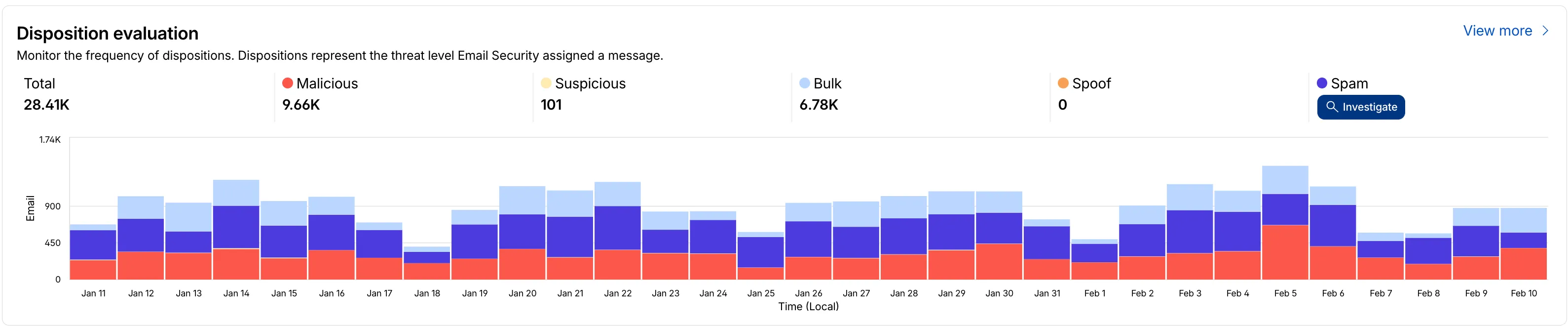
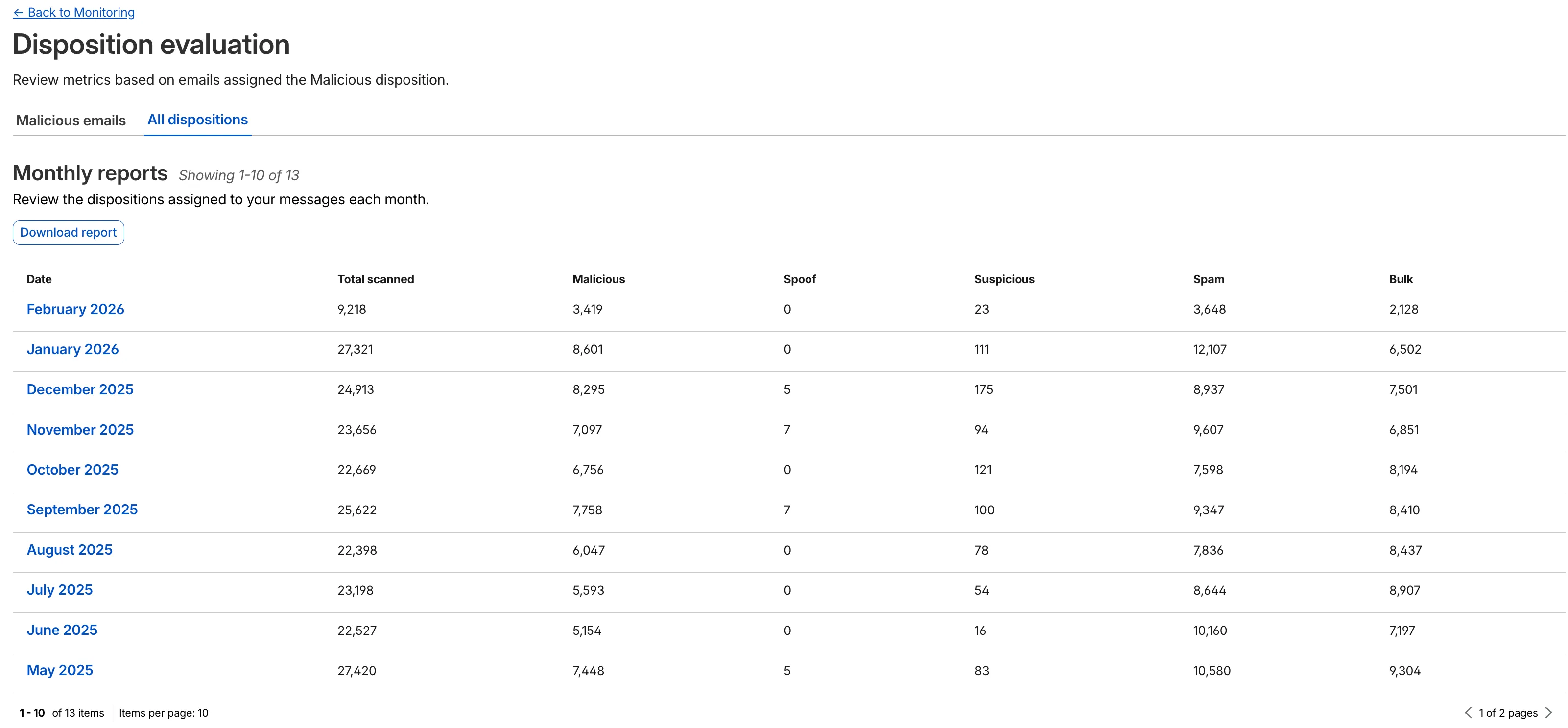
Introducing GLM-4.7-Flash on Workers AI, @cloudflare/tanstack-ai, and workers-ai-provider v3.1.1
We're excited to announce GLM-4.7-Flash on Workers AI, a fast and efficient text generation model optimized for multilingual dialogue and instruction-following tasks, along with the brand-new @cloudflare/tanstack-ai ↗ package and workers-ai-provider v3.1.1 ↗.
You can now run AI agents entirely on Cloudflare. With GLM-4.7-Flash's multi-turn tool calling support, plus full compatibility with TanStack AI and the Vercel AI SDK, you have everything you need to build agentic applications that run completely at the edge.
@cf/zai-org/glm-4.7-flash is a multilingual model with a 131,072 token context window, making it ideal for long-form content generation, complex reasoning tasks, and multilingual applications.
Key Features and Use Cases:
- Multi-turn Tool Calling for Agents: Build AI agents that can call functions and tools across multiple conversation turns
- Multilingual Support: Built to handle content generation in multiple languages effectively
- Large Context Window: 131,072 tokens for long-form writing, complex reasoning, and processing long documents
- Fast Inference: Optimized for low-latency responses in chatbots and virtual assistants
- Instruction Following: Excellent at following complex instructions for code generation and structured tasks
Use GLM-4.7-Flash through the Workers AI binding (env.AI.run()), the REST API at /run or /v1/chat/completions, AI Gateway, or via workers-ai-provider for the Vercel AI SDK.
Pricing is available on the model page or pricing page.
We've released @cloudflare/tanstack-ai, a new package that brings Workers AI and AI Gateway support to TanStack AI ↗. This provides a framework-agnostic alternative for developers who prefer TanStack's approach to building AI applications.
Workers AI adapters support four configuration modes — plain binding (env.AI), plain REST, AI Gateway binding (env.AI.gateway(id)), and AI Gateway REST — across all capabilities:
- Chat (
createWorkersAiChat) — Streaming chat completions with tool calling, structured output, and reasoning text streaming. - Image generation (
createWorkersAiImage) — Text-to-image models. - Transcription (
createWorkersAiTranscription) — Speech-to-text. - Text-to-speech (
createWorkersAiTts) — Audio generation. - Summarization (
createWorkersAiSummarize) — Text summarization.
AI Gateway adapters route requests from third-party providers — OpenAI, Anthropic, Gemini, Grok, and OpenRouter — through Cloudflare AI Gateway for caching, rate limiting, and unified billing.
To get started:
npm install @cloudflare/tanstack-ai @tanstack/aiThe Workers AI provider for the Vercel AI SDK ↗ now supports three new capabilities beyond chat and image generation:
- Transcription (
provider.transcription(model)) — Speech-to-text with automatic handling of model-specific input formats across binding and REST paths. - Text-to-speech (
provider.speech(model)) — Audio generation with support for voice and speed options. - Reranking (
provider.reranking(model)) — Document reranking for RAG pipelines and search result ordering.
import { createWorkersAI } from "workers-ai-provider";
import {
experimental_transcribe,
experimental_generateSpeech,
rerank,
} from "ai";
const workersai = createWorkersAI({ binding: env.AI });
const transcript = await experimental_transcribe({
model: workersai.transcription("@cf/openai/whisper-large-v3-turbo"),
audio: audioData,
mediaType: "audio/wav",
});
const speech = await experimental_generateSpeech({
model: workersai.speech("@cf/deepgram/aura-1"),
text: "Hello world",
voice: "asteria",
});
const ranked = await rerank({
model: workersai.reranking("@cf/baai/bge-reranker-base"),
query: "What is machine learning?",
documents: ["ML is a branch of AI.", "The weather is sunny."],
});This release also includes a comprehensive reliability overhaul (v3.0.5):
- Fixed streaming — Responses now stream token-by-token instead of buffering all chunks, using a proper
TransformStreampipeline with backpressure. - Fixed tool calling — Resolved issues with tool call ID sanitization, conversation history preservation, and a heuristic that silently fell back to non-streaming mode when tools were defined.
- Premature stream termination detection — Streams that end unexpectedly now report
finishReason: "error"instead of silently reporting"stop". - AI Search support — Added
createAISearchas the canonical export (renamed from AutoRAG).createAutoRAGstill works with a deprecation warning.
To upgrade:
npm install workers-ai-provider@latest ai