
-
Cloudflare now provides two new request fields in the Ruleset engine that let you make decisions based on whether a request used TCP and the measured TCP round-trip time between the client and Cloudflare. These fields help you understand protocol usage across your traffic and build policies that respond to network performance. For example, you can distinguish TCP from QUIC traffic or route high latency requests to alternative origins when needed.
Field Type Description cf.edge.client_tcpBoolean Indicates whether the request used TCP. A value of true means the client connected using TCP instead of QUIC. cf.timings.client_tcp_rtt_msecNumber Reports the smoothed TCP round-trip time between the client and Cloudflare in milliseconds. For example, a value of 20 indicates roughly twenty milliseconds of RTT. Example filter expression:
cf.edge.client_tcp && cf.timings.client_tcp_rtt_msec < 100More information can be found in the Rules language fields reference.
Logpush now supports integration with Microsoft Sentinel ↗.The new Azure Sentinel Connector built on Microsoft’s Codeless Connector Framework (CCF), is now avaialble. This solution replaces the previous Azure Functions-based connector, offering significant improvements in security, data control, and ease of use for customers. Logpush customers can send logs to Azure Blob Storage and configure this new Sentinel Connector to ingest those logs directly into Microsoft Sentinel.
This upgrade significantly streamlines log ingestion, improves security, and provides greater control:
- Simplified Implementation: Easier for engineering teams to set up and maintain.
- Cost Control: New support for Data Collection Rules (DCRs) allows you to filter and transform logs at ingestion time, offering potential cost savings.
- Enhanced Security: CCF provides a higher level of security compared to the older Azure Functions connector.
- ata Lake Integration: Includes native integration with Data Lake.
Find the new solution here ↗ and refer to the Cloudflare's developer documention ↗for more information on the connector, including setup steps, supported logs and Microsfot's resources.
AI Crawl Control now includes a Robots.txt tab that provides insights into how AI crawlers interact with your
robots.txtfiles.The Robots.txt tab allows you to:
- Monitor the health status of
robots.txtfiles across all your hostnames, including HTTP status codes, and identify hostnames that need arobots.txtfile. - Track the total number of requests to each
robots.txtfile, with breakdowns of successful versus unsuccessful requests. - Check whether your
robots.txtfiles contain Content Signals ↗ directives for AI training, search, and AI input. - Identify crawlers that request paths explicitly disallowed by your
robots.txtdirectives, including the crawler name, operator, violated path, specific directive, and violation count. - Filter
robots.txtrequest data by crawler, operator, category, and custom time ranges.
When you identify non-compliant crawlers, you can:
- Block the crawler in the Crawlers tab
- Create custom WAF rules for path-specific security
- Use Redirect Rules to guide crawlers to appropriate areas of your site
To get started, go to AI Crawl Control > Robots.txt in the Cloudflare dashboard. Learn more in the Track robots.txt documentation.
- Monitor the health status of
-
We're excited to announce a significant increase in the maximum header size supported by Cloudflare's Content Delivery Network (CDN). Cloudflare now supports up to 128 KB for both request and response headers.
Previously, customers were limited to a total of 32 KB for request or response headers, with a maximum of 16 KB per individual header. Larger headers could cause requests to fail with
HTTP 413(Request Header Fields Too Large) errors.
- Support for large headers: You can now utilize much larger headers, whether as a single large header up to 128 KB or split over multiple headers.
- Reduces
413and520HTTP errors: This change drastically reduces the likelihood of customers encounteringHTTP 413errors from large request headers orHTTP 520errors caused by oversized response headers, improving the overall reliability of your web applications. - Enhanced functionality: This is especially beneficial for applications that rely on:
- A large number of cookies.
- Large Content-Security-Policy (CSP) response headers.
- Advanced use cases with Cloudflare Workers that generate large response headers.
This enhancement improves compatibility with Cloudflare's CDN, enabling more use cases that previously failed due to header size limits.
To learn more and get started, refer to the Cloudflare Fundamentals documentation.
AI Crawl Control now provides enhanced metrics and CSV data exports to help you better understand AI crawler activity across your sites.
Visualize crawler activity patterns over time, and group data by different dimensions:
- By Crawler — Track activity from individual AI crawlers (GPTBot, ClaudeBot, Bytespider)
- By Category — Analyze crawler purpose or type
- By Operator — Discover which companies (OpenAI, Anthropic, ByteDance) are crawling your site
- By Host — Break down activity across multiple subdomains
- By Status Code — Monitor HTTP response codes to crawlers (200s, 300s, 400s, 500s)

Interactive chart showing crawler requests over time with filterable dimensions Identify traffic sources with referrer analytics:
- View top referrers driving traffic to your site
- Understand discovery patterns and content popularity from AI operators

Bar chart showing top referrers and their respective traffic volumes Download your filtered view as a CSV:
- Includes all applied filters and groupings
- Useful for custom reporting and deeper analysis
- Log in to the Cloudflare dashboard, and select your account and domain.
- Go to AI Crawl Control > Metrics.
- Use the grouping tabs to explore different views of your data.
- Apply filters to focus on specific crawlers, time ranges, or response codes.
- Select Download CSV to export your filtered data for further analysis.
Learn more about AI Crawl Control.
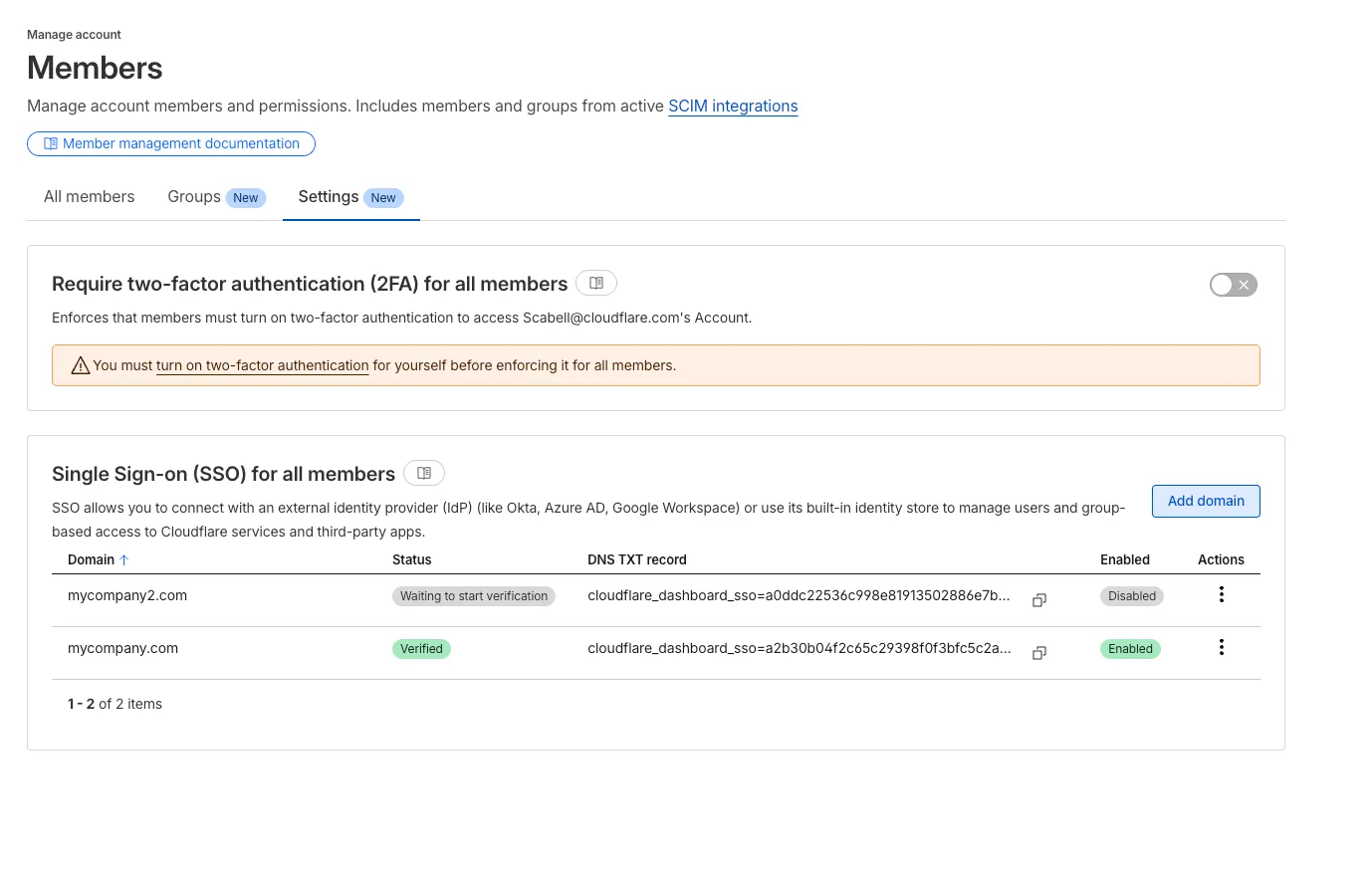
During Birthday Week, we announced that single sign-on (SSO) is available for free ↗ to everyone who signs in with a custom email domain and maintains a compatible identity provider ↗. SSO minimizes user friction around login and provides the strongest security posture available. At the time, this could only be configured using the API.
Today, we are launching a new user experience which allows users to manage their SSO configuration from within the Cloudflare dashboard. You can access this by going to Manage account > Members > Settings.
The most common reason users contact Cloudflare support is lost two-factor authentication (2FA) credentials. Cloudflare supports both app-based and hardware keys for 2FA, but you could lose access to your account if you lose these. Over the past few weeks, we have been rolling out email and in-product reminders that remind you to also download backup codes (sometimes called recovery keys) that can get you back into your account in the event you lose your 2FA credentials. Download your backup codes now by logging into Cloudflare, then navigating to Profile > Security & Authentication > Backup codes.
Cloudflare is critical infrastructure, and you should protect it as such. Please review the following best practices and make sure you are doing your part to secure your account.
- Use a unique password for every website, including Cloudflare, and store it in a password manager like 1Password or Keeper. These services are cross-platform and simplify the process of managing secure passwords.
- Use 2FA to make it harder for an attacker to get into your account in the event your password is leaked
- Store your backup codes securely. A password manager is the best place since it keeps the backup codes encrypted, but you can also print them and put them somewhere safe in your home.
- If you use an app to manage your 2FA keys, enable cloud backup, so that you don't lose your keys in the event you lose your phone.
- If you use a custom email domain to sign in, configure SSO ↗.
- If you use a public email domain like Gmail or Hotmail, you can also use social login with Apple, GitHub, or Google to sign in.
- If you manage a Cloudflare account for work:
- Have at least two administrators in case one of them unexpectedly leaves your company
- Use SCIM to automate permissions management for members in your Cloudflare account
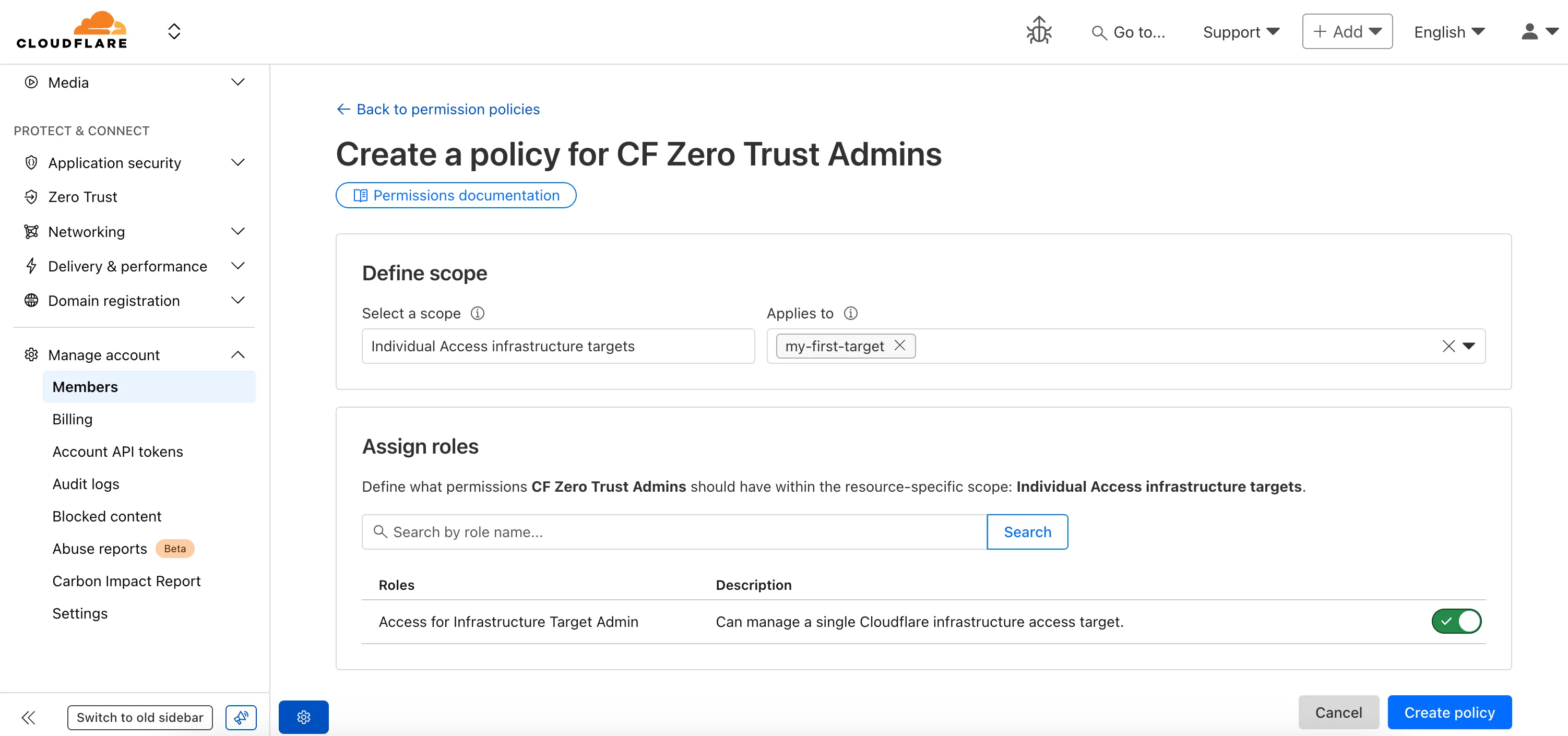
Fine-grained permissions for Access Applications, Identity Providers (IdPs), and Targets is now available in Public Beta. This expands our RBAC model beyond account & zone-scoped roles, enabling administrators to grant permissions scoped to individual resources.
- Access Applications ↗: Grant admin permissions to specific Access Applications.
- Identity Providers ↗: Grant admin permissions to individual Identity Providers.
- Targets ↗: Grant admin rights to specific Targets
For more info:
The GraphQL Analytics API now supports confidence intervals for
sumandcountfields on adaptive (sampled) datasets. Confidence intervals provide a statistical range around sampled results, helping verify accuracy and quantify uncertainty.- Supported datasets: Adaptive (sampled) datasets only.
- Supported fields: All
sumandcountfields. - Usage: The confidence
levelmust be provided as a decimal between 0 and 1 (e.g.0.90,0.95,0.99). - Default: If no confidence level is specified, no intervals are returned.
For examples and more details, see the GraphQL Analytics API documentation.
Users can now specify that they want to retrieve Cloudflare documentation as markdown rather than the previous HTML default. This can significantly reduce token consumption when used alongside Large Language Model (LLM) tools.
Terminal window curl https://developers.cloudflare.com/workers/ -H 'Accept: text/markdown' -vIf you maintain your own site and want to adopt this practice using Cloudflare Workers for your own users you can follow the example here ↗.
Cloudflare has launched sign in with GitHub as a log in option. This feature is available to all users with a verified email address who are not using SSO. To use it, simply click on the
Sign in with GitHubbutton on the dashboard login page. You will be logged in with your primary GitHub email address.
Single sign-on (SSO) streamlines the process of logging into Cloudflare for Enterprise customers who manage a custom email domain and manage their own identity provider. Instead of managing a password and two-factor authentication credentials directly for Cloudflare, SSO lets you reuse your existing login infrastructure to seamlessly log in. SSO also provides additional security opportunities such as device health checks which are not available natively within Cloudflare.
Historically, SSO was only available for Enterprise accounts. Today, we are announcing that we are making SSO available to all users for free. We have also added the ability to directly manage SSO configurations using the API. This removes the previous requirement to contact support to configure SSO.
You can now route private traffic to Cloudflare Tunnel based on a hostname or domain, moving beyond the limitations of IP-based routing. This new capability is free for all Cloudflare One customers.
Previously, Tunnel routes could only be defined by IP address or CIDR range. This created a challenge for modern applications with dynamic or ephemeral IP addresses, often forcing administrators to maintain complex and brittle IP lists.
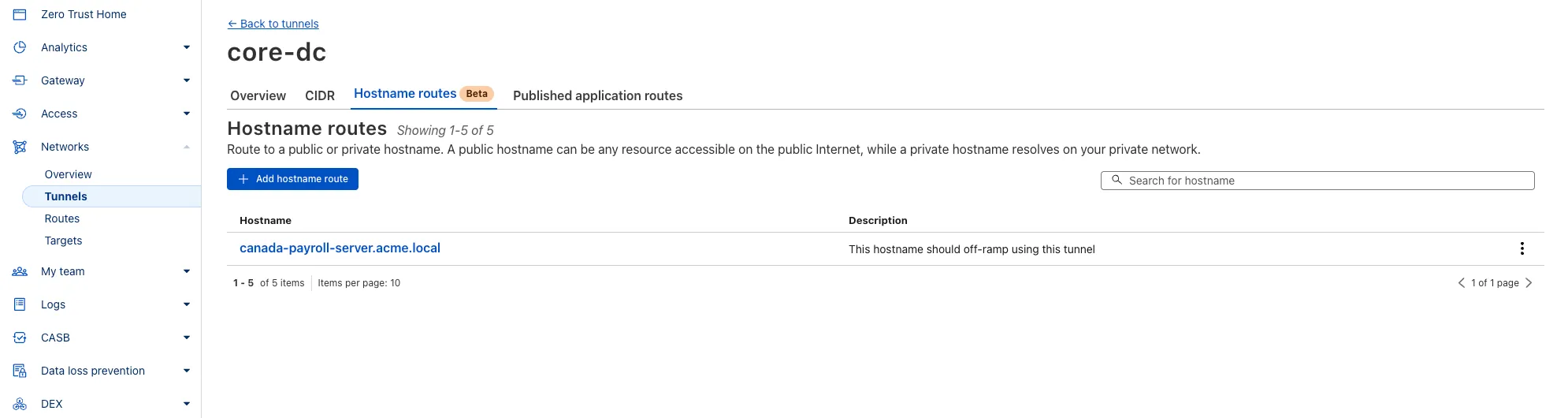
What’s new:
- Hostname & Domain Routing: Create routes for individual hostnames (e.g.,
payroll.acme.local) or entire domains (e.g.,*.acme.local) and direct their traffic to a specific Tunnel. - Simplified Zero Trust Policies: Build resilient policies in Cloudflare Access and Gateway using stable hostnames, making it dramatically easier to apply per-resource authorization for your private applications.
- Precise Egress Control: Route traffic for public hostnames (e.g.,
bank.example.com) through a specific Tunnel to enforce a dedicated source IP, solving the IP allowlist problem for third-party services. - No More IP Lists: This feature makes the workaround of maintaining dynamic IP Lists for Tunnel connections obsolete.
Get started in the Tunnels section of the Zero Trust dashboard with your first private hostname or public hostname route.
Learn more in our blog post ↗.
- Hostname & Domain Routing: Create routes for individual hostnames (e.g.,
Directly from Log Search results, customers can pivot to other parts of the Cloudflare dashboard to immediately take action as a result of their investigation.
From the
http_requestsorfw_eventsdataset results, right click on an IP Address or JA3 Fingerprint to pivot to the Investigate portal to lookup the reputation of an IP address or JA3 fingerprint.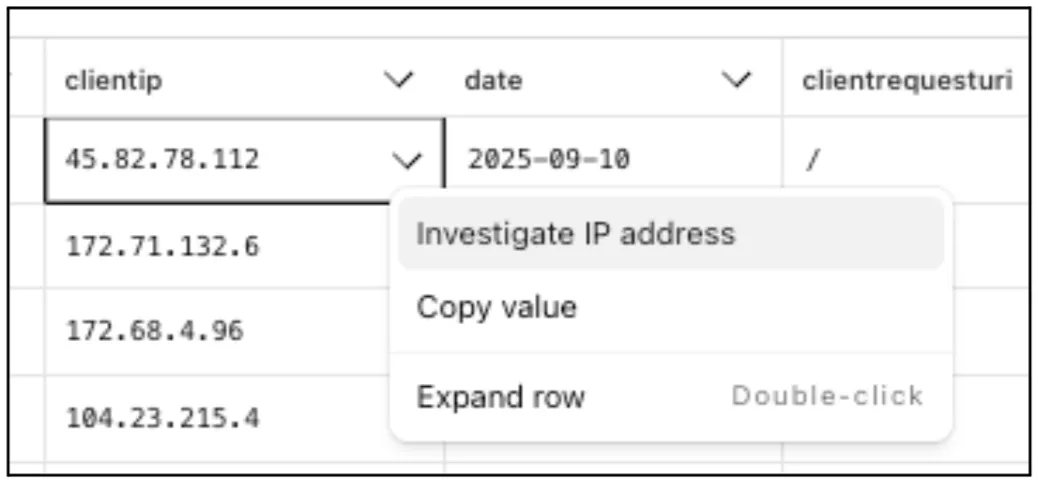
Easily learn about error codes by linking directly to our documentation from the EdgeResponseStatus or OriginResponseStatus fields.
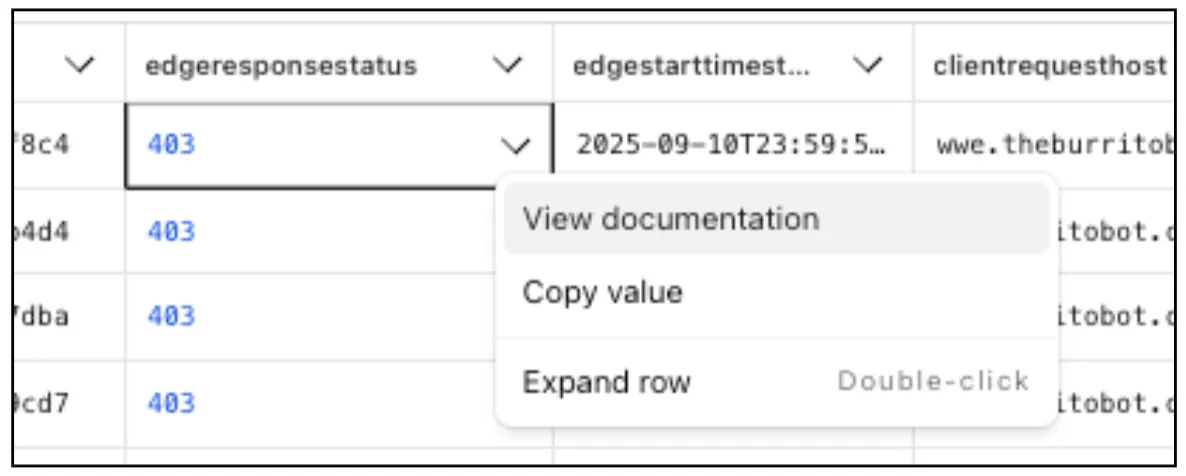
From the
gateway_httpdataset, click on a policyid to link directly to the Zero Trust dashboard to review or make changes to a specific Gateway policy.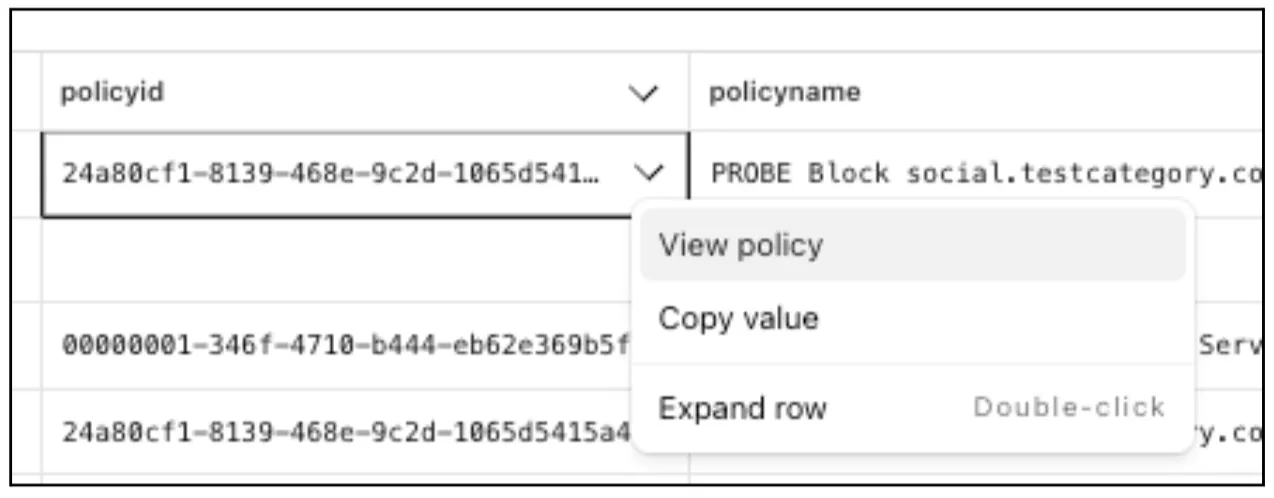
The results table view of Log Search has been updated with additional functionality and a more streamlined user experience. Users can now easily:
- Remove/add columns.
- Resize columns.
- Sort columns.
- Copy values from any field.

Two-factor authentication is the best way to help protect your account from account takeovers, but if you lose your second factor, you could be locked out of your account. Lock outs are one of the top reasons customers contact Cloudflare support, and our policies often don't allow us to bypass two-factor authentication for customers that are locked out. Today we are releasing an improvement where Cloudflare will periodically remind you to securely save your backup codes so you don't get locked out in the future.
Cloudflare's API now supports rate limiting headers using the pattern developed by the IETF draft on rate limiting ↗. This allows API consumers to know how many more calls are left until the rate limit is reached, as well as how long you will need to wait until more capacity is available.
Our SDKs automatically work with these new headers, backing off when rate limits are approached. There is no action required for users of the latest Cloudflare SDKs to take advantage of this.
As always, if you need any help with rate limits, please contact Support.
Headers that are always returned:
Ratelimit: List of service limit items, composed of the limit name, the remaining quota (r) and the time next window resets (t). For example:"default";r=50;t=30Ratelimit-Policy: List of quota policy items, composed of the policy name, the total quota (q) and the time window the quota applies to (w). For example:"burst";q=100;w=60
Returned only when a rate limit has been reached (error code: 429):
- Retry-After: Number of Seconds until more capacity is available, rounded up
- All of Cloudflare's latest SDKs will automatically respond to the headers, instituting a backoff when limits are approached.
These new headers and back offs are only available for Cloudflare REST APIs, and will not affect GraphQL.
Log Explorer now supports logging and filtering on header or cookie fields in the
http_requestsdataset.Create a custom field to log desired header or cookie values into the
http_requestsdataset and Log Explorer will import these as searchable fields. Once configured, use the custom SQL editor in Log Explorer to view or filter on these requests.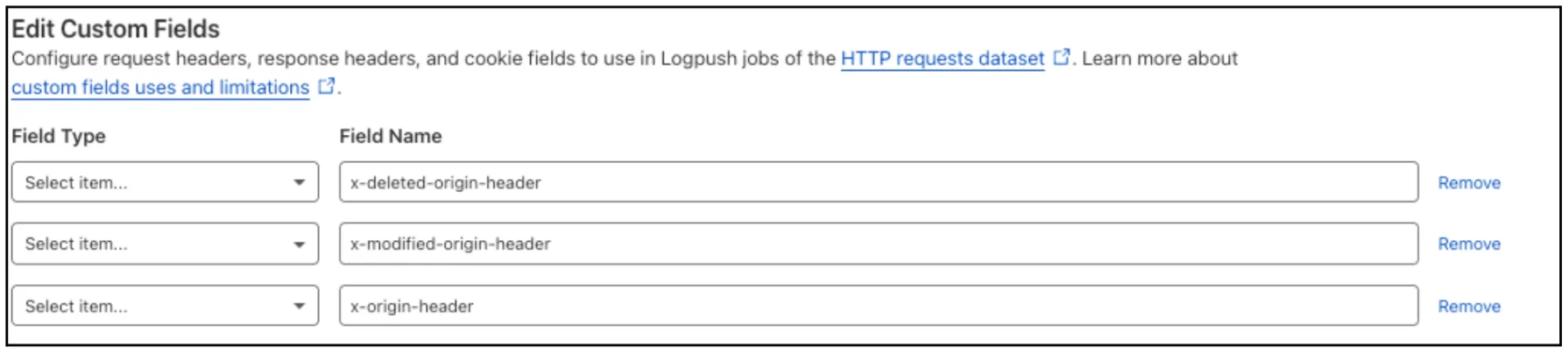
For more details, refer to Headers and cookies.
Starting December 1, 2025, list endpoints for the Cloudflare Tunnel API and Zero Trust Networks API will no longer return deleted tunnels, routes, subnets and virtual networks by default. This change makes the API behavior more intuitive by only returning active resources unless otherwise specified.
No action is required if you already explicitly set
is_deleted=falseor if you only need to list active resources.This change affects the following API endpoints:
- List all tunnels:
GET /accounts/{account_id}/tunnels - List Cloudflare Tunnels:
GET /accounts/{account_id}/cfd_tunnel - List WARP Connector tunnels:
GET /accounts/{account_id}/warp_connector - List tunnel routes:
GET /accounts/{account_id}/teamnet/routes - List subnets:
GET /accounts/{account_id}/zerotrust/subnets - List virtual networks:
GET /accounts/{account_id}/teamnet/virtual_networks
The default behavior of the
is_deletedquery parameter will be updated.Scenario Previous behavior (before December 1, 2025) New behavior (from December 1, 2025) is_deletedparameter is omittedReturns active & deleted tunnels, routes, subnets and virtual networks Returns only active tunnels, routes, subnets and virtual networks If you need to retrieve deleted (or all) resources, please update your API calls to explicitly include the
is_deletedparameter before December 1, 2025.To get a list of only deleted resources, you must now explicitly add the
is_deleted=truequery parameter to your request:Terminal window # Example: Get ONLY deleted Tunnelscurl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/tunnels?is_deleted=true" \-H "Authorization: Bearer $API_TOKEN"# Example: Get ONLY deleted Virtual Networkscurl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/teamnet/virtual_networks?is_deleted=true" \-H "Authorization: Bearer $API_TOKEN"Following this change, retrieving a complete list of both active and deleted resources will require two separate API calls: one to get active items (by omitting the parameter or using
is_deleted=false) and one to get deleted items (is_deleted=true).This update is based on user feedback and aims to:
- Create a more intuitive default: Aligning with common API design principles where list operations return only active resources by default.
- Reduce unexpected results: Prevents users from accidentally operating on deleted resources that were returned unexpectedly.
- Improve performance: For most users, the default query result will now be smaller and more relevant.
To learn more, please visit the Cloudflare Tunnel API and Zero Trust Networks API documentation.
- List all tunnels:
Earlier this year, we announced the launch of the new Terraform v5 Provider. We are aware of the high number of issues ↗ reported by the Cloudflare community related to the v5 release. We have committed to releasing improvements on a 2 week cadence to ensure its stability and reliability, including the v5.9 release. We have also pivoted from an issue-to-issue approach to a resource-per-resource approach - we will be focusing on specific resources for every release, stabilizing the release, and closing all associated bugs with that resource before moving onto resolving migration issues.
Thank you for continuing to raise issues. We triage them weekly and they help make our products stronger.
This release includes a new resource,
cloudflare_snippet, which replacescloudflare_snippets.cloudflare_snippetis now considered deprecated but can still be used. Please utilizecloudflare_snippetas soon as possible.- Resources stabilized:
cloudflare_zone_settingcloudflare_worker_scriptcloudflare_worker_routetiered_cache
- NEW resource
cloudflare_snippetwhich should be used in place ofcloudflare_snippets.cloudflare_snippetsis now deprecated. This enables the management of Cloudflare's snippet functionality through Terraform. - DNS Record Improvements: Enhanced handling of DNS record drift detection
- Load Balancer Fixes: Resolved
created_onfield inconsistencies and improved pool configuration handling - Bot Management: Enhanced auto-update model state consistency and fight mode configurations
- Other bug fixes
For a more detailed look at all of the changes, refer to the changelog ↗ in GitHub.
- #5921: In cloudflare_ruleset removing an existing rule causes recreation of later rules ↗
- #5904: cloudflare_zero_trust_access_application is not idempotent ↗
- #5898: (cloudflare_workers_script) Durable Object migrations not applied ↗
- #5892: cloudflare_workers_script secret_text environment variable gets replaced on every deploy ↗
- #5891: cloudflare_zone suddenly started showing drift ↗
- #5882: cloudflare_zero_trust_list always marked for change due to read only attributes ↗
- #5879: cloudflare_zero_trust_gateway_certificate unable to manage resource (cant mark as active/inactive) ↗
- #5858: cloudflare_dns_records is always updated in-place ↗
- #5839: Recurring change on cloudflare_zero_trust_gateway_policy after upgrade to V5 provider & also setting expiration fails ↗
- #5811: Reusable policies are imported as inline type for cloudflare_zero_trust_access_application ↗
- #5795: cloudflare_zone_setting inconsistent value of "editable" upon apply ↗
- #5789: Pagination issue fetching all policies in "cloudflare_zero_trust_access_policies" data source ↗
- #5770: cloudflare_zero_trust_access_application type warp diff on every apply ↗
- #5765: V5 / cloudflare_zone_dnssec fails with HTTP/400 "Malformed request body" ↗
- #5755: Unable to manage Cloudflare managed WAF rules via Terraform ↗
- #5738: v4 to v5 upgrade failing Error: no schema available AND Unable to Read Previously Saved State for UpgradeResourceState ↗
- #5727: cloudflare_ruleset http_request_cache_settings bypass mismatch between dashboard and terraform ↗
- #5700: cloudflare_account_member invalid type 'string' for field 'roles' ↗
If you have an unaddressed issue with the provider, we encourage you to check the open issues ↗ and open a new issue if one does not already exist for what you are experiencing.
We suggest holding off on migration to v5 while we work on stabilization. This help will you avoid any blocking issues while the Terraform resources are actively being stabilized.
If you'd like more information on migrating from v4 to v5, please make use of the migration guide ↗. We have provided automated migration scripts using Grit which simplify the transition. These do not support implementations which use Terraform modules, so customers making use of modules need to migrate manually. Please make use of
terraform planto test your changes before applying, and let us know if you encounter any additional issues by reporting to our GitHub repository ↗.- Resources stabilized:
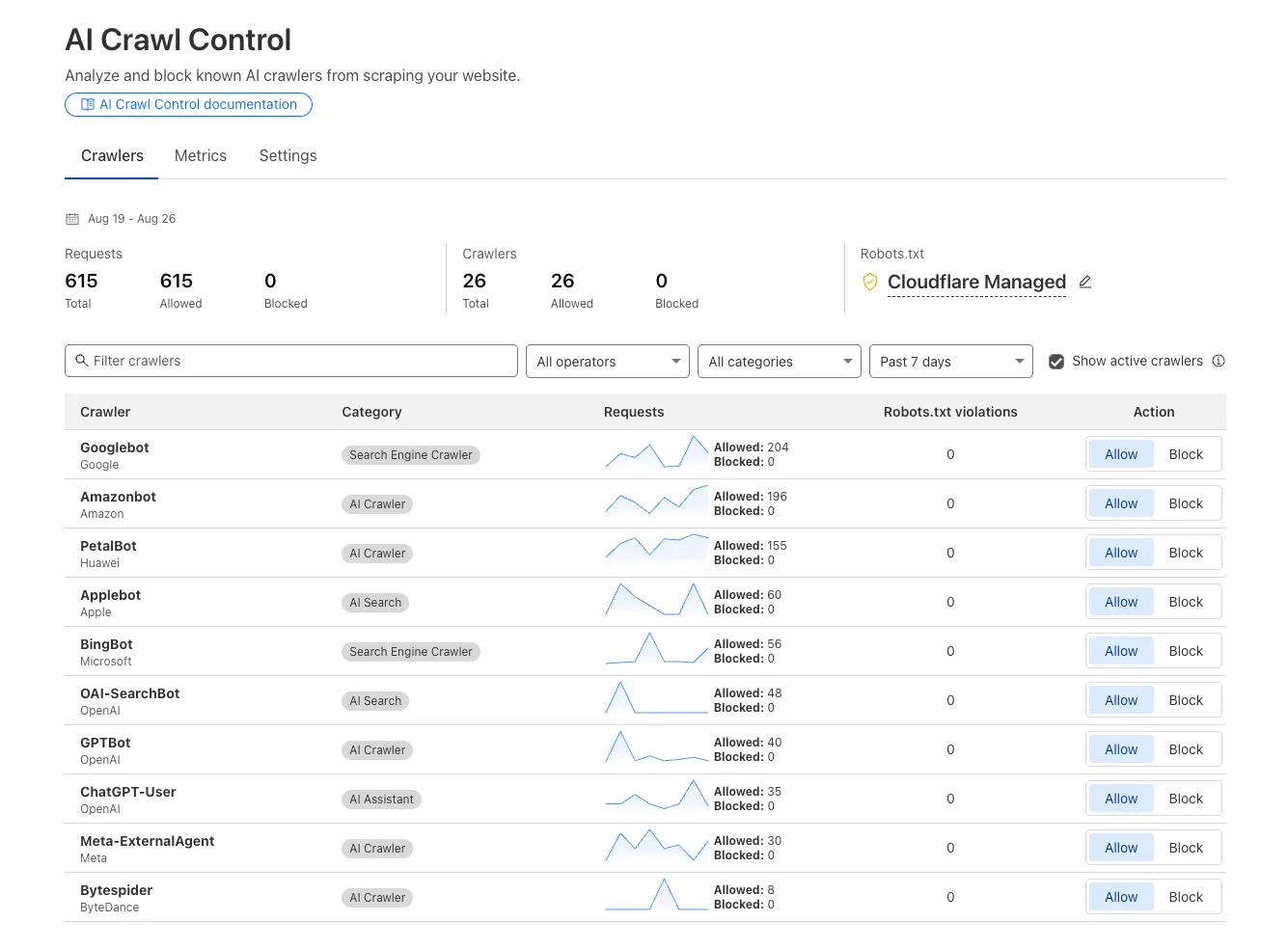
We improved AI crawler management with detailed analytics and introduced custom HTTP 402 responses for blocked crawlers. AI Audit has been renamed to AI Crawl Control and is now generally available.
Enhanced Crawlers tab:
- View total allowed and blocked requests for each AI crawler
- Trend charts show crawler activity over your selected time range per crawler
Custom block responses (paid plans): You can now return HTTP 402 "Payment Required" responses when blocking AI crawlers, enabling direct communication with crawler operators about licensing terms.
For users on paid plans, when blocking AI crawlers you can configure:
- Response code: Choose between 403 Forbidden or 402 Payment Required
- Response body: Add a custom message with your licensing contact information
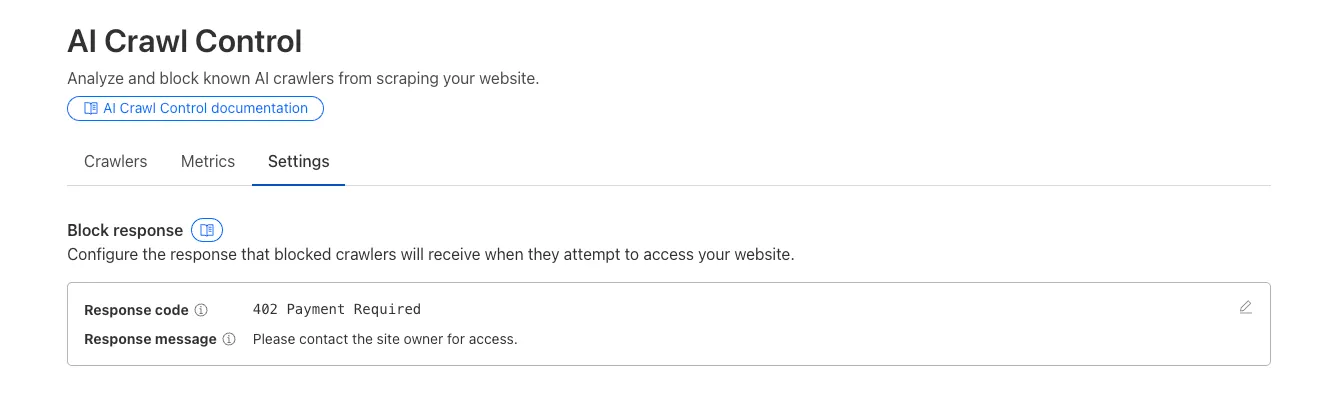
Example 402 response:
HTTP 402 Payment RequiredDate: Mon, 24 Aug 2025 12:56:49 GMTContent-type: application/jsonServer: cloudflareCf-Ray: 967e8da599d0c3fa-EWRCf-Team: 2902f6db750000c3fa1e2ef400000001{"message": "Please contact the site owner for access."}
Audit Logs v2 dataset is now available via Logpush.
This expands on earlier releases of Audit Logs v2 in the API and Dashboard UI.
We recommend creating a new Logpush job for the Audit Logs v2 dataset.
Timelines for General Availability (GA) of Audit Logs v2 and the retirement of Audit Logs v1 will be shared in upcoming updates.
For more details on Audit Logs v2, refer to the Audit Logs documentation ↗.
Cloudflare Logpush can now deliver logs from using fixed, dedicated egress IPs. By routing Logpush traffic through a Cloudflare zone enabled with Aegis IP, your log destination only needs to allow Aegis IPs making setup more secure.
Highlights:
- Fixed egress IPs ensure your destination only accepts traffic from known addresses.
- Works with any supported Logpush destination.
- Recommended to use a dedicated zone as a proxy for easier management.
To get started, work with your Cloudflare account team to provision Aegis IPs, then configure your Logpush job to deliver logs through the proxy zone. For full setup instructions, refer to the Logpush documentation.
Customers can now rely on Log Explorer to meet their log retention compliance requirements.
Contract customers can choose to store their logs in Log Explorer for up to two years, at an additional cost of $0.10 per GB per month. Customers interested in this feature can contact their account team to have it added to their contract.
Earlier this year, we announced the launch of the new Terraform v5 Provider. We are aware of the high number of issues ↗ reported by the Cloudflare Community related to the v5 release. We have committed to releasing improvements on a two week cadence to ensure stability and reliability.
One key change we adopted in recent weeks is a pivot to more comprehensive, test-driven development. We are still evaluating individual issues, but are also investing in much deeper testing to drive our stabilization efforts. We will subsequently be investing in comprehensive migration scripts. As a result, you will see several of the highest traffic APIs have been stabilized in the most recent release, and are supported by comprehensive acceptance tests.
Thank you for continuing to raise issues. We triage them weekly and they help make our products stronger.
- Resources stabilized:
cloudflare_argo_smart_routingcloudflare_bot_managementcloudflare_listcloudflare_list_itemcloudflare_load_balancercloudflare_load_balancer_monitorcloudflare_load_balancer_poolcloudflare_spectrum_applicationcloudflare_managed_transformscloudflare_url_normalization_settingscloudflare_snippetcloudflare_snippet_rulescloudflare_zero_trust_access_applicationcloudflare_zero_trust_access_groupcloudflare_zero_trust_access_identity_providercloudflare_zero_trust_access_mtls_certificatecloudflare_zero_trust_access_mtls_hostname_settingscloudflare_zero_trust_access_policycloudflare_zone
- Multipart handling restored for
cloudflare_snippet cloudflare_bot_managementdiff issues resolves when runningterraform planandterraform apply- Other bug fixes
For a more detailed look at all of the changes, refer to the changelog ↗ in GitHub.
- #5017: 'Uncaught Error: No such module' using cloudflare_snippets ↗
- #5701: cloudflare_workers_script migrations for Durable Objects not recorded in tfstate; cannot be upgraded between versions ↗
- #5640: cloudflare_argo_smart_routing importing doesn't read the actual value ↗
If you have an unaddressed issue with the provider, we encourage you to check the open issues ↗ and open a new one if one does not already exist for what you are experiencing.
We suggest holding off on migration to v5 while we work on stabilization. This will help you avoid any blocking issues while the Terraform resources are actively being stabilized.
If you'd like more information on migrating to v5, please make use of the migration guide ↗. We have provided automated migration scripts using Grit which simplify the transition. These migration scripts do not support implementations which use Terraform modules, so customers making use of modules need to migrate manually. Please make use of
terraform planto test your changes before applying, and let us know if you encounter any additional issues by reporting to our GitHub repository ↗.- Resources stabilized: