
Cache Response Rules now work with Version Management. You can version response-phase cache settings and promote them through environments, just like Cache Rules and other supported configurations.
Previously, Cache Response Rules were excluded from zone versioning. Any response-phase rule you created applied globally across all environments with no way to test changes in staging first. Cache Rules already supported versioning, but the response phase, where you modify
Cache-Controldirectives, manage cache tags, and strip headers, did not.Cache Response Rules are now fully integrated with Version Management. You can create or modify response-phase rules within a version, and those changes stay scoped to that version until promoted.
- Safe rollout of cache behavior changes: Test response-phase rules in a staging environment before promoting to production. Catch unintended caching side effects early.
- Parity with Cache Rules: Cache Response Rules now follow the same versioning workflow as Cache Rules, so you can manage all cache configuration through a single promotion pipeline.
- Independent environment control: Run different response-phase cache settings per environment. For example, strip
Set-Cookieheaders in staging to validate cacheability without affecting production traffic.
Configure Cache Response Rules in the Cloudflare dashboard ↗ under Caching > Cache Rules, or via the Rulesets API. For more details, refer to the Cache Response Rules documentation and the Version Management documentation.
Cloudflare-generated 5xx error responses now return structured JSON and Markdown when agents request them, matching the format already available for 1xxx errors. Responses follow RFC 9457 (Problem Details for HTTP APIs) ↗ and include a
Retry-AfterHTTP header on retryable codes.5xx coverage. Ten Cloudflare-generated error codes (500, 502, 504, 520-526) now serve structured responses. These are errors Cloudflare itself generates when it cannot reach or understand the origin server. Origin-generated 5xx responses that Cloudflare passes through are not affected.
Fault attribution. The
error_categoryfield tells agents where the fault lies:origin(502, 504, 520-524) — the origin server is responsible. Transient; retry with the backoff inretry_after.cloudflare(500) — Cloudflare's fault, not the website or the request. Short retry.ssl(525, 526) — the origin's TLS configuration is broken. Do not retry.
Retry-After header. Retryable codes (500, 502, 504, 520-524) include a
Retry-AfterHTTP header matching theretry_afterbody field. Non-retryable codes (525, 526) do not include the header.Request header sent Response format Accept: application/jsonJSON ( application/jsoncontent type)Accept: application/problem+jsonJSON ( application/problem+jsoncontent type)Accept: application/json, text/markdown;q=0.9JSON Accept: text/markdownMarkdown Accept: text/markdown, application/jsonMarkdown (equal q, first-listed wins)Accept: */*HTML (default) Available now for all zones on all plans.
Get JSON response for error 522:
Terminal window curl -s --compressed -H "Accept: application/json" -A "TestAgent/1.0" -H "Accept-Encoding: gzip, deflate" "<YOUR_DOMAIN>/cdn-cgi/error/522" | jq .Check presence of the
Retry-AfterHTTP header associated with the JSON response for error 521:Terminal window curl -s --compressed -D - -o /dev/null -H "Accept: application/json" -A "TestAgent/1.0" -H "Accept-Encoding: gzip, deflate" "<YOUR_DOMAIN>/cdn-cgi/error/521" | grep -i retry-afterReferences:
Resource Tagging is now in public beta and rolling out to all Cloudflare accounts over the coming days. You can attach custom key-value metadata to your Cloudflare resources and query across your entire account to find what you need.
- Broad resource type support — Tag zones, custom hostnames, Cloudflare Tunnels, Workers scripts, D1 databases, R2 buckets, KV namespaces, Durable Objects, Queues, Stream videos, Images, Access applications, Gateway rules, AI Gateways, and more. Refer to the full list of supported resource types.
- Powerful filtering — Query tagged resources using AND/OR logic, negation, and key-only matching. Combine up to 20 filters per query to build precise resource views.
- Account and zone-level endpoints — Full CRUD operations across both scopes.
- Token-based authentication — Tagging supports Account Owned Tokens that persist independently of individual users, so your automation keeps running through credential rotations and team changes.
- Flexible role support — Super Administrators, Workers Admins, and Tag Admins can all manage tags.
The API is the primary interface for Resource Tagging and the recommended path for all workflows — scripting tag assignments, building CI/CD pipelines, or integrating with your infrastructure-as-code toolchain.
You can also view and manage tagged resources directly in the Cloudflare dashboard. Navigate to Manage Account > Resource Tagging to see all tagged resources across your account, filter by resource name or tag, and add or edit tags inline.
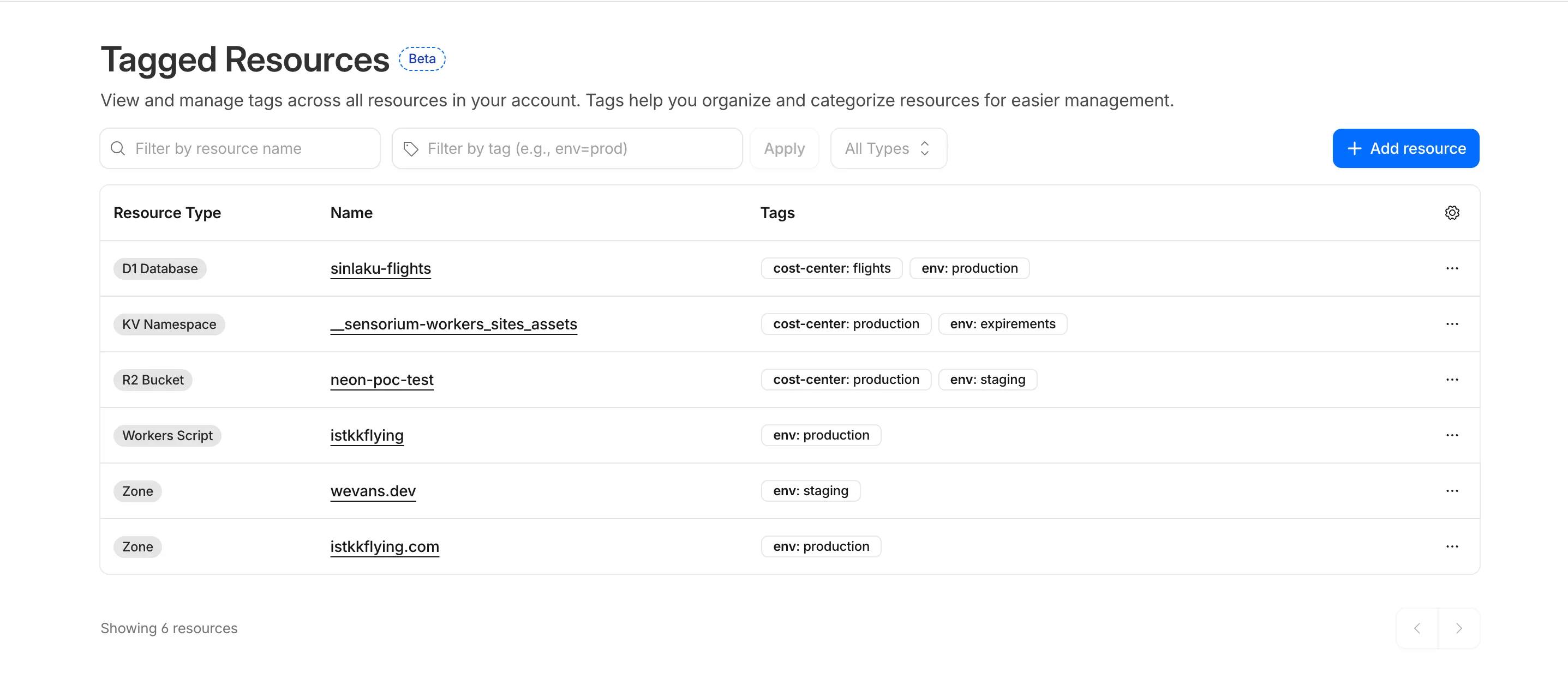
In future releases, expect support for additional resource types across the Cloudflare platform, tag-based access control policies for scoping user permissions to tagged resources, billing and usage attribution by tag for breaking down costs by team, project, or environment, and Terraform provider support for managing tags declaratively.
PUTreplaces all tags on a resource (no partial update). Use the GET, merge, PUT workflow to modify individual tags safely.DELETEremoves all tags from a resource. To remove a single tag, PUT the remaining tags back.- Querying tags for a resource that has never been tagged returns
500instead of404. This is a known beta limitation.
To get started, refer to the Resource Tagging documentation.
We have introduced a unified investigation workspace within Brand Protection to help analysts manage complex brand portfolios. Instead of jumping between individual queries, you can now consolidate your workflow into a single, cohesive view.
- You can now elect multiple saved queries from your dashboard to generate a consolidated "Combined Matches" view. This allows you to triage results from different brand queries in one unified table
- You can open query extended views in distinct tabs within the Brand Protection dashboard. This enables you to maintain multiple investigation contexts simultaneously and switch between them without losing your place.
- You can reset your workspace using the new "Clear Selection" action, making it easier to pivot between different investigation sets.
- Eliminate fragmented workflows by viewing all matches across different query buckets in a single table, reducing the need to click through dozens of individual query pages
- Correlate related campaigns by seeing similar domains or infrastructure patterns that appear across multiple saved queries
Learn more in our Brand Protection documentation.
Zero Trust Network Session Logs are now generated for all traffic proxied through Cloudflare Gateway, regardless of on-ramp type. This includes traffic from proxy endpoints (PAC files) and Browser Isolation egress — on-ramps that previously did not generate session logs.
Customers who already consume the
zero_trust_network_sessionsdataset via Logpush or Log Explorer may see increased log volume if they use these on-ramps.For field definitions, refer to Zero Trust Network Session Logs. For traffic analysis, refer to Network session analytics.
We're excited to announce tf-migrate, a purpose-built CLI tool that simplifies migrating from Cloudflare Terraform Provider v4 to v5.
Terraform Provider v5 is stable and actively receiving updates. We encourage all users to migrate to v5 to take advantage of ongoing enhancements and new capabilities.
Cloudflare uses tf-migrate to migrate our own infrastructure — the same tool we're providing to the community — ensuring the best possible migration experience.
tf-migrate automates the tedious and error-prone parts of the v4 to v5 migration process:
- Resource type renames – Automatically updates
cloudflare_record→cloudflare_dns_record,cloudflare_access_application→cloudflare_zero_trust_access_application, and 40+ other renamed resources - Attribute transformations – Updates field names (e.g.,
value→contentfor DNS records) and restructures nested blocks - Moved block generation – Creates Terraform 1.8+
movedblocks to prevent resource replacements and ensure zero-downtime migrations - Cross-file reference updates – Automatically finds and updates all references to renamed resources across your entire configuration
- Dry-run mode – Preview all changes before applying them to ensure safety
Combined with the automatic state upgraders introduced in v5.19+, tf-migrate eliminates the manual work and risk that previously made v5 migrations challenging. Tf-migrate operates directly on the config, and the built-in state upgraders handle the rest.
Tf-migrate currently supports the most common Terraform resources our customers use. We are actively working to expand coverage, with the most commonly used resources prioritized first.
For the complete list of supported resources and their migration status, refer to the v5 Stabilization Tracker ↗. This list is updated regularly as additional resources are stabilized and migration support is added.
Resources not yet supported by tf-migrate will need to be migrated manually using the version 5 upgrade guide ↗. The upgrade guide provides step-by-step instructions for handling resource renames, attribute changes, and state migrations.
- Download tf-migrate ↗
- Version 5 Migration Guide ↗
- Terraform Provider documentation ↗
- v5 Stabilization Tracker ↗
We have been releasing Betas over the past month and a half while testing this tool. See the full changelog of those Betas here: tf-migrate releases ↗.
- Resource type renames – Automatically updates
Audit Logs v2 now supports organization-level audit logs. Org Admins can retrieve audit events for actions performed at the organization level via the Audit Logs v2 API.
To retrieve organization-level audit logs, use the following endpoint:
Terminal window GET https://api.cloudflare.com/client/v4/organizations/{organization_id}/logs/auditThis release covers user-initiated actions performed through organization-level APIs. Audit logs for system-initiated actions, a dashboard UI, and Logpush support for organizations will be added in future releases.
For more information, refer to the Audit Logs documentation.
-
In this release, you'll see a number of breaking changes. This is primarily due to changes in OpenAPI definitions, which our libraries are based off of, and codegen updates that we rely on to read those OpenAPI definitions and produce our SDK libraries.
Please ensure you read through the list of changes below before moving to this version - this will help you understand any down or upstream issues it may cause to your environments.
See the v6.10.0 Migration Guide ↗ for before/after code examples and actions needed for each change.
Several fields have been removed from
AbuseReportNewParamsBodyAbuseReportsRegistrarWhoisReportRegWhoRequest:RegWhoGoodFaithAffirmationRegWhoLawfulProcessingAgreementRegWhoLegalBasisRegWhoRequestTypeRegWhoRequestedDataElements
The
InstanceNewParamsandInstanceUpdateParamstypes have been significantly restructured. Many fields have been moved or removed:InstanceNewParams.TokenID,Type,CreatedFromAISearchWizard,WorkerDomainremovedInstanceUpdateParams— most configuration fields removed (includingIndexMethod,IndexingOptions,MaxNumResults,Metadata,Paused,PublicEndpointParams,Reranking,RerankingModel,RetrievalOptions,RewriteModel,RewriteQuery,ScoreThreshold,SourceParams,Summarization,SummarizationModel,SystemPromptAISearch,SystemPromptIndexSummarization,SystemPromptRewriteQuery,TokenID,CreatedFromAISearchWizard,WorkerDomain)InstanceSearchParams.Messagesfield removed along withInstanceSearchParamsMessageandInstanceSearchParamsMessagesRoletypes
The
InstanceItemServicetype has been removed. The items sub-resource atclient.AISearch.Instances.Itemsno longer exists in the non-namespace path. Useclient.AISearch.Namespaces.Instances.Itemsinstead.The following types have been removed from the
ai_searchpackage:TokenDeleteResponseTokenListParams(and associatedTokenListParamsOrderBy,TokenListParamsOrderByDirection)
The
Investigate.Move.New()method now returns a raw slice instead of a paginated wrapper:New()returns*[]InvestigateMoveNewResponseinstead of*pagination.SinglePage[InvestigateMoveNewResponse]NewAutoPaging()method removed
The
ConfigEditParamstype lost itsMTLSandNamefields. TheHyperdriveMTLSParamtype lostMTLSandHostfields. TheHostfield on origin config changed fromparam.Field[string]to a plainstring.The
UserGroupMemberNewParamsstruct has been restructured and theNew()method now returns a paginated response:UserGroupMemberNewParams.Bodyrenamed toUserGroupMemberNewParams.MembersUserGroupMemberNewParamsBodyrenamed toUserGroupMemberNewParamsMemberUserGroupMemberUpdateParams.Bodyrenamed toUserGroupMemberUpdateParams.MembersUserGroupMemberUpdateParamsBodyrenamed toUserGroupMemberUpdateParamsMemberUserGroups.Members.New()returns*pagination.SinglePage[UserGroupMemberNewResponse]instead of*UserGroupMemberNewResponse
The
UserGroupListParams.Directionfield changed fromparam.Field[string]toparam.Field[UserGroupListParamsDirection](typed enum withasc/descvalues).Several delete methods across Pipelines now return typed responses instead of bare error:
Pipelines.DeleteV1()returns(*PipelineDeleteV1Response, error)instead oferrorPipelines.Sinks.Delete()returns(*SinkDeleteResponse, error)instead oferrorPipelines.Streams.Delete()returns(*StreamDeleteResponse, error)instead oferror
The following response envelope types have been removed:
MessageBulkPushResponseSuccessMessagePushResponseSuccessMessageAckResponsefieldsRetryCountandWarningsremoved
Methods now return direct types instead of
SinglePagewrappers, and several internal types have been removed. AssociatedAutoPagingmethods have also been removed:Stores.New()returns*StoreNewResponseinstead of*pagination.SinglePage[StoreNewResponse]Stores.NewAutoPaging()method removedStores.Secrets.BulkDelete()returns*StoreSecretBulkDeleteResponseinstead of*pagination.SinglePage[StoreSecretBulkDeleteResponse]Stores.Secrets.BulkDeleteAutoPaging()method removed- Removed types:
StoreDeleteResponse,StoreDeleteResponseEnvelopeResultInfo,StoreSecretDeleteResponse,StoreSecretDeleteResponseStatus,StoreSecretBulkDeleteResponse(old shape),StoreSecretBulkDeleteResponseStatus,StoreSecretDeleteResponseEnvelopeResultInfo StoreNewParamsrestructured (oldStoreNewParamsBodyremoved)StoreSecretBulkDeleteParamsrestructured
The
AudioTracks.Get()method now returns a dedicated response type instead of a paginated list. TheGetAutoPaging()method has been removed:Get()returns*AudioTrackGetResponseinstead of*pagination.SinglePage[Audio]GetAutoPaging()method removed
The
Clip.New()method now returns the sharedVideotype. The following types have been entirely removed:Clip,ClipPlayback,ClipStatus,ClipWatermark
ClipNewParams.MaxDurationSeconds,ThumbnailTimestampPct,WatermarkremovedCopyNewParams.ThumbnailTimestampPct,Watermarkremoved
DownloadNewResponseStatustype removedWebhookUpdateResponseandWebhookGetResponsechanged frominterface{}type aliases to full struct types
The following union interface types have been removed:
AccessAIControlMcpPortalListResponseServersUpdatedPromptsUnionAccessAIControlMcpPortalListResponseServersUpdatedToolsUnionAccessAIControlMcpPortalReadResponseServersUpdatedPromptsUnionAccessAIControlMcpPortalReadResponseServersUpdatedToolsUnion
NEW SERVICE: Full vulnerability scanning management
- CredentialSets - CRUD for credential sets (
New,Update,List,Delete,Edit,Get) - Credentials - Manage credentials within sets (
New,Update,List,Delete,Edit,Get) - Scans - Create and manage vulnerability scans (
New,List,Get) - TargetEnvironments - Manage scan target environments (
New,Update,List,Delete,Edit,Get)
NEW SERVICE: Namespace-scoped AI Search management
New(),Update(),List(),Delete(),ChatCompletions(),Read(),Search()- Instances - Namespace-scoped instances (
New,Update,List,Delete,ChatCompletions,Read,Search,Stats) - Jobs - Instance job management (
New,Update,List,Get,Logs) - Items - Instance item management (
List,Delete,Chunks,NewOrUpdate,Download,Get,Logs,Sync,Upload)
NEW SERVICE: DevTools protocol browser control
- Session - List and get devtools sessions
- Browser - Browser lifecycle management (
New,Delete,Connect,Launch,Protocol,Version) - Page - Get page by target ID
- Targets - Manage browser targets (
New,List,Activate,Get)
NEW: Domain check and search endpoints
Check()-POST /accounts/{account_id}/registrar/domain-checkSearch()-GET /accounts/{account_id}/registrar/domain-search
NEW: Registration management (
client.Registrar.Registrations)New(),List(),Edit(),Get()RegistrationStatus.Get()- Get registration workflow statusUpdateStatus.Get()- Get update workflow status
NEW SERVICE: Manage origin cloud region configurations
New(),List(),Delete(),BulkDelete(),BulkEdit(),Edit(),Get(),SupportedRegions()
NEW SERVICE: DLP settings management
Update(),Delete(),Edit(),Get()
AgentReadiness.Summary()- Agent readiness summary by dimensionAI.MarkdownForAgents.Summary()- Markdown-for-agents summaryAI.MarkdownForAgents.Timeseries()- Markdown-for-agents timeseries
UserGroups.Members.Get()- Get details of a specific member in a user groupUserGroups.Members.NewAutoPaging()- Auto-paging variant for adding membersUserGroups.NewParams.Policieschanged from required to optional
ContentBotsProtectionfield added toBotFightModeConfigurationandSubscriptionConfiguration(block/disabled)
None in this release.
Custom Dashboards are now available to all Cloudflare customers. Build personalized views that highlight the metrics most critical to your infrastructure and security posture, moving beyond standard product dashboards.
This update significantly expands the data available for visualization. Build charts based on any of the 100+ datasets available via the Cloudflare GraphQL API, covering everything from WAF events and Workers metrics to Load Balancing and Zero Trust logs.
For Log Explorer customers, you can now turn raw log queries directly into dashboard charts. When you identify a specific pattern or spike while investigating logs, save that query as a visualization to monitor those signals in real-time without leaving the dashboard.
- Unified visibility: Consolidate signals from different Cloudflare products (for example, HTTP Traffic and R2 Storage) into a single view.
- Flexible monitoring: Create charts that focus on specific status codes, ASN regions, or security actions that matter to your business.
- Expanded limits: Log Explorer customers can create up to 100 dashboards (up from 25 for standard customers).
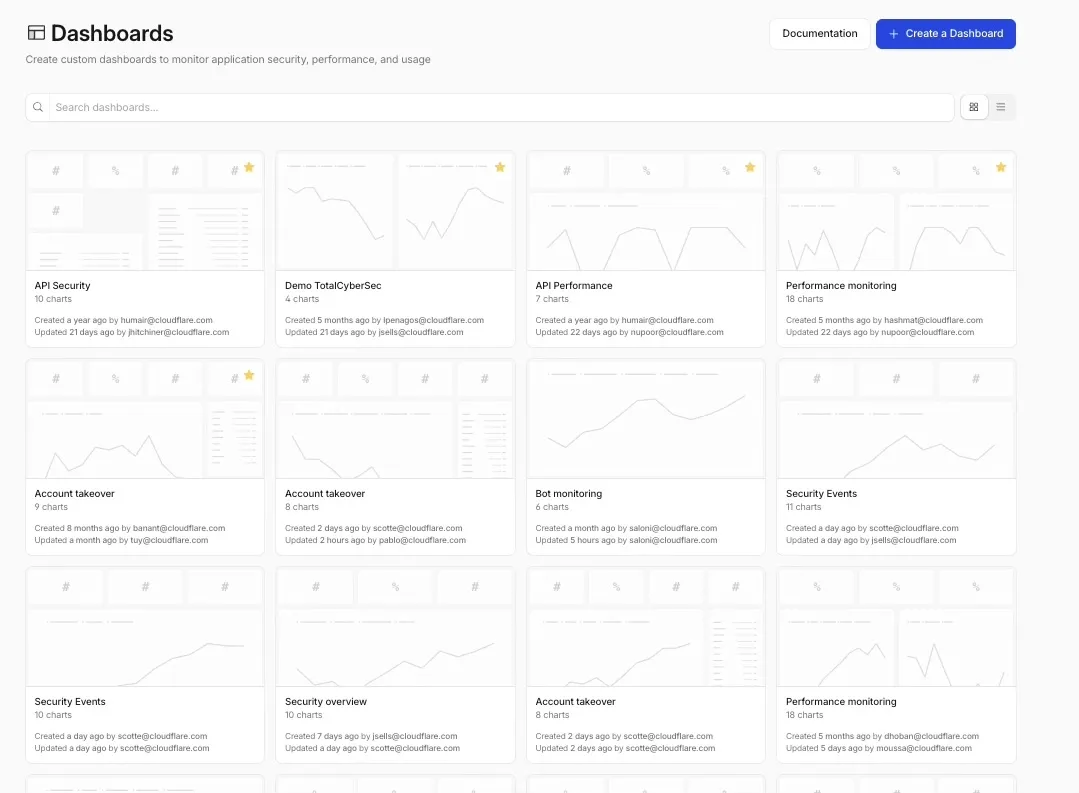
To get started, refer to the Custom Dashboards documentation.
R2 Data Catalog, a managed Apache Iceberg ↗ catalog built into R2, now removes unreferenced data files during automatic snapshot expiration. This improvement reduces storage costs and eliminates the need to run manual maintenance jobs to reclaim space from deleted data.
Previously, snapshot expiration only cleaned up Iceberg metadata files such as manifests and manifest lists. Data files that were no longer referenced by active snapshots remained in R2 storage until you manually ran
remove_orphan_filesorexpire_snapshotsthrough an engine like Spark. This required extra operational overhead and left stale data files consuming storage.Snapshot expiration now handles both metadata and data file cleanup automatically. When a snapshot is expired, any data files that are no longer referenced by retained snapshots are removed from R2 storage.
Terminal window # Enable catalog-level snapshot expirationnpx wrangler r2 bucket catalog snapshot-expiration enable my-bucket \--older-than-days 7 \--retain-last 10To learn more about snapshot expiration and other automatic maintenance operations, refer to the table maintenance documentation.
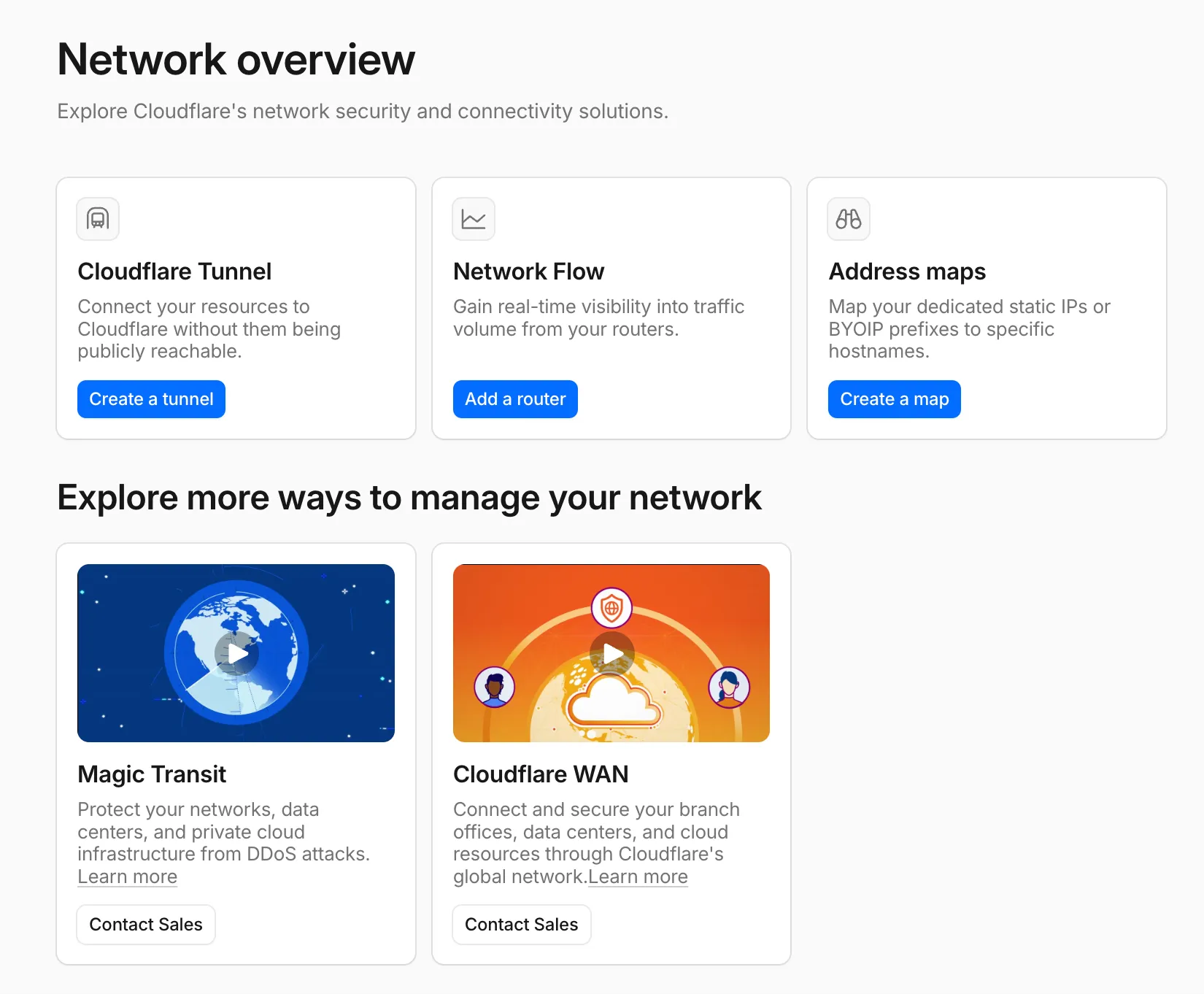
A new Network Overview page in the Cloudflare dashboard gives you a single starting point for network security and connectivity products.
From the Network Overview page, you can:
- Connect resources with Cloudflare Tunnel - Create tunnels to connect your infrastructure to Cloudflare without exposing it to the public Internet.
- Monitor traffic with Network Flow - Get real-time visibility into traffic volume from your routers.
- Configure Address Maps - Map dedicated static IPs or BYOIP prefixes to specific hostnames.
- Explore Magic Transit and Cloudflare WAN - Set up DDoS protection for your networks and connectivity for your branch offices and data centers.
To find it, go to Networking ↗ in the dashboard sidebar.
If you already use Magic Transit, Cloudflare WAN, or other Cloudflare network services products, your existing experience is unchanged.
Workflows now provides additional context inside
step.do()callbacks and supports returningReadableStreamto handle larger step outputs.The
step.do()callback receives a context object with new properties alongsideattempt:step.name— The name passed tostep.do()step.count— How many times a step with that name has been invoked in this instance (1-indexed)- Useful when running the same step in a loop.
config— The resolved step configuration, includingtimeoutandretrieswith defaults applied
TypeScript type ResolvedStepConfig = {retries: {limit: number;delay: WorkflowDelayDuration | number;backoff?: "constant" | "linear" | "exponential";};timeout: WorkflowTimeoutDuration | number;};type WorkflowStepContext = {step: {name: string;count: number;};attempt: number;config: ResolvedStepConfig;};Steps can now return a
ReadableStreamdirectly. Although non-stream step outputs are limited to 1 MiB, streamed outputs support much larger payloads.TypeScript const largePayload = await step.do("fetch-large-file", async () => {const object = await env.MY_BUCKET.get("large-file.bin");return object.body;});Note that streamed outputs are still considered part of the Workflow instance storage limit.
The Container logs page now displays related Worker and Durable Object logs alongside container logs. This co-locates all relevant log events for a container application in one place, making it easier to trace requests and debug issues.
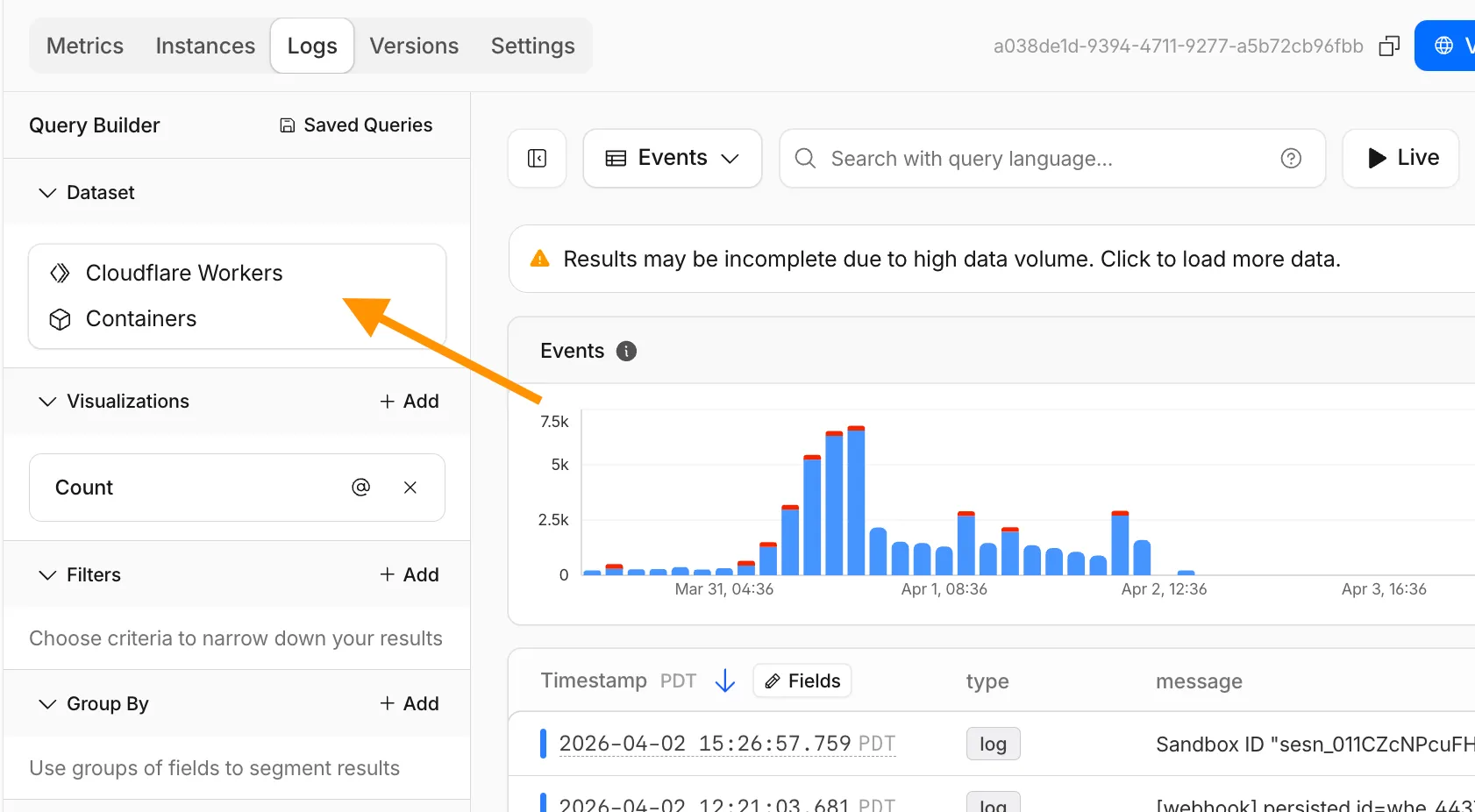
You can filter to a single source when you need to isolate Container, Worker, or Durable Object output.
For information on configuring container logging, refer to How do Container logs work?.
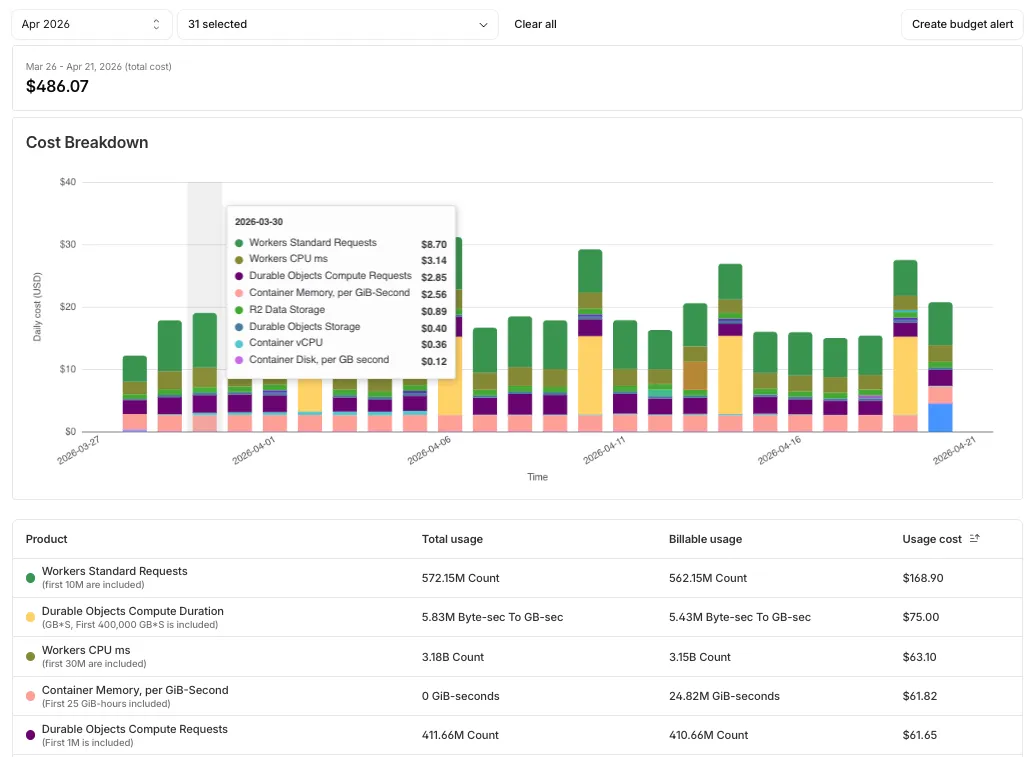
Pay-as-you-go customers can now monitor usage-based costs and configure spend alerts through two new features: the Billable Usage dashboard and Budget alerts.
The Billable Usage dashboard provides daily visibility into usage-based costs across your Cloudflare account. The data comes from the same system that generates your monthly invoice, so the figures match your bill.
The dashboard displays:
- A bar chart showing daily usage charges for your billing period
- A sortable table breaking down usage by product, including total usage, billable usage, and cumulative costs
- Ability to view previous billing periods
Usage data aligns to your billing cycle, not the calendar month. The total usage cost shown at the end of a completed billing period matches the usage overage charges on your corresponding invoice.
To access the dashboard, go to Manage Account > Billing > Billable Usage.
Budget alerts allow you to set dollar-based thresholds for your account-level usage spend. You receive an email notification when your projected monthly spend reaches your configured threshold, giving you proactive visibility into your bill before month-end.
To configure a budget alert:
- Go to Manage Account > Billing > Billable Usage.
- Select Set Budget Alert.
- Enter a budget threshold amount greater than $0.
- Select Create.
Alternatively, configure alerts via Notifications > Add > Budget Alert.
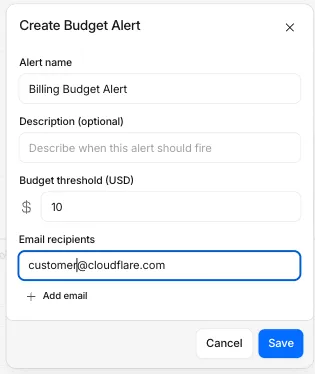
You can create multiple budget alerts at different dollar amounts. The notifications system automatically deduplicates alerts if multiple thresholds trigger at the same time. Budget alerts are calculated daily based on your usage trends and fire once per billing cycle when your projected spend first crosses your threshold.
Both features are available to Pay-as-you-go accounts with usage-based products (Workers, R2, Images, etc.). Enterprise contract accounts are not supported.
For more information, refer to the Usage based billing documentation.
When a Cloudflare Worker intercepts a visitor request, it can dispatch additional outbound fetch calls called subrequests. By default, each subrequest generates its own log entry in Logpush, resulting in multiple log lines per visitor request. With subrequest merging enabled, subrequest data is embedded as a nested array field on the parent log record instead.
- New subrequest_merging field on Logpush jobs — Set "merge_subrequests": true when creating or updating an http_requests Logpush job to enable the feature.
- New Subrequests log field — When subrequest merging is enabled, a Subrequests field (
array\<object\>) is added to each parent request log record. Each element in the array contains the standard http_requests fields for that subrequest.
- Applies to the http_requests (zone-scoped) dataset only.
- A maximum of 50 subrequests are merged per parent request. Subrequests beyond this limit are passed through unmodified as individual log entries.
- Subrequests must complete within 5 minutes of the visitor request. Subrequests that exceed this window are passed through unmodified.
- Subrequests that do not qualify appear as separate log entries — no data is lost.
- Subrequest merging is being gradually rolled out and is not yet available on all zones. Contact your account team for concerns or to ensure it is enabled for your zone.
- For more information, refer to Subrequests.
This week's release introduces a new detection for a Remote Code Execution (RCE) vulnerability in Apache ActiveMQ (CVE-2026-34197) and an updated signature for Magento 2 - Unrestricted File Upload. Alongside these detections, we are continuing our work on rule refinements to provide deeper security insights for our customers.
Key Findings
-
Apache ActiveMQ (CVE-2026-34197): A vulnerability in Apache ActiveMQ allows an unauthenticated, remote attacker to execute arbitrary code. This flaw occurs during the processing of specially crafted network packets, leading to potential full system compromise.
-
Magento 2 - Unrestricted File Upload - 2: This is a follow-up enhancement to our existing protections for Magento and Adobe Commerce.
Impact
Successful exploitation of these vulnerabilities could allow unauthenticated attackers to execute arbitrary code or gain full administrative control over affected servers. We strongly recommend applying official vendor patches for Apache ActiveMQ and Magento to address the underlying vulnerabilities.
Continuous Rule Improvements
We are continuously refining our managed rules to provide more resilient protection and deeper insights into attack patterns. To ensure an optimal security posture, we recommend consistently monitoring the Security Events dashboard and adjusting rule actions as these enhancements are deployed.
Ruleset Rule ID Legacy Rule ID Description Previous Action New Action Comments Cloudflare Managed Ruleset N/A Command Injection - Generic 8 - uri Log Block This is a new detection. Previous description was "Command Injection - Generic 8 - uri - Beta" Cloudflare Managed Ruleset N/A Command Injection - Generic 8 - body - Beta Disabled Disabled This is a new detection. This rule is merged into the original rule "Command Injection - Generic 8 - body" (ID:
Cloudflare Managed Ruleset N/A MySQL - SQLi - Executable Comment - Beta Log Block This is a new detection. This rule is merged into the original rule "MySQL - SQLi - Executable Comment - Body" (ID:
Cloudflare Managed Ruleset N/A MySQL - SQLi - Executable Comment - Headers Log Block This is a new detection.
Cloudflare Managed Ruleset N/A MySQL - SQLi - Executable Comment - URI Log Block This is a new detection.
Cloudflare Managed Ruleset N/A Magento 2 - Unrestricted file upload - 2 Log Block This is a new detection.
Cloudflare Managed Ruleset N/A Apache ActiveMQ - Remote Code Execution - CVE:CVE-2026-34197 Log Block This is a new detection.
Cloudflare Managed Ruleset N/A SQLi - Sleep Function - Beta Log Block This is a new detection. This rule is merged into the original rule "SQLi - Sleep Function" (ID:
Cloudflare Managed Ruleset N/A SQLi - Sleep Function - Headers Log Block This is a new detection.
Cloudflare Managed Ruleset N/A SQLi - Sleep Function - URI Log Block This is a new detection.
Cloudflare Managed Ruleset N/A SQLi - Probing - uri Log Block This is a new detection.
Cloudflare Managed Ruleset N/A SQLi - Probing - header Log Block This is a new detection.
Cloudflare Managed Ruleset N/A SQLi - Probing - body Disabled Disabled This is a new detection. This rule is merged into the original rule "SQLi - Probing" (ID:
Cloudflare Managed Ruleset N/A SQLi - Probing 2 Disabled Disabled This rule had duplicate detection logic and has been deprecated.
Cloudflare Managed Ruleset N/A SQLi - UNION in MSSQL - Body Disabled Disabled This rule has been renamed to differentiate from "SQLi - UNION in MSSQL" (ID:
Cloudflare Managed Ruleset N/A SQLi - UNION - 3 Disabled Disabled This rule had duplicate detection logic and has been deprecated.
Cloudflare Managed Ruleset N/A XSS, HTML Injection - Embed Tag - URI Disabled Disabled This is a new detection.
Cloudflare Managed Ruleset N/A XSS, HTML Injection - Embed Tag - Headers Log Block This is a new detection.
Cloudflare Managed Ruleset N/A XSS, HTML Injection - IFrame Tag - Src and Srcdoc Attributes - Headers Log Disabled This is a new detection.
Cloudflare Managed Ruleset N/A XSS, HTML Injection - Link Tag - Headers Log Disabled This is a new detection.
Cloudflare Managed Ruleset N/A XSS, HTML Injection - Link Tag - URI Disabled Disabled This is a new detection.
-
Announcement Date Release Date Release Behavior Legacy Rule ID Rule ID Description Comments 2026-04-21 2026-04-27 Log N/A PostgreSQL - SQLi - COPY - Beta This is a new detection. This rule will be merged into the original rule "PostgreSQL - SQLi - COPY" (ID:
2026-04-21 2026-04-27 Log N/A PostgreSQL - SQLi - COPY - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A PostgreSQL - SQLi - COPY - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Destructive Operations This is a new detection.
2026-04-21 2026-04-27 Log N/A SQLi - AND/OR MAKE_SET/ELT - Beta This is a new detection. This rule will be merged into the original rule "SQLi - AND/OR MAKE_SET/ELT" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - AND/OR MAKE_SET/ELT - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - AND/OR MAKE_SET/ELT - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Common Patterns - Beta This is a new detection. This rule will be merged into the original rule "SQLi - Common Patterns" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - Common Patterns - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Common Patterns - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Equation - Beta This is a new detection. This rule will be merged into the original rule "SQLi - Equation" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - Equation - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Equation - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - AND/OR Digit Operator Digit - Beta This is a new detection. This rule will be merged into the original rule "SQLi - AND/OR Digit Operator Digit" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - AND/OR Digit Operator Digit - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - AND/OR Digit Operator Digit - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Benchmark Function - Beta This is a new detection. This rule will be merged into the original rule "SQLi - Benchmark Function" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - Benchmark Function - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Benchmark Function - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Comparison - Beta This is a new detection. This rule will be merged into the original rule "SQLi - Comparison" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - Comparison - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - Comparison - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - String Concatenation - Body - Beta This is a new detection. This rule will be merged into the original rule "SQLi - String Concatenation - Headers" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - String Concatenation - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - String Concatenation - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - SELECT Expression - Beta This is a new detection. This rule will be merged into the original rule "SQLi - SELECT Expression" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - SELECT Expression - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - SELECT Expression - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - ORD and ASCII - Beta This is a new detection. This rule will be merged into the original rule "SQLi - ORD and ASCII" (ID:
2026-04-21 2026-04-27 Log N/A SQLi - ORD and ASCII - Headers This is a new detection. 2026-04-21 2026-04-27 Log N/A SQLi - ORD and ASCII - URI This is a new detection. 2026-04-21 2026-04-27 Log N/A XSS, HTML Injection - Object Tag - Body (beta) This is a new detection. 2026-04-21 2026-04-27 Log N/A XSS, HTML Injection - Object Tag - Headers (beta) This is a new detection. 2026-04-21 2026-04-27 Log N/A XSS, HTML Injection - Object Tag - URI (beta) This is a new detection.
Binary frames received on a
WebSocketare now delivered to themessageevent asBlob↗ objects by default. This matches the WebSocket specification ↗ and standard browser behavior. Previously, binary frames were always delivered asArrayBuffer↗. ThebinaryTypeproperty onWebSocketcontrols the delivery type on a per-WebSocket basis.This change has been active for Workers with compatibility dates on or after
2026-03-17, via thewebsocket_standard_binary_typecompatibility flag. We should have documented this change when it shipped but didn't. We're sorry for the trouble that caused. If your Worker handles binary WebSocket messages and assumesevent.datais anArrayBuffer, the frames will arrive asBlobinstead, and a naiveinstanceof ArrayBuffercheck will silently drop every frame.To opt back into
ArrayBufferdelivery, assignbinaryTypebefore callingaccept(). This works regardless of the compatibility flag:JavaScript const resp = await fetch("https://example.com", {headers: { Upgrade: "websocket" },});const ws = resp.webSocket;// Opt back into ArrayBuffer delivery for this WebSocket.ws.binaryType = "arraybuffer";ws.accept();ws.addEventListener("message", (event) => {if (typeof event.data === "string") {// Text frame.} else {// event.data is an ArrayBuffer because we set binaryType above.}});If you are not ready to migrate and want to keep
ArrayBufferas the default for all WebSockets in your Worker, add theno_websocket_standard_binary_typeflag to your Wrangler configuration file.This change has no effect on the Durable Object hibernatable WebSocket
webSocketMessagehandler, which continues to receive binary data asArrayBuffer.For more information, refer to WebSockets binary messages.
The new Network session analytics dashboard is now available in Cloudflare One. This dashboard provides visibility into your network traffic patterns, helping you understand how traffic flows through your Cloudflare One infrastructure.
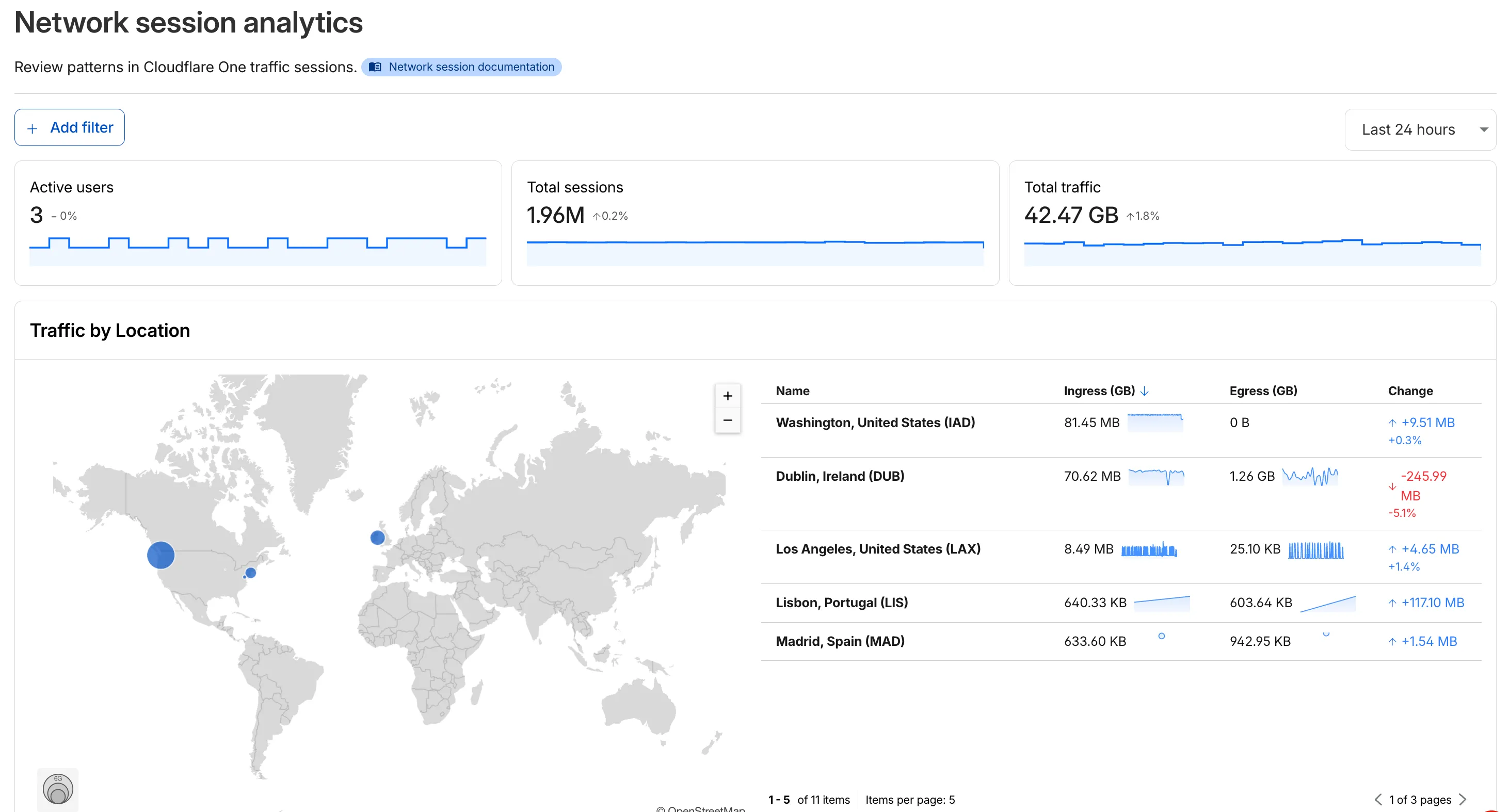
- Analyze geographic distribution: View a world map showing where your network traffic originates, with a list of top locations by session count.
- Monitor key metrics: Track session count, total bytes transferred, and unique users.
- Identify connection issues: Analyze connection close reasons to troubleshoot network problems.
- Review protocol usage: See which network protocols (TCP, UDP, ICMP) are most used.
- Summary metrics: Session count, bytes total, and unique users
- Traffic by location: World map visualization and location list with top traffic sources
- Top protocols: Breakdown of TCP, UDP, ICMP, and ICMPv6 traffic
- Connection close reasons: Insights into why sessions terminated (client closed, origin closed, timeouts, errors)
- Log in to Cloudflare One ↗.
- Go to Zero Trust > Insights > Dashboards.
- Select Network session analytics.
For more information, refer to the Network session analytics documentation.
Logpush has traditionally been great at delivering Cloudflare logs to a variety of destinations in JSON format. While JSON is flexible and easily readable, it can be inefficient to store and query at scale.
With this release, you can now send your logs directly to Pipelines to ingest, transform, and store your logs in R2 as Parquet files or Apache Iceberg tables managed by R2 Data Catalog. This makes the data footprint more compact and more efficient at querying your logs instantly with R2 SQL or any other query engine that supports Apache Iceberg or Parquet.
Pipelines SQL runs on each log record in-flight, so you can reshape your data before it is written. For example, you can drop noisy fields, redact sensitive values, or derive new columns:
INSERT INTO http_logs_sinkSELECTClientIP,EdgeResponseStatus,to_timestamp_micros(EdgeStartTimestamp) AS event_time,upper(ClientRequestMethod) AS method,sha256(ClientIP) AS hashed_ipFROM http_logs_streamWHERE EdgeResponseStatus >= 400;Pipelines SQL supports string functions, regex, hashing, JSON extraction, timestamp conversion, conditional expressions, and more. For the full list, refer to the Pipelines SQL reference.
To configure Pipelines as a Logpush destination, refer to Enable Cloudflare Pipelines.
R2 SQL is Cloudflare's serverless, distributed, analytics query engine for querying Apache Iceberg ↗ tables stored in R2 Data Catalog.
R2 SQL now supports functions for querying JSON data stored in Apache Iceberg tables, an easier way to parse query plans with
EXPLAIN FORMAT JSON, and querying tables without partition keys stored in R2 Data Catalog.JSON functions extract and manipulate JSON values directly in SQL without client-side processing:
SELECTjson_get_str(doc, 'name') AS name,json_get_int(doc, 'user', 'profile', 'level') AS level,json_get_bool(doc, 'active') AS is_activeFROM my_namespace.sales_dataWHERE json_contains(doc, 'email')For a full list of available functions, refer to JSON functions.
EXPLAIN FORMAT JSONreturns query execution plans as structured JSON for programmatic analysis and observability integrations:Terminal window npx wrangler r2 sql query "${WAREHOUSE}" "EXPLAIN FORMAT JSON SELECT * FROM logpush.requests LIMIT 10;"┌──────────────────────────────────────┐│ plan │├──────────────────────────────────────┤│ { ││ "name": "CoalescePartitionsExec", ││ "output_partitions": 1, ││ "rows": 10, ││ "size_approx": "310B", ││ "children": [ ││ { ││ "name": "DataSourceExec", ││ "output_partitions": 4, ││ "rows": 28951, ││ "size_approx": "900.0KB", ││ "table": "logpush.requests", ││ "files": 7, ││ "bytes": 900019, ││ "projection": [ ││ "__ingest_ts", ││ "CPUTimeMs", ││ "DispatchNamespace", ││ "Entrypoint", ││ "Event", ││ "EventTimestampMs", ││ "EventType", ││ "Exceptions", ││ "Logs", ││ "Outcome", ││ "ScriptName", ││ "ScriptTags", ││ "ScriptVersion", ││ "WallTimeMs" ││ ], ││ "limit": 10 ││ } ││ ] ││ } │└──────────────────────────────────────┘For more details, refer to EXPLAIN.
Unpartitioned Iceberg tables can now be queried directly, which is useful for smaller datasets or data without natural time dimensions. For tables with more than 1000 files, partitioning is still recommended for better performance.
Refer to Limitations and best practices for the latest guidance on using R2 SQL.
@cf/moonshotai/kimi-k2.6is now available on Workers AI, in partnership with Moonshot AI for Day 0 support. Kimi K2.6 is a native multimodal agentic model from Moonshot AI that advances practical capabilities in long-horizon coding, coding-driven design, proactive autonomous execution, and swarm-based task orchestration.Built on a Mixture-of-Experts architecture with 1T total parameters and 32B active per token, Kimi K2.6 delivers frontier-scale intelligence with efficient inference. It scores competitively against GPT-5.4 and Claude Opus 4.6 on agentic and coding benchmarks, including BrowseComp (83.2), SWE-Bench Verified (80.2), and Terminal-Bench 2.0 (66.7).
- 262.1k token context window for retaining full conversation history, tool definitions, and codebases across long-running agent sessions
- Long-horizon coding with significant improvements on complex, end-to-end coding tasks across languages including Rust, Go, and Python
- Coding-driven design that transforms simple prompts and visual inputs into production-ready interfaces and full-stack workflows
- Agent swarm orchestration scaling horizontally to 300 sub-agents executing 4,000 coordinated steps for complex autonomous tasks
- Vision inputs for processing images alongside text
- Thinking mode with configurable reasoning depth
- Multi-turn tool calling for building agents that invoke tools across multiple conversation turns
If you are migrating from Kimi K2.5, note the following API changes:
- K2.6 uses
chat_template_kwargs.thinkingto control reasoning, replacingchat_template_kwargs.enable_thinking - K2.6 returns reasoning content in the
reasoningfield, replacingreasoning_content
Use Kimi K2.6 through the Workers AI binding (
env.AI.run()), the REST API at/ai/run, or the OpenAI-compatible endpoint at/v1/chat/completions. You can also use AI Gateway with any of these endpoints.For more information, refer to the Kimi K2.6 model page and pricing.
Cloudflare's network now supports redirecting verified AI training crawlers to canonical URLs when they request deprecated or duplicate pages. When enabled via AI Crawl Control > Quick Actions, AI training crawlers that request a page with a canonical tag pointing elsewhere receive a 301 redirect to the canonical version. Humans, search engine crawlers, and AI Search agents continue to see the original page normally.
This feature leverages your existing
<link rel="canonical">tags. No additional configuration required beyond enabling the toggle. Available on Pro, Business, and Enterprise plans at no additional cost.Refer to the Redirects for AI Training documentation for details.
AI Crawl Control now includes new tools to help you prepare your site for the agentic Internet—a web where AI agents are first-class citizens that discover and interact with content differently than human visitors.
The Metrics tab now includes a Content Format chart showing what content types AI systems request versus what your origin serves. Understanding these patterns helps you optimize content delivery for both human and agent consumption.
The Robots.txt tab has been renamed to Directives and now includes a link to check your site's Agent Readiness ↗ score.
Refer to our blog post on preparing for the agentic Internet ↗ for more on why these capabilities matter.
You can now achieve higher cache HIT rates and reduce origin load for origins hosted on public cloud providers with Smart Tiered Cache. By setting a cloud region hint for your origin, Cloudflare selects the optimal upper-tier data center for that cloud region, funneling all cache MISSes through a single location close to your origin.
Previously, Smart Tiered Cache could not reliably select an optimal upper tier for origins behind anycast or regional unicast networks commonly used by cloud providers. Origins on AWS, GCP, Azure, and Oracle Cloud would fall back to a multi-upper-tier topology, resulting in lower cache HIT rates and more requests reaching your origin.
Set a cloud region hint (for example,
aws/us-east-1orgcp/europe-west1) for your origin IP or hostname. Smart Tiered Cache uses this hint along with real-time latency data to select a primary upper tier close to your cloud region, plus a fallback in a different location for resilience.- Supported providers: AWS, GCP, Azure, and Oracle Cloud.
- All plans: Available on Free, Pro, Business, and Enterprise plans at no additional cost.
- Dashboard and API: Configure from Caching > Tiered Cache > Origin Configuration, or use the API and Terraform.
To get started, enable Smart Tiered Cache and set a cloud region hint for your origin in the Tiered Cache settings.