Server and pool health
As discussed before, a monitor issues health checks periodically to evaluate the health of each server within a pool.
flowchart RL
accTitle: Load balancing monitor flow
accDescr: Monitors issue health monitor requests, which validate the current status of servers within each pool.
Monitor -- Health Monitor ----> Endpoint2
Endpoint2 -- Response ----> Monitor
subgraph Pool
Endpoint1((Endpoint 1))
Endpoint2((Endpoint 2))
end
Requests issued by a monitor at regular interval and — depending on the monitor settings — return a pass or fail value to make sure an endpoint is still able to receive traffic.
Each health monitor request is trying to answer two questions:
- Is the endpoint offline?: Does the endpoint respond to the health monitor request at all? If so, does it respond quickly enough (as specified in the monitor's Timeout field)?
- Is the endpoint working as expected?: Does the endpoint respond with the expected HTTP response codes? Does it include specific information in the response body?
If the answer to either of these questions is "No", then the endpoint fails the health monitor request.
Based on the characteristics of your server pools, you have several customization options that affect how and whether a server is considered unhealthy.
The Health Threshold is the number of healthy endpoints for the pool as a whole to be considered Healthy and receive traffic based on pool order in a load balancer. Increasing this number makes the pool more reliable, but also more likely to become unhealthy.
For each option selected in a pool's Health Monitor Regions, Cloudflare sends health monitor requests from three separate data centers in that region.
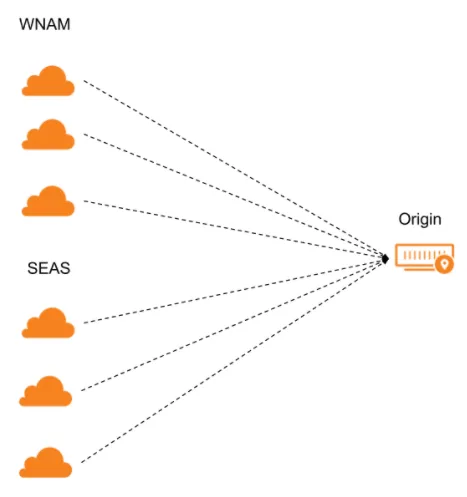
If the majority of data centers for that region pass the health monitor requests, that region is considered healthy. If the majority of regions is healthy, then the endpoint itself will be considered healthy.
All Data Centers (Enterprise only)
Health monitor probes are sent from every single data center in Cloudflare’s network to the endpoints within the associated pool. This allows probes to hit each endpoint during intervals set by the customer.
All Regions
Three health monitor probes per region are sent to each endpoint in the associated pool. There are a total of 13 regions, resulting in 39 probes.
Regional
Three health monitor probes are sent from each specified region within the pool configuration.
When you create a monitor, there are several configuration settings you can adjust based on the characteristics of the attached pools:
Basic settings
- Type: The protocol to use for health monitors
- Non-enterprise customers: Choose HTTP, HTTPS, or TCP.
- Enterprise customers: Choose HTTP, HTTPS, TCP, UDP ICMP, ICMP Ping, or SMTP.
- Path: The endpoint path to run health monitor requests against
- Port: The destination port for health monitors
Advanced settings
- Interval:
- By increasing the default, you can improve failover time, but you may also increase load on your endpoints.
- Minimum time in seconds is 60 (Pro), 15 (Business), and 10 (Enterprise).
- Timeout and Retries:
- The health monitor request will return unhealthy if it exceeds the duration specified in Timeout (and exceeds this duration more times than the specified number of Retries).
- Expected Code(s): The expected HTTP response codes listed individually (
200,302) or as a range (for example, entering2xxwould cover all response codes in the200range). - Response Body:
- Looks for a case-insensitive substring in the response body.
- Make sure that the value is relatively static and within the first 10 KB of the HTML page.
- Simulate Zone:
- It is recommended to use the same zone in which the Load Balancer exists.
- Changes the egress zone settings of a health monitor request to ensure compatibility with features like authenticated origin pulls, Argo Smart Routing, and Dedicated CDN Egress IPs.
- Follow Redirects:
- Instead of reporting a
301or302code as unhealthy, the health monitor request follows redirects to the final endpoint.
- Instead of reporting a
- Configure Request Header(s):
- Useful if your endpoints are expecting specific incoming headers.
- Header:
- The HTTP request headers to send in the health monitor. It is recommended that you set a Host header by default. The User-Agent header cannot be overridden. This parameter is only valid for HTTP and HTTPS monitors.
You also need to decide which of the associated pools in a load balancer should be the fallback pool.
This pool is meant to be the pool of last resort, meaning that its health is not taken into account when directing traffic.
Fallback pools are important because traffic still might be coming to your load balancer even when all the pools are unreachable (disabled or unhealthy). Your load balancer needs somewhere to route this traffic, so it will send it to the fallback pool.