
Durable Objects can now be used with zero commitment on the Workers Free plan allowing you to build AI agents with Agents SDK, collaboration tools, and real-time applications like chat or multiplayer games.
Durable Objects let you build stateful, serverless applications with millions of tiny coordination instances that run your application code alongside (in the same thread!) your durable storage. Each Durable Object can access its own SQLite database through a Storage API. A Durable Object class is defined in a Worker script encapsulating the Durable Object's behavior when accessed from a Worker. To try the code below, click the button:
JavaScript import { DurableObject } from "cloudflare:workers";// Durable Objectexport class MyDurableObject extends DurableObject {...async sayHello(name) {return `Hello, ${name}!`;}}// Workerexport default {async fetch(request, env) {// Every unique ID refers to an individual instance of the Durable Object classconst id = env.MY_DURABLE_OBJECT.idFromName("foo");// A stub is a client used to invoke methods on the Durable Objectconst stub = env.MY_DURABLE_OBJECT.get(id);// Methods on the Durable Object are invoked via the stubconst response = await stub.sayHello("world");return response;},};Free plan limits apply to Durable Objects compute and storage usage. Limits allow developers to build real-world applications, with every Worker request able to call a Durable Object on the free plan.
For more information, checkout:
SQLite in Durable Objects is now generally available (GA) with 10GB SQLite database per Durable Object. Since the public beta ↗ in September 2024, we've added feature parity and robustness for the SQLite storage backend compared to the preexisting key-value (KV) storage backend for Durable Objects.
SQLite-backed Durable Objects are recommended for all new Durable Object classes, using
new_sqlite_classesWrangler configuration. Only SQLite-backed Durable Objects have access to Storage API's SQL and point-in-time recovery methods, which provide relational data modeling, SQL querying, and better data management.JavaScript export class MyDurableObject extends DurableObject {sql: SqlStorageconstructor(ctx: DurableObjectState, env: Env) {super(ctx, env);this.sql = ctx.storage.sql;}async sayHello() {let result = this.sql.exec("SELECT 'Hello, World!' AS greeting").one();return result.greeting;}}KV-backed Durable Objects remain for backwards compatibility, and a migration path from key-value storage to SQL storage for existing Durable Object classes will be offered in the future.
For more details on SQLite storage, checkout Zero-latency SQLite storage in every Durable Object blog ↗.
Queues now supports the ability to pause message delivery and/or purge (delete) messages on a queue. These operations can be useful when:
- Your consumer has a bug or downtime, and you want to temporarily stop messages from being processed while you fix the bug
- You have pushed invalid messages to a queue due to a code change during development, and you want to clean up the backlog
- Your queue has a backlog that is stale and you want to clean it up to allow new messages to be consumed
To pause a queue using Wrangler, run the
pause-deliverycommand. Paused queues continue to receive messages. And you can easily unpause a queue using theresume-deliverycommand.Pause and resume a queue $ wrangler queues pause-delivery my-queuePausing message delivery for queue my-queue.Paused message delivery for queue my-queue.$ wrangler queues resume-delivery my-queueResuming message delivery for queue my-queue.Resumed message delivery for queue my-queue.Purging a queue permanently deletes all messages in the queue. Unlike pausing, purging is an irreversible operation:
Purge a queue $ wrangler queues purge my-queue✔ This operation will permanently delete all the messages in queue my-queue. Type my-queue to proceed. … my-queuePurged queue 'my-queue'You can also do these operations using the Queues REST API, or the dashboard page for a queue.
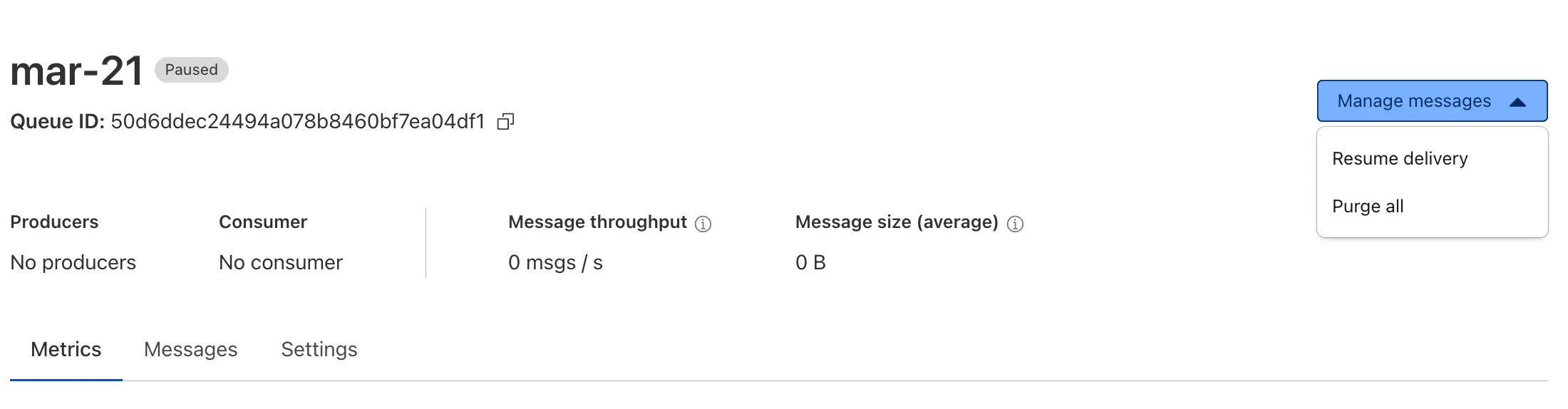
This feature is available on all new and existing queues. Head over to the pause and purge documentation to learn more. And if you haven't used Cloudflare Queues before, get started with the Cloudflare Queues guide.
Hyperdrive now pools database connections in one or more regions close to your database. This means that your uncached queries and new database connections have up to 90% less latency as measured from connection pools.
By improving placement of Hyperdrive database connection pools, Workers' Smart Placement is now more effective when used with Hyperdrive, ensuring that your Worker can be placed as close to your database as possible.
With this update, Hyperdrive also uses Cloudflare's standard IP address ranges ↗ to connect to your database. This enables you to configure the firewall policies (IP access control lists) of your database to only allow access from Cloudflare and Hyperdrive.
Refer to documentation on how Hyperdrive makes connecting to regional databases from Cloudflare Workers fast.
This improvement is enabled on all Hyperdrive configurations.
You can now use bucket locks to set retention policies on your R2 buckets (or specific prefixes within your buckets) for a specified period — or indefinitely. This can help ensure compliance by protecting important data from accidental or malicious deletion.
Locks give you a few ways to ensure your objects are retained (not deleted or overwritten). You can:
- Lock objects for a specific duration, for example 90 days.
- Lock objects until a certain date, for example January 1, 2030.
- Lock objects indefinitely, until the lock is explicitly removed.
Buckets can have up to 1,000 bucket lock rules. Each rule specifies which objects it covers (via prefix) and how long those objects must remain retained.
Here are a couple of examples showing how you can configure bucket lock rules using Wrangler:
Terminal window npx wrangler r2 bucket lock add <bucket> --name 180-days-all --retention-days 180Terminal window npx wrangler r2 bucket lock add <bucket> --name indefinite-logs --prefix logs/ --retention-indefiniteFor more information on bucket locks and how to set retention policies for objects in your R2 buckets, refer to our documentation.
Super Slurper can now migrate data from any S3-compatible object storage provider to Cloudflare R2. This includes transfers from services like MinIO, Wasabi, Backblaze B2, and DigitalOcean Spaces.
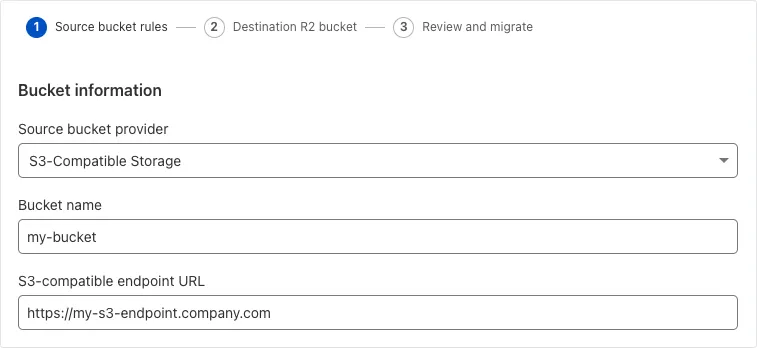
For more information on Super Slurper and how to migrate data from your existing S3-compatible storage buckets to R2, refer to our documentation.
You can now customize a queue's message retention period, from a minimum of 60 seconds to a maximum of 14 days. Previously, it was fixed to the default of 4 days.
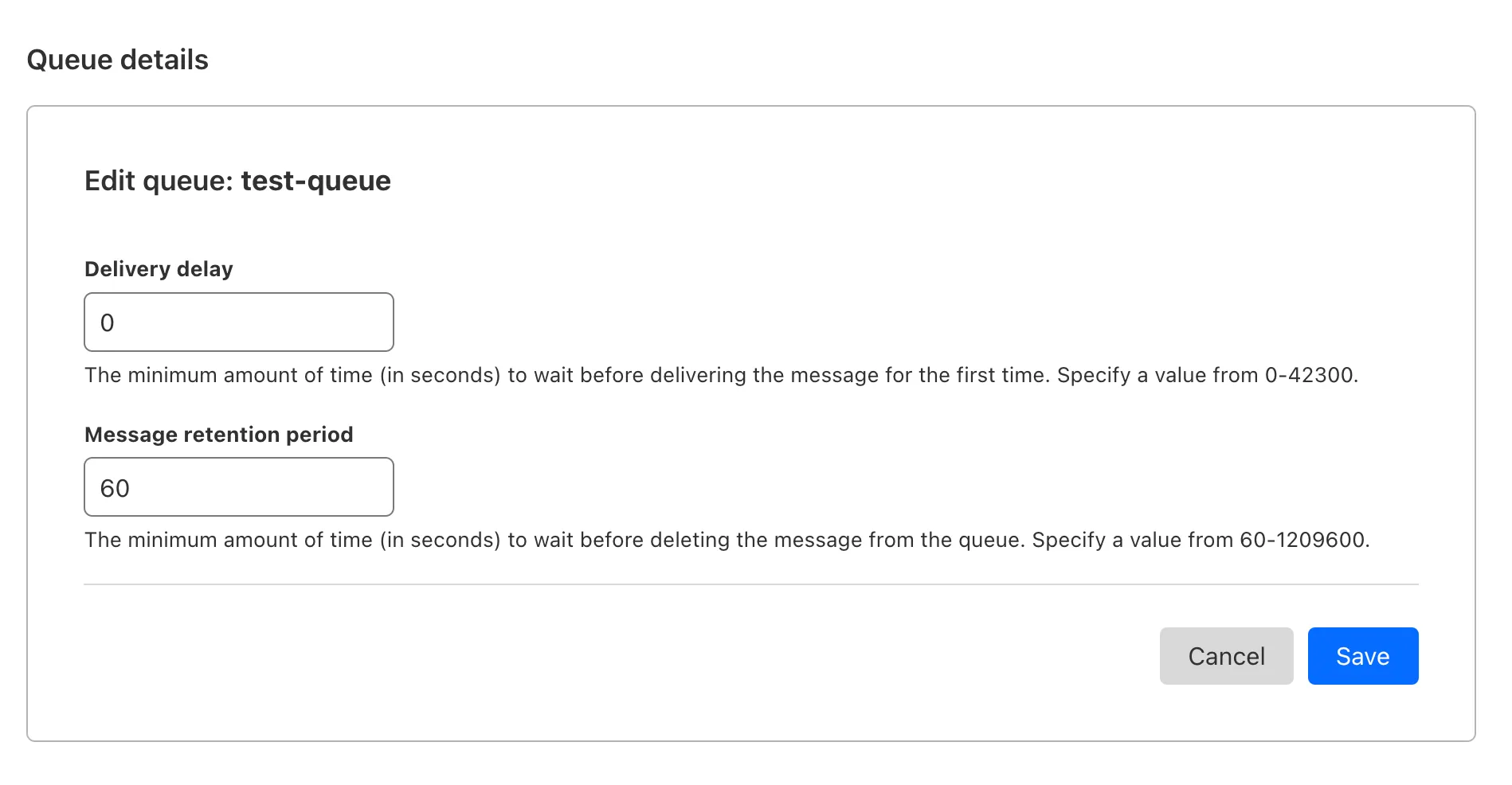
You can customize the retention period on the settings page for your queue, or using Wrangler:
Update message retention period $ wrangler queues update my-queue --message-retention-period-secs 600This feature is available on all new and existing queues. If you haven't used Cloudflare Queues before, get started with the Cloudflare Queues guide.
Super Slurper now transfers data from cloud object storage providers like AWS S3 and Google Cloud Storage to Cloudflare R2 up to 5x faster than it did before.
We moved from a centralized service to a distributed system built on the Cloudflare Developer Platform — using Cloudflare Workers, Durable Objects, and Queues — to both improve performance and increase system concurrency capabilities (and we'll share more details about how we did it soon!)
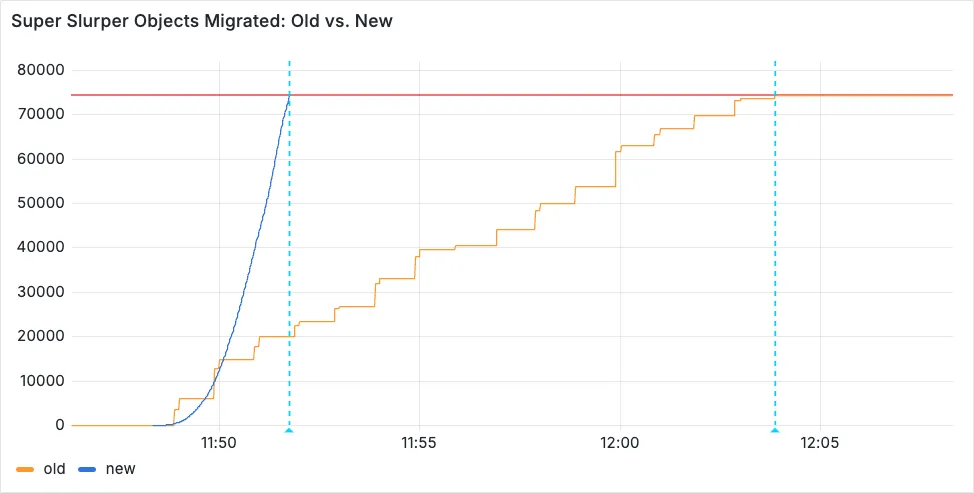
Time to copy 75,000 objects from AWS S3 to R2 decreased from 15 minutes 30 seconds (old) to 3 minutes 25 seconds (after performance improvements)
For more information on Super Slurper and how to migrate data from existing object storage to R2, refer to our documentation.
Hyperdrive now automatically configures your Cloudflare Tunnel to connect to your private database.
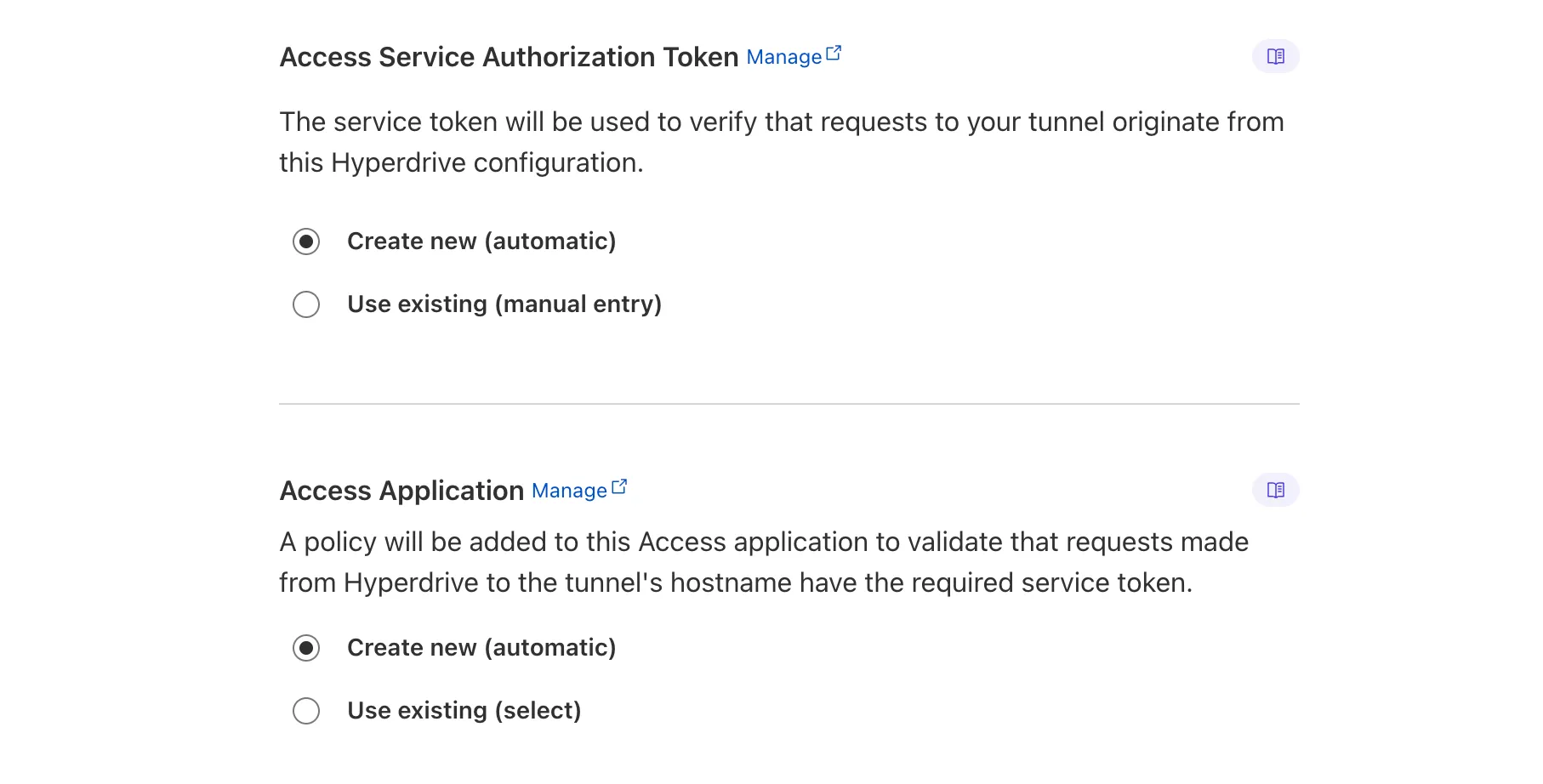
When creating a Hyperdrive configuration for a private database, you only need to provide your database credentials and set up a Cloudflare Tunnel within the private network where your database is accessible. Hyperdrive will automatically create the Cloudflare Access, Service Token, and Policies needed to secure and restrict your Cloudflare Tunnel to the Hyperdrive configuration.
To create a Hyperdrive for a private database, you can follow the Hyperdrive documentation. You can still manually create the Cloudflare Access, Service Token, and Policies if you prefer.
This feature is available from the Cloudflare dashboard.
You can now have up to 1000 Workers KV namespaces per account.
Workers KV namespace limits were increased from 200 to 1000 for all accounts. Higher limits for Workers KV namespaces enable better organization of key-value data, such as by category, tenant, or environment.
Consult the Workers KV limits documentation for the rest of the limits. This increased limit is available for both the Free and Paid Workers plans.
Users making D1 requests via the Workers API can see up to a 60% end-to-end latency improvement due to the removal of redundant network round trips needed for each request to a D1 database.
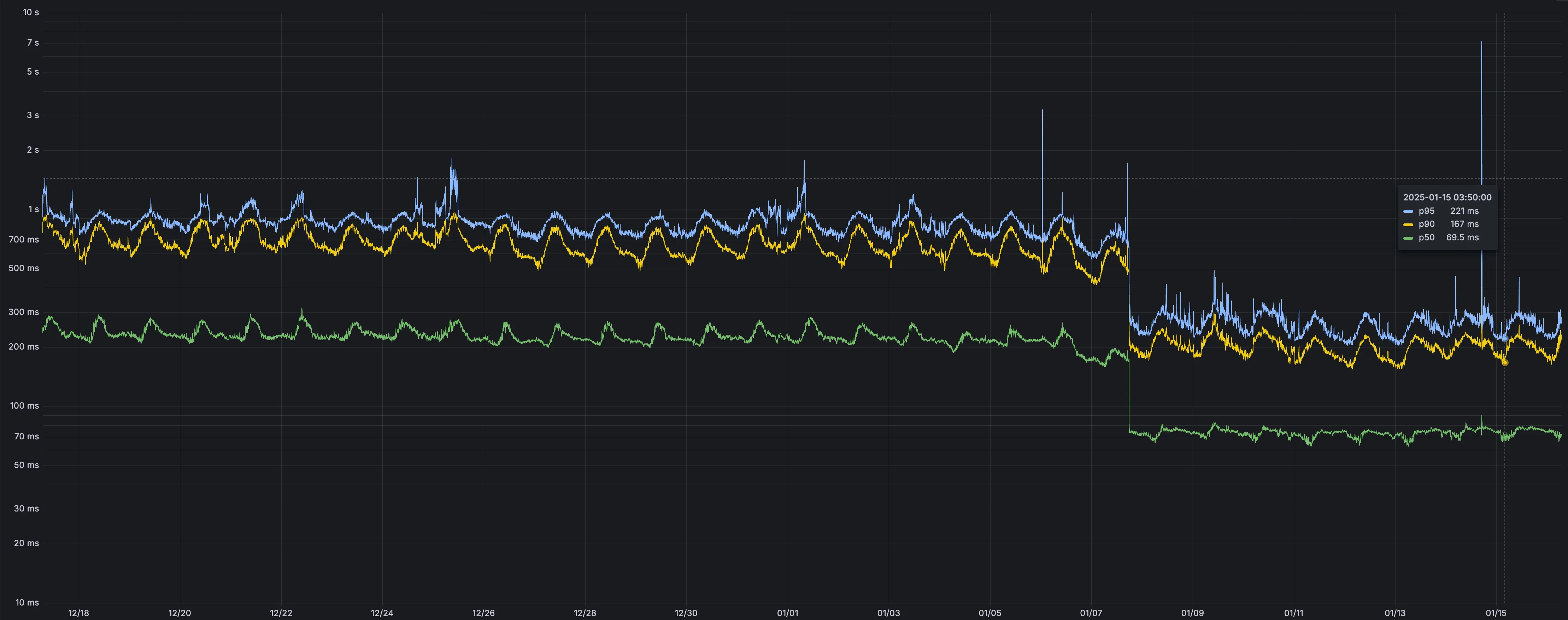
p50, p90, and p95 request latency aggregated across entire D1 service. These latencies are a reference point and should not be viewed as your exact workload improvement.
This performance improvement benefits all D1 Worker API traffic, especially cross-region requests where network latency is an outsized latency factor. For example, a user in Europe talking to a database in North America. D1 location hints can be used to influence the geographic location of a database.
For more details on how D1 removed redundant round trips, see the D1 specific release note entry.
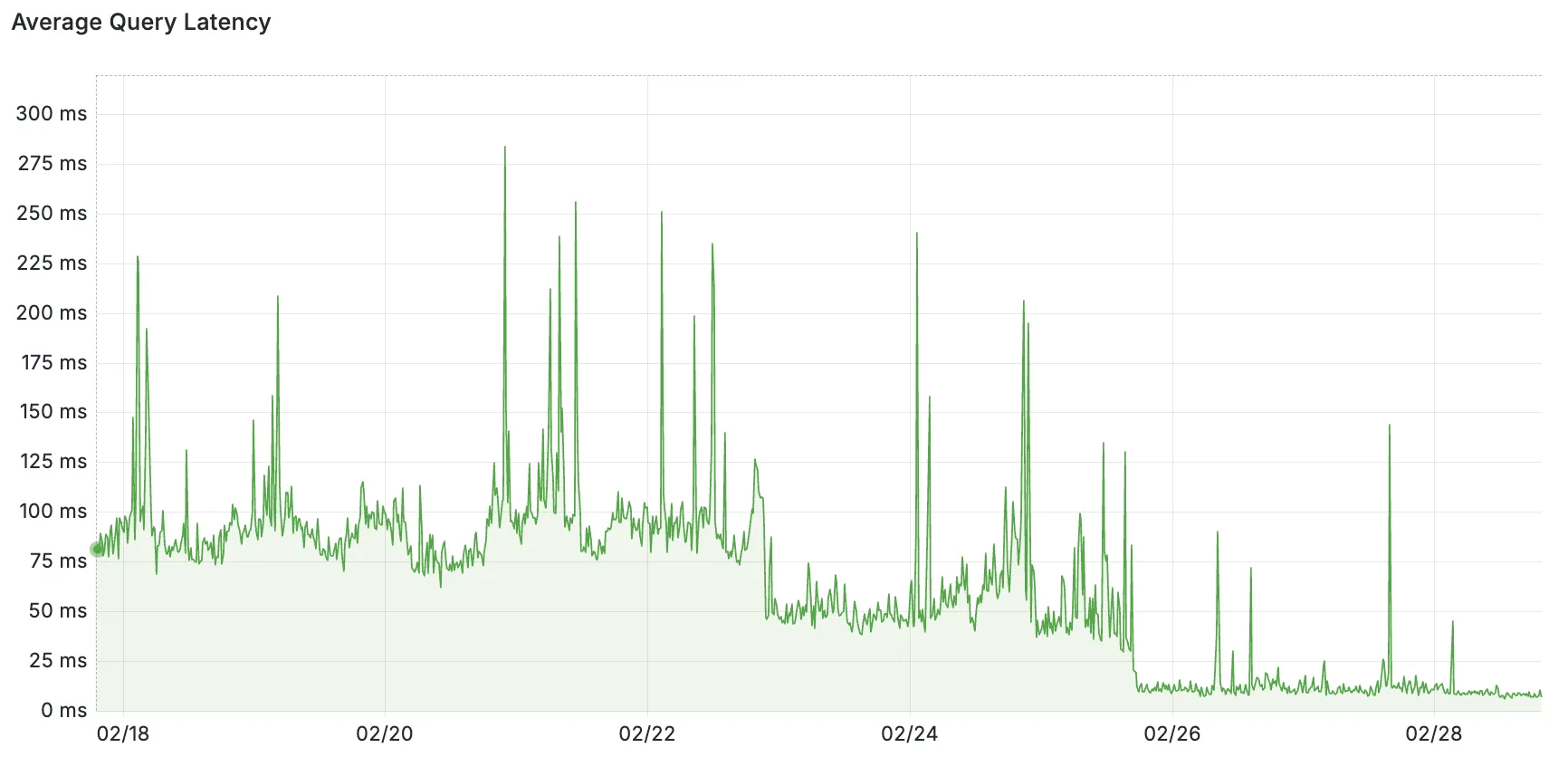
Hyperdrive now caches queries in all Cloudflare locations, decreasing cache hit latency by up to 90%.
When you make a query to your database and Hyperdrive has cached the query results, Hyperdrive will now return the results from the nearest cache. By caching data closer to your users, the latency for cache hits reduces by up to 90%.
This reduction in cache hit latency is reflected in a reduction of the session duration for all queries (cached and uncached) from Cloudflare Workers to Hyperdrive, as illustrated below.
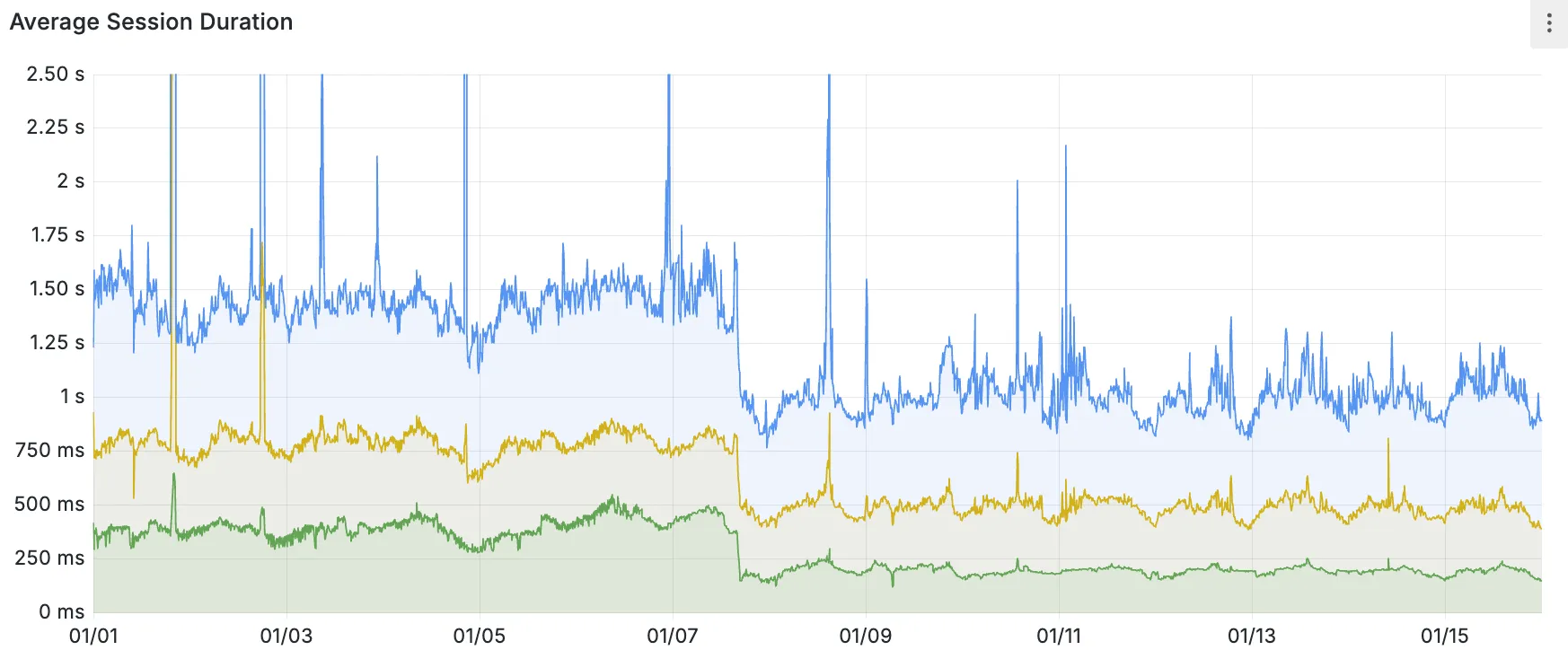
P50, P75, and P90 Hyperdrive session latency for all client connection sessions (both cached and uncached queries) for Hyperdrive configurations with caching enabled during the rollout period.
This performance improvement is applied to all new and existing Hyperdrive configurations that have caching enabled.
For more details on how Hyperdrive performs query caching, refer to the Hyperdrive documentation.