HTTP endpoint:curl "https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/" -d '[{ ...JSON_DATA... }]'To send data to your pipeline from a Worker, add the following configuration to your config file:{"pipelines": [{"pipeline": "my-clickstream-pipeline","binding": "PIPELINE"}]}Head over to our getting started guide for an in-depth tutorial to building with Pipelines.
Today, we're launching R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket.
If you're not already familiar with it, Apache Iceberg ↗ is an open table format designed to handle large-scale analytics datasets stored in object storage, offering ACID transactions and schema evolution. R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect engines like Spark, Snowflake, and PyIceberg to start querying your tables using the tools you already know.
To enable a data catalog on your R2 bucket, find R2 Data Catalog in your buckets settings in the dashboard, or run:
Terminal window npx wrangler r2 bucket catalog enable my-bucketAnd that's it. You'll get a catalog URI and warehouse you can plug into your favorite Iceberg engines.
Visit our getting started guide for step-by-step instructions on enabling R2 Data Catalog, creating tables, and running your first queries.
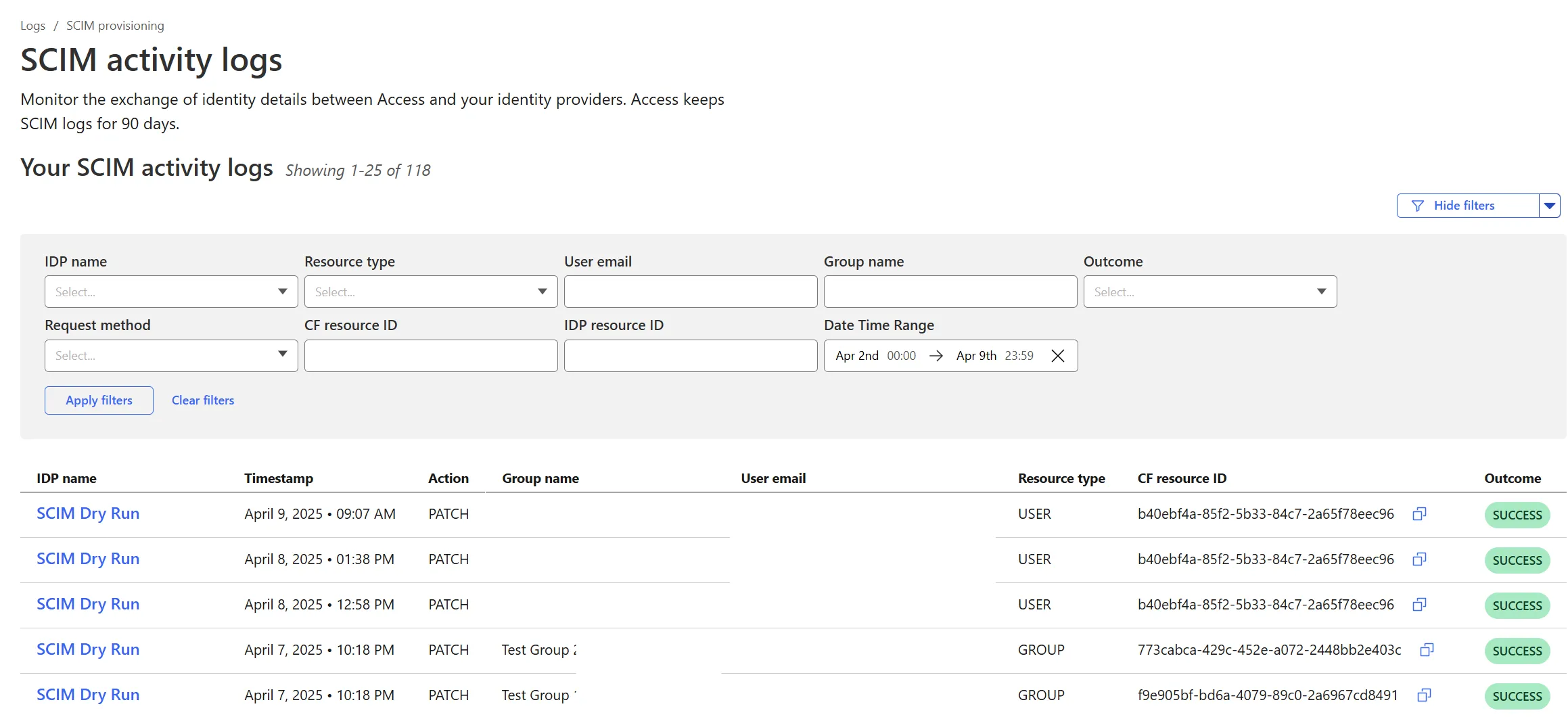
Cloudflare Zero Trust SCIM provisioning now has a full audit log of all create, update and delete event from any SCIM Enabled IdP. The SCIM logs support filtering by IdP, Event type, Result and many more fields. This will help with debugging user and group update issues and questions.
SCIM logs can be found on the Zero Trust Dashboard under Logs -> SCIM provisioning.
Hyperdrive now supports more SSL/TLS security options for your database connections:
- Configure Hyperdrive to verify server certificates with
verify-caorverify-fullSSL modes and protect against man-in-the-middle attacks - Configure Hyperdrive to provide client certificates to the database server to authenticate itself (mTLS) for stronger security beyond username and password
Use the new
wrangler certcommands to create certificate authority (CA) certificate bundles or client certificate pairs:Terminal window # Create CA certificate bundlenpx wrangler cert upload certificate-authority --ca-cert your-ca-cert.pem --name your-custom-ca-name# Create client certificate pairnpx wrangler cert upload mtls-certificate --cert client-cert.pem --key client-key.pem --name your-client-cert-nameThen create a Hyperdrive configuration with the certificates and desired SSL mode:
Terminal window npx wrangler hyperdrive create your-hyperdrive-config \--connection-string="postgres://user:password@hostname:port/database" \--ca-certificate-id <CA_CERT_ID> \--mtls-certificate-id <CLIENT_CERT_ID>--sslmode verify-fullLearn more about configuring SSL/TLS certificates for Hyperdrive to enhance your database security posture.
- Configure Hyperdrive to verify server certificates with

Cloudflare Snippets are now generally available at no extra cost across all paid plans — giving you a fast, flexible way to programmatically control HTTP traffic using lightweight JavaScript.
You can now use Snippets to modify HTTP requests and responses with confidence, reliability, and scale. Snippets are production-ready and deeply integrated with Cloudflare Rules, making them ideal for everything from quick dynamic header rewrites to advanced routing logic.
What's new:
-
Snippets are now GA – Available at no extra cost on all Pro, Business, and Enterprise plans.
-
Ready for production – Snippets deliver a production-grade experience built for scale.
-
Part of the Cloudflare Rules platform – Snippets inherit request modifications from other Cloudflare products and support sequential execution, allowing you to run multiple Snippets on the same request and apply custom modifications step by step.
-
Trace integration – Use Cloudflare Trace to see which Snippets were triggered on a request — helping you understand traffic flow and debug more effectively.
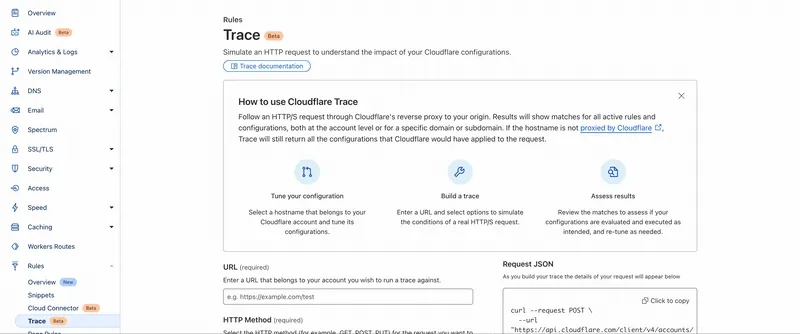
Learn more in the launch blog post ↗.
-
Cloudflare Secrets Store is available today in Beta. You can now store, manage, and deploy account level secrets from a secure, centralized platform to your Workers.
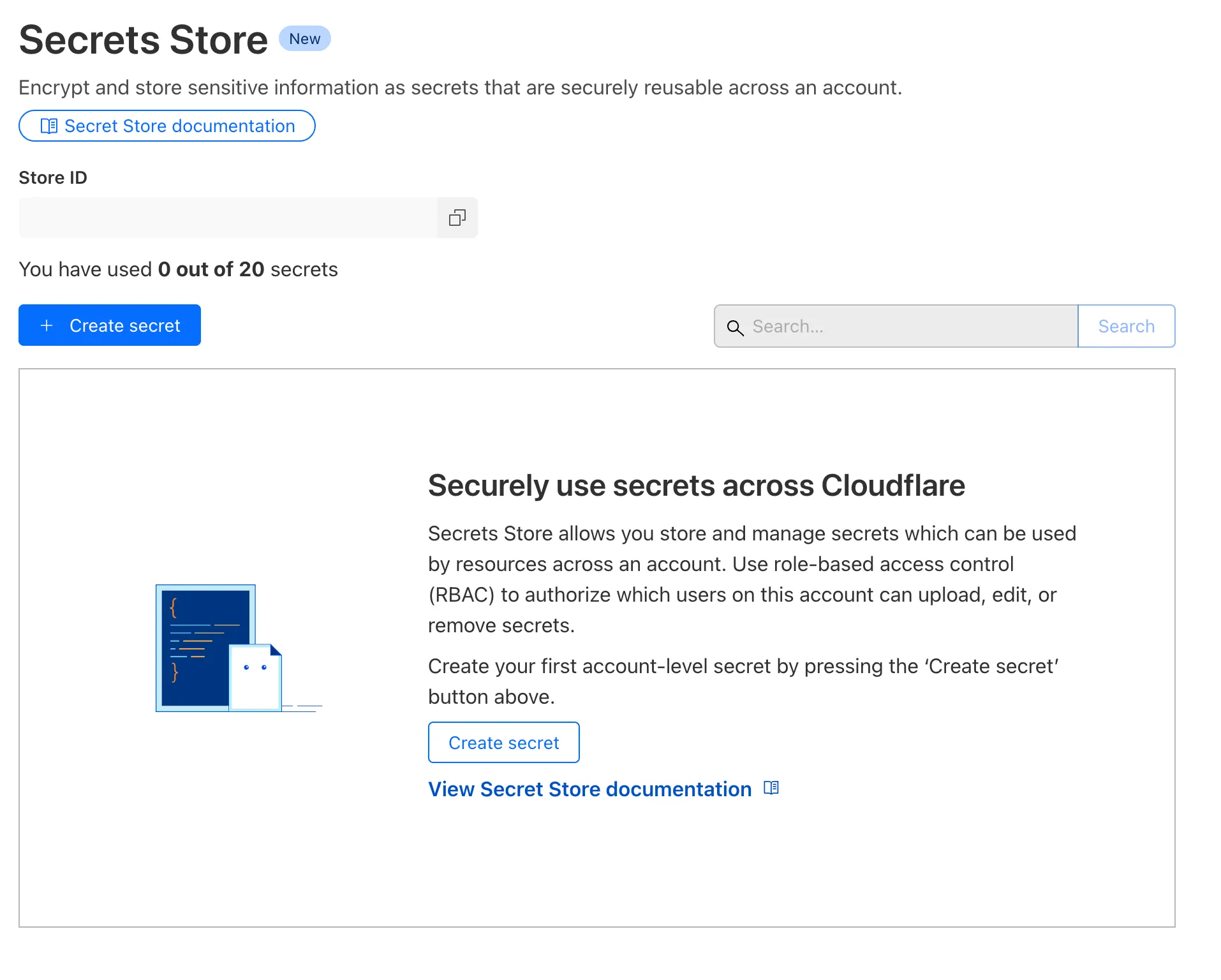
To spin up your Cloudflare Secrets Store, simply click the new Secrets Store tab in the dashboard ↗ or use this Wrangler command:
Terminal window wrangler secrets-store store create <name> --remoteThe following are supported in the Secrets Store beta:
- Secrets Store UI & API: create your store & create, duplicate, update, scope, and delete a secret
- Workers UI: bind a new or existing account level secret to a Worker and deploy in code
- Wrangler: create your store & create, duplicate, update, scope, and delete a secret
- Account Management UI & API: assign Secrets Store permissions roles & view audit logs for actions taken in Secrets Store core platform
For instructions on how to get started, visit our developer documentation.
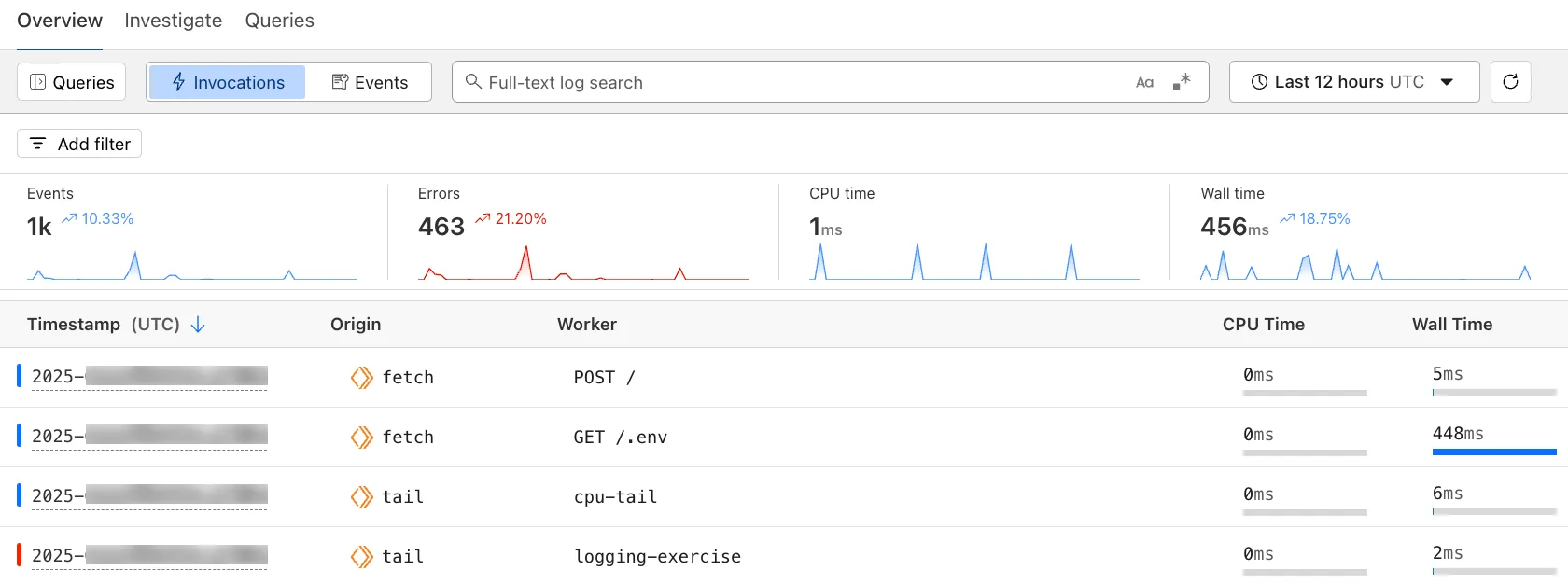
The Workers Observability dashboard ↗ offers a single place to investigate and explore your Workers Logs.
The Overview tab shows logs from all your Workers in one place. The Invocations view groups logs together by invocation, which refers to the specific trigger that started the execution of the Worker (i.e. fetch). The Events view shows logs in the order they were produced, based on timestamp. Previously, you could only view logs for a single Worker.
The Investigate tab presents a Query Builder, which helps you write structured queries to investigate and visualize your logs. The Query Builder can help answer questions such as:
- Which paths are experiencing the most 5XX errors?
- What is the wall time distribution by status code for my Worker?
- What are the slowest requests, and where are they coming from?
- Who are my top N users?
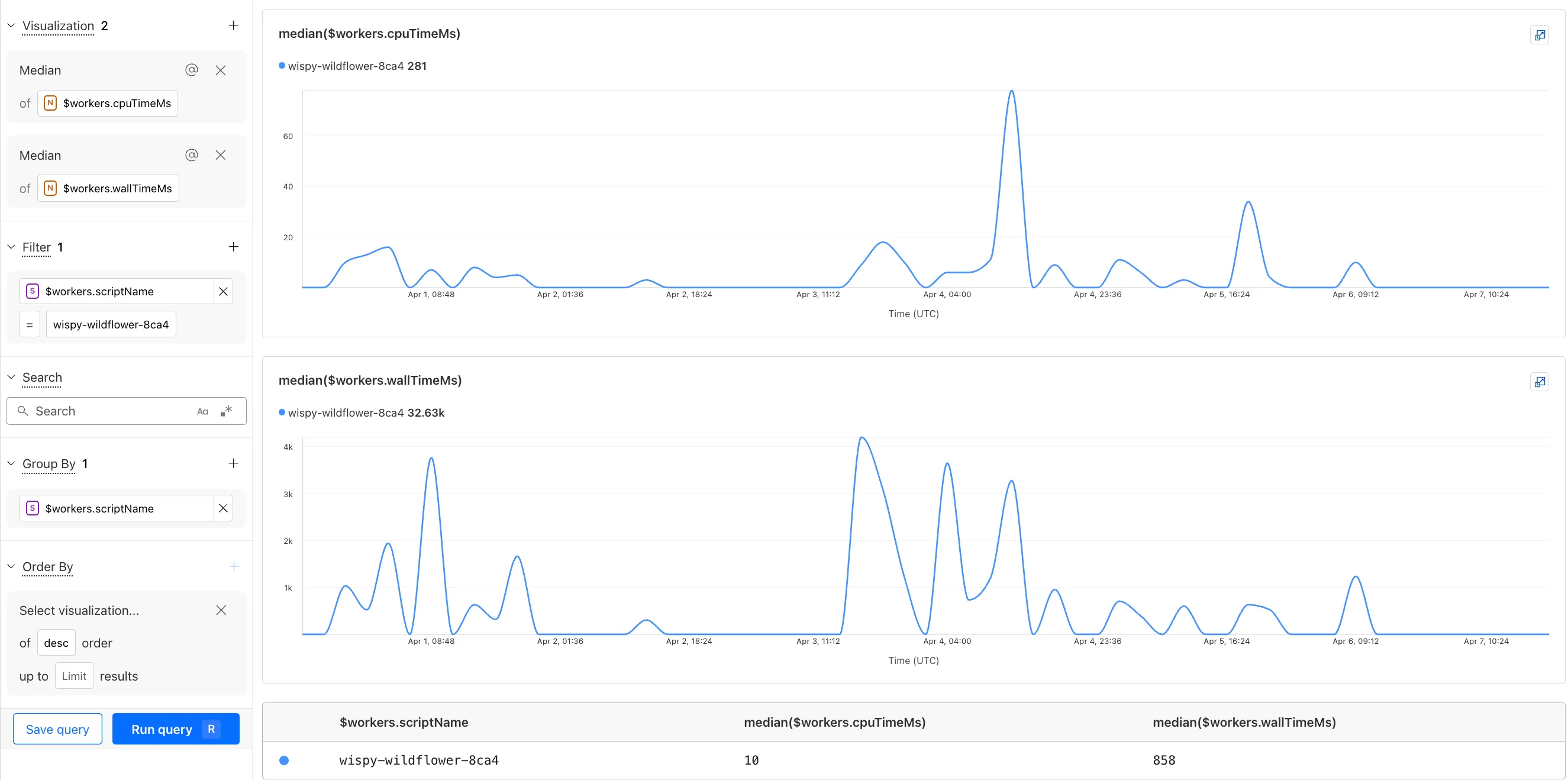
The Query Builder can use any field that you store in your logs as a key to visualize, filter, and group by. Use the Query Builder to quickly access your data, build visualizations, save queries, and share them with your team.
Workers Logs is now Generally Available. With a small change to your Wrangler configuration, Workers Logs ingests, indexes, and stores all logs emitted from your Workers for up to 7 days.
We've introduced a number of changes during our beta period, including:
- Dashboard enhancements with customizable fields as columns in the Logs view and support for invocation-based grouping
- Performance improvements to ensure no adverse impact
- Public API endpoints ↗ for broader consumption
The API documents three endpoints: list the keys in the telemetry dataset, run a query, and list the unique values for a key. For more, visit our REST API documentation ↗.
Visit the docs to learn more about the capabilities and methods exposed by the Query Builder. Start using Workers Logs and the Query Builder today by enabling observability for your Workers:
{"observability": {"enabled": true,"logs": {"invocation_logs": true,"head_sampling_rate": 1 // optional. default = 1.}}}[observability]enabled = true[observability.logs]invocation_logs = truehead_sampling_rate = 1
You can now observe and investigate the CPU time and Wall time for every Workers Invocations.
- For Workers Logs, CPU time and Wall time are surfaced in the Invocation Log..
- For Tail Workers, CPU time and Wall time are surfaced at the top level of the Workers Trace Events object.
- For Workers Logpush, CPU and Wall time are surfaced at the top level of the Workers Trace Events object. All new jobs will have these new fields included by default. Existing jobs need to be updated to include CPU time and Wall time.
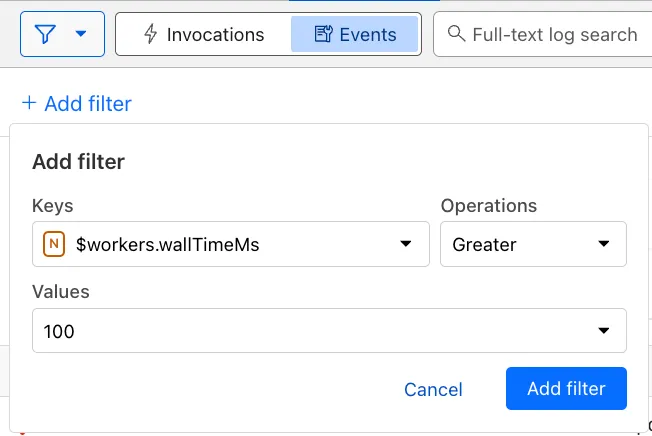
You can use a Workers Logs filter to search for logs where Wall time exceeds 100ms.
You can also use the Workers Observability Query Builder ↗ to find the median CPU time and median Wall time for all of your Workers.
A new GA release for the Windows WARP client is now available on the stable releases downloads page.
This release contains a hotfix for captive portal detection for the 2025.2.600.0 release.
Changes and improvements
- Fix to reduce the number of browser tabs opened during captive portal logins.
Known issues
DNS resolution may be broken when the following conditions are all true:
- WARP is in Secure Web Gateway without DNS filtering (tunnel-only) mode.
- A custom DNS server address is configured on the primary network adapter.
- The custom DNS server address on the primary network adapter is changed while WARP is connected.
To work around this issue, reconnect the WARP client by toggling off and back on.
A new GA release for the macOS WARP client is now available on the stable releases downloads page.
This release contains a hotfix for captive portal detection and PF state tables for the 2025.2.600.0 release.
Changes and improvements
- Fix to reduce the number of browser tabs opened during captive portal logins.
- Improvement to exclude local DNS traffic entries from PF state table to reduce risk of connectivity issues from exceeding table capacity.
Known issues
- macOS Sequoia: Due to changes Apple introduced in macOS 15.0.x, the WARP client may not behave as expected. Cloudflare recommends the use of macOS 15.4 or later.
Email Workers enables developers to programmatically take action on anything that hits their email inbox. If you're building with Email Workers, you can now test the behavior of an Email Worker script, receiving, replying and sending emails in your local environment using
wrangler dev.Below is an example that shows you how you can receive messages using the
email()handler and parse them using postal-mime ↗:TypeScript import * as PostalMime from "postal-mime";export default {async email(message, env, ctx) {const parser = new PostalMime.default();const rawEmail = new Response(message.raw);const email = await parser.parse(await rawEmail.arrayBuffer());console.log(email);},};Now when you run
npx wrangler dev, wrangler will expose a local/cdn-cgi/handler/emailendpoint that you canPOSTemail messages to and trigger your Worker'semail()handler:Terminal window curl -X POST 'http://localhost:8787/cdn-cgi/handler/email' \--url-query 'from=sender@example.com' \--url-query 'to=recipient@example.com' \--header 'Content-Type: application/json' \--data-raw 'Received: from smtp.example.com (127.0.0.1)by cloudflare-email.com (unknown) id 4fwwffRXOpyRfor <recipient@example.com>; Tue, 27 Aug 2024 15:50:20 +0000From: "John" <sender@example.com>Reply-To: sender@example.comTo: recipient@example.comSubject: Testing Email Workers Local DevContent-Type: text/html; charset="windows-1252"X-Mailer: CurlDate: Tue, 27 Aug 2024 08:49:44 -0700Message-ID: <6114391943504294873000@ZSH-GHOSTTY>Hi there'This is what you get in the console:
{"headers": [{"key": "received","value": "from smtp.example.com (127.0.0.1) by cloudflare-email.com (unknown) id 4fwwffRXOpyR for <recipient@example.com>; Tue, 27 Aug 2024 15:50:20 +0000"},{ "key": "from", "value": "\"John\" <sender@example.com>" },{ "key": "reply-to", "value": "sender@example.com" },{ "key": "to", "value": "recipient@example.com" },{ "key": "subject", "value": "Testing Email Workers Local Dev" },{ "key": "content-type", "value": "text/html; charset=\"windows-1252\"" },{ "key": "x-mailer", "value": "Curl" },{ "key": "date", "value": "Tue, 27 Aug 2024 08:49:44 -0700" },{"key": "message-id","value": "<6114391943504294873000@ZSH-GHOSTTY>"}],"from": { "address": "sender@example.com", "name": "John" },"to": [{ "address": "recipient@example.com", "name": "" }],"replyTo": [{ "address": "sender@example.com", "name": "" }],"subject": "Testing Email Workers Local Dev","messageId": "<6114391943504294873000@ZSH-GHOSTTY>","date": "2024-08-27T15:49:44.000Z","html": "Hi there\n","attachments": []}Local development is a critical part of the development flow, and also works for sending, replying and forwarding emails. See our documentation for more information.
Hyperdrive is now available on the Free plan of Cloudflare Workers, enabling you to build Workers that connect to PostgreSQL or MySQL databases without compromise.
Low-latency access to SQL databases is critical to building full-stack Workers applications. We want you to be able to build on fast, global apps on Workers, regardless of the tools you use. So we made Hyperdrive available for all, to make it easier to build Workers that connect to PostgreSQL and MySQL.
If you want to learn more about how Hyperdrive works, read the deep dive ↗ on how Hyperdrive can make your database queries up to 4x faster.
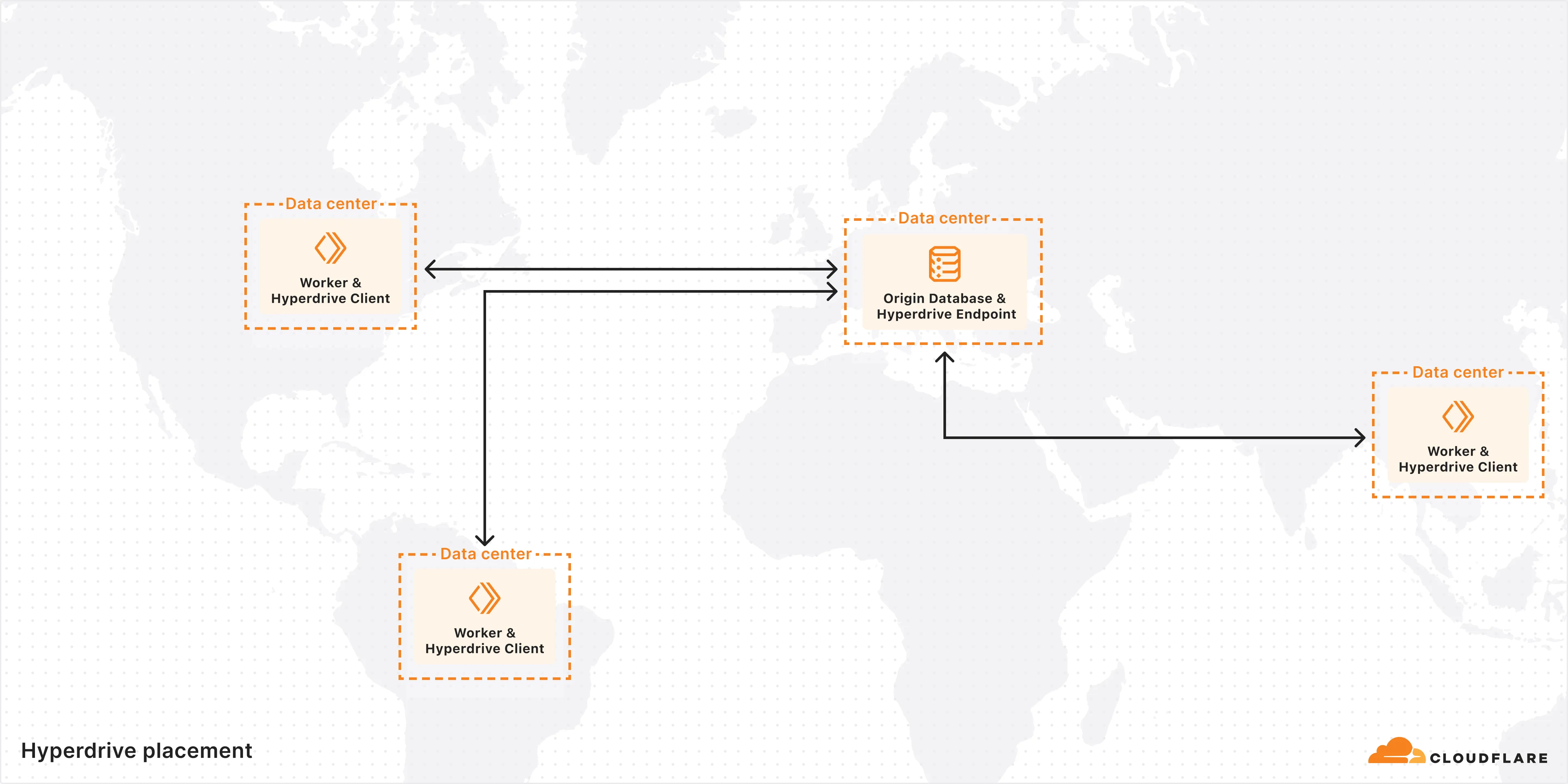
Visit the docs to get started with Hyperdrive for PostgreSQL or MySQL.
Hyperdrive now supports connecting to MySQL and MySQL-compatible databases, including Amazon RDS and Aurora MySQL, Google Cloud SQL for MySQL, Azure Database for MySQL, PlanetScale and MariaDB.
Hyperdrive makes your regional, MySQL databases fast when connecting from Cloudflare Workers. It eliminates unnecessary network roundtrips during connection setup, pools database connections globally, and can cache query results to provide the fastest possible response times.
Best of all, you can connect using your existing drivers, ORMs, and query builders with Hyperdrive's secure credentials, no code changes required.
TypeScript import { createConnection } from "mysql2/promise";export interface Env {HYPERDRIVE: Hyperdrive;}export default {async fetch(request, env, ctx): Promise<Response> {const connection = await createConnection({host: env.HYPERDRIVE.host,user: env.HYPERDRIVE.user,password: env.HYPERDRIVE.password,database: env.HYPERDRIVE.database,port: env.HYPERDRIVE.port,disableEval: true, // Required for Workers compatibility});const [results, fields] = await connection.query("SHOW tables;");ctx.waitUntil(connection.end());return new Response(JSON.stringify({ results, fields }), {headers: {"Content-Type": "application/json","Access-Control-Allow-Origin": "*",},});},} satisfies ExportedHandler<Env>;Learn more about how Hyperdrive works and get started building Workers that connect to MySQL with Hyperdrive.
You can now add a Deploy to Cloudflare button to the README of your Git repository containing a Workers application — making it simple for other developers to quickly set up and deploy your project!
The Deploy to Cloudflare button:
- Creates a new Git repository on your GitHub/ GitLab account: Cloudflare will automatically clone and create a new repository on your account, so you can continue developing.
- Automatically provisions resources the app needs: If your repository requires Cloudflare primitives like a Workers KV namespace, a D1 database, or an R2 bucket, Cloudflare will automatically provision them on your account and bind them to your Worker upon deployment.
- Configures Workers Builds (CI/CD): Every new push to your production branch on your newly created repository will automatically build and deploy courtesy of Workers Builds.
- Adds preview URLs to each pull request: If you'd like to test your changes before deploying, you can push changes to a non-production branch and preview URLs will be generated and posted back to GitHub as a comment.
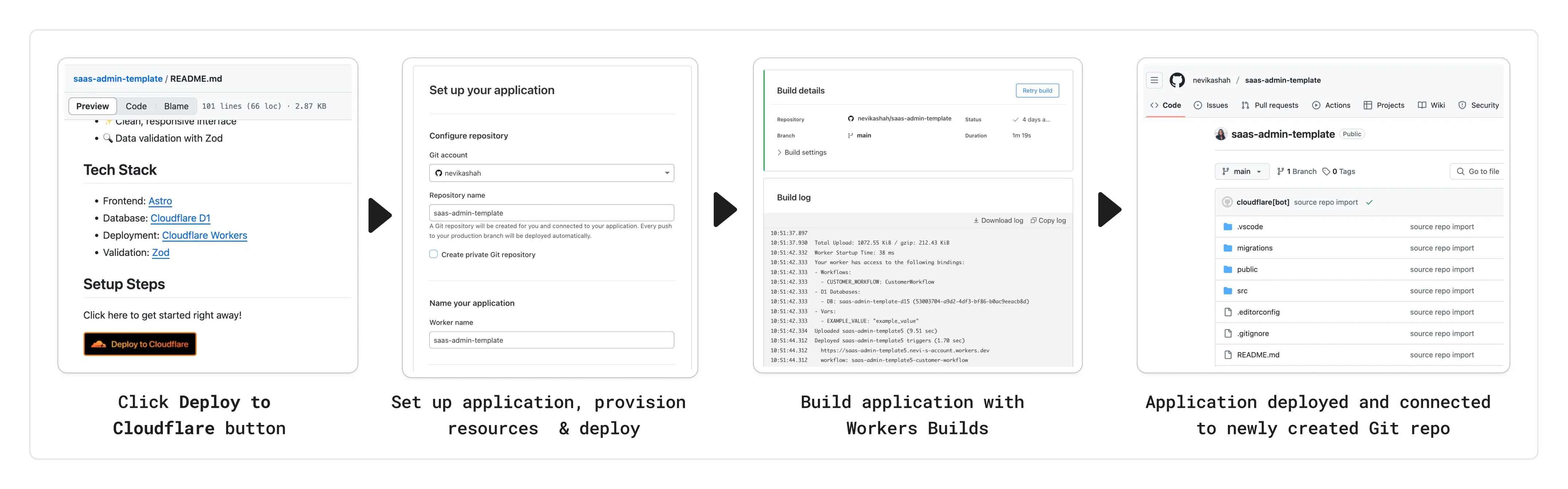
To create a Deploy to Cloudflare button in your README, you can add the following snippet, including your Git repository URL:
[](https://deploy.workers.cloudflare.com/?url=<YOUR_GIT_REPO_URL>)Check out our documentation for more information on how to set up a deploy button for your application and best practices to ensure a successful deployment for other developers.
The following full-stack frameworks now have Generally Available ("GA") adapters for Cloudflare Workers, and are ready for you to use in production:
The following frameworks are now in beta, with GA support coming very soon:
- Next.js, supported through @opennextjs/cloudflare ↗ is now
v1.0-beta. - Angular
- SolidJS (SolidStart)
You can also build complete full-stack apps on Workers without a framework:
- You can “just use Vite" ↗ and React together, and build a back-end API in the same Worker. Follow our React SPA with an API tutorial to learn how.
Get started building today with our framework guides, or read our Developer Week 2025 blog post ↗ about all the updates to building full-stack applications on Workers.
- Next.js, supported through @opennextjs/cloudflare ↗ is now
When using a Worker with the
nodejs_compatcompatibility flag enabled, the following Node.js APIs are now available:This make it easier to reuse existing Node.js code in Workers or use npm packages that depend on these APIs.
The full
node:crypto↗ API is now available in Workers.You can use it to verify and sign data:
JavaScript import { sign, verify } from "node:crypto";const signature = sign("sha256", "-data to sign-", env.PRIVATE_KEY);const verified = verify("sha256", "-data to sign-", env.PUBLIC_KEY, signature);Or, to encrypt and decrypt data:
JavaScript import { publicEncrypt, privateDecrypt } from "node:crypto";const encrypted = publicEncrypt(env.PUBLIC_KEY, "some data");const plaintext = privateDecrypt(env.PRIVATE_KEY, encrypted);See the
node:cryptodocumentation for more information.The following APIs from
node:tlsare now available:This enables secure connections over TLS (Transport Layer Security) to external services.
JavaScript import { connect } from "node:tls";// ... in a request handler ...const connectionOptions = { key: env.KEY, cert: env.CERT };const socket = connect(url, connectionOptions, () => {if (socket.authorized) {console.log("Connection authorized");}});socket.on("data", (data) => {console.log(data);});socket.on("end", () => {console.log("server ends connection");});See the
node:tlsdocumentation for more information.
The Cloudflare Vite plugin has reached v1.0 ↗ and is now Generally Available ("GA").
When you use
@cloudflare/vite-plugin, you can use Vite's local development server and build tooling, while ensuring that while developing, your code runs inworkerd↗, the open-source Workers runtime.This lets you get the best of both worlds for a full-stack app — you can use Hot Module Replacement ↗ from Vite right alongside Durable Objects and other runtime APIs and bindings that are unique to Cloudflare Workers.
@cloudflare/vite-pluginis made possible by the new environment API ↗ in Vite, and was built in partnership with the Vite team ↗.You can build any type of application with
@cloudflare/vite-plugin, using any rendering mode, from single page applications (SPA) and static sites to server-side rendered (SSR) pages and API routes.React Router v7 (Remix) is the first full-stack framework to provide full support for Cloudflare Vite plugin, allowing you to use all parts of Cloudflare's developer platform, without additional build steps.
You can also build complete full-stack apps on Workers without a framework — "just use Vite" ↗ and React together, and build a back-end API in the same Worker. Follow our React SPA with an API tutorial to learn how.
If you're already using Vite ↗ in your build and development toolchain, you can start using our plugin with minimal changes to your
vite.config.ts:vite.config.ts import { defineConfig } from "vite";import { cloudflare } from "@cloudflare/vite-plugin";export default defineConfig({plugins: [cloudflare()],});Take a look at the documentation for our Cloudflare Vite plugin for more information!