Monitors
A monitor issues health monitor requests at regular intervals to evaluate the health of each endpoint within a pool.
When a pool becomes unhealthy, your load balancer takes that pool out of the endpoint rotation.
flowchart RL
accTitle: Load balancing monitor flow
accDescr: Monitors issue health monitor requests, which validate the current status of servers within each pool.
Monitor -- Health Monitor ----> Endpoint2
Endpoint2 -- Response ----> Monitor
subgraph Pool
Endpoint1((Endpoint 1))
Endpoint2((Endpoint 2))
end
Health monitor requests that result in a status change for an endpoint are recorded as events in the Load Balancing event logs.
For an up-to-date list of monitor properties, refer to Monitor properties in our API documentation.
For step-by-step guidance, refer to Create monitors.
Monitor Groups let you combine multiple health monitors into a single logical group to create more accurate, intelligent health checks for your applications. By aggregating results from several monitors, you can better reflect real application health and improve traffic steering resilience. For more details, refer to the Monitor Groups documentation page.
When you attach a monitor to a pool, you can select multiple regions to increase reporting accuracy.
For each option selected in a pool's Health Monitor Regions, Cloudflare sends health monitor requests from three separate data centers in that region.
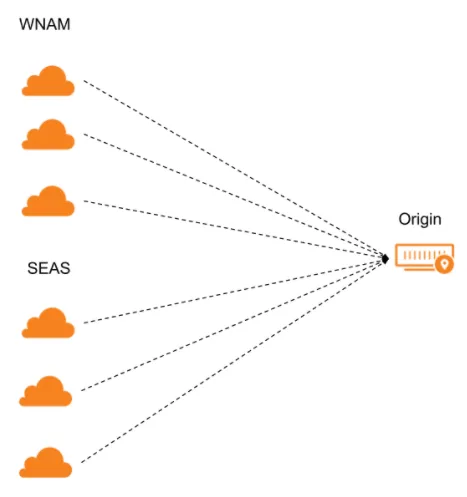
If the majority of data centers for that region pass the health monitor requests, that region is considered healthy. If the majority of regions is healthy, then the endpoint itself will be considered healthy.
All Data Centers (Enterprise only)
Health monitor probes are sent from every single data center in Cloudflare’s network to the endpoints within the associated pool. This allows probes to hit each endpoint during intervals set by the customer.
All Regions
Three health monitor probes per region are sent to each endpoint in the associated pool. There are a total of 13 regions, resulting in 39 probes.
Regional
Three health monitor probes are sent from each specified region within the pool configuration.
The host headers used on health monitor requests can be configured either on the monitor itself or on the endpoints within a pool.
When a host header is specified both on the monitor and on the endpoint, the host header configured on the endpoint takes precedence over the host header configured on the monitor.
When no host header is specified, Cloudflare uses the Endpoint Address configured on the endpoints as the host header for the health monitor requests.
For more details, refer to Override HTTP Host headers.
The Cloudflare API supports the following commands for monitors. Examples are given for user-level endpoint but apply to the account-level endpoint as well.
| Command | Method | Endpoint |
|---|---|---|
| Create Monitor | POST | accounts/:account_id/load_balancers/monitors |
| Delete Monitor | DELETE | accounts/:account_id/load_balancers/monitors/:id |
| List Monitors | GET | accounts/:account_id/load_balancers/monitors |
| Monitor Details | GET | accounts/:account_id/load_balancers/monitors/:id |
| Overwrite specific properties | PATCH | accounts/:account_id/load_balancers/monitors/:id |
| Overwrite existing monitor | PUT | accounts/:account_id/load_balancers/monitors/:id |
| Preview Monitor | POST | accounts/:account_id/load_balancers/monitors/:id/preview |
The following table summarizes the different types of monitors available in Cloudflare Load Balancing, their monitoring types, and how each health check process evaluates the success criteria to determine endpoint health:
| Monitor type | Monitoring type | Description | Health check process | Success criteria |
|---|---|---|---|---|
| HTTP/HTTPS | Public and private | Used for HTTP and HTTPS endpoints with specific protocol attributes. | The probe is configured with settings and success criteria such as Method, Simulate Zone, Follow Redirects, Request Headers, and Response Body. The probe then evaluates the configured success criteria using the HTTP protocol. Throughout the configured timeout period, the TCP connection is kept active using keep-alives, even if no response is received. | Success is based on meeting the configured HTTP success criteria. No response within the configured timeout and retries is considered unhealthy. |
| TCP | Public and private | Checks TCP connectivity by attempting to open a connection to the endpoint. | The monitor sends a TCP SYN message to the specified port. A successful health check requires receiving a SYN/ACK message to establish the connection. The connection is closed by sending a FIN or RST packet, or by receiving a FIN packet from the endpoint. | Failure to establish a TCP connection within the configured timeout and retries is considered unhealthy. |
| ICMP Ping | Public and Tunnel | Confirms basic Layer 3 (L3) connectivity to the endpoint using ICMP. The endpoints need to be allowed to reply to ICMP packets and any intervening networking equipment must support ICMP. | The monitor sends an ICMP/ICMPv6 echo request (ping) and expects an ICMP/ICMPv6 echo reply from the endpoint. | The endpoint must reply to the ICMP ping within the configured timeout and retries to be considered healthy. |
| UDP-ICMP | Public and Tunnel | UDP-ICMP monitor works by sending a UDP probe packet after ICMP Ping monitor completes as healthy. | After receiving a successful ICMP reply, the monitor sends a UDP probe packet to the endpoint. If no ICMP Port Unreachable message is received, the endpoint is considered healthy. | If the monitor receives an ICMP Port Unreachable message within the configured timeout and retries, the endpoint is considered unhealthy. |
| SMTP | Public | Verifies SMTP availability at the application layer. | The monitor establishes a TCP connection and sends an SMTP HELO command. It expects a reply with code 250. The monitor then sends an SMTP QUIT command, expecting a reply with code 221. At the end of each interval, the TCP connection is closed by sending a TCP FIN packet. | The endpoint must respond with correct SMTP codes (250 for HELO, 221 for QUIT) within the configured timeout and retries to be considered healthy. |