Pay-as-you-go customers can now view billable usage and create budget alerts directly from the product overview pages for Workers & Pages, D1, R2, Workers KV, Queues, Vectorize, Durable Objects, and Containers. A new sidebar widget shows current-period spend and the billing cycle date range, alongside a button to create a budget alert.
The widget pulls from the same data as the Billable Usage dashboard and aligns to your billing cycle (or the current day on Free plans), so the numbers match your invoice. Enterprise contract accounts are not yet supported.
Selecting Create budget alert opens the budget alert flow inline so you can set a dollar threshold in the same place you are reviewing usage. Budget alerts apply to your total account-level spend across all products, not just the product page you create them from.
You can now point wrangler d1 migrations apply at a nested migrations layout — such as the one produced by Drizzle ↗ (migrations/0001_init/migration.sql) — using the new migrations_pattern D1 binding config:
migrations_pattern is a glob (relative to your Wrangler config file) used to discover migration files. It defaults to ${migrations_dir}/*.sql, so existing projects keep working unchanged. Each migration's name is recorded in the migrations table as a path relative to migrations_dir.
You can now set a jurisdiction when creating a D1 database to guarantee where your database runs and stores data. Jurisdictions can help you comply with data localization regulations such as GDPR. Supported jurisdictions include eu and fedramp.
A jurisdiction can only be set at database creation time via wrangler, REST API or the UI and cannot be added/updated after the database already exists.
npx wrangler@latest d1 create db-with-jurisdiction --jurisdiction eu
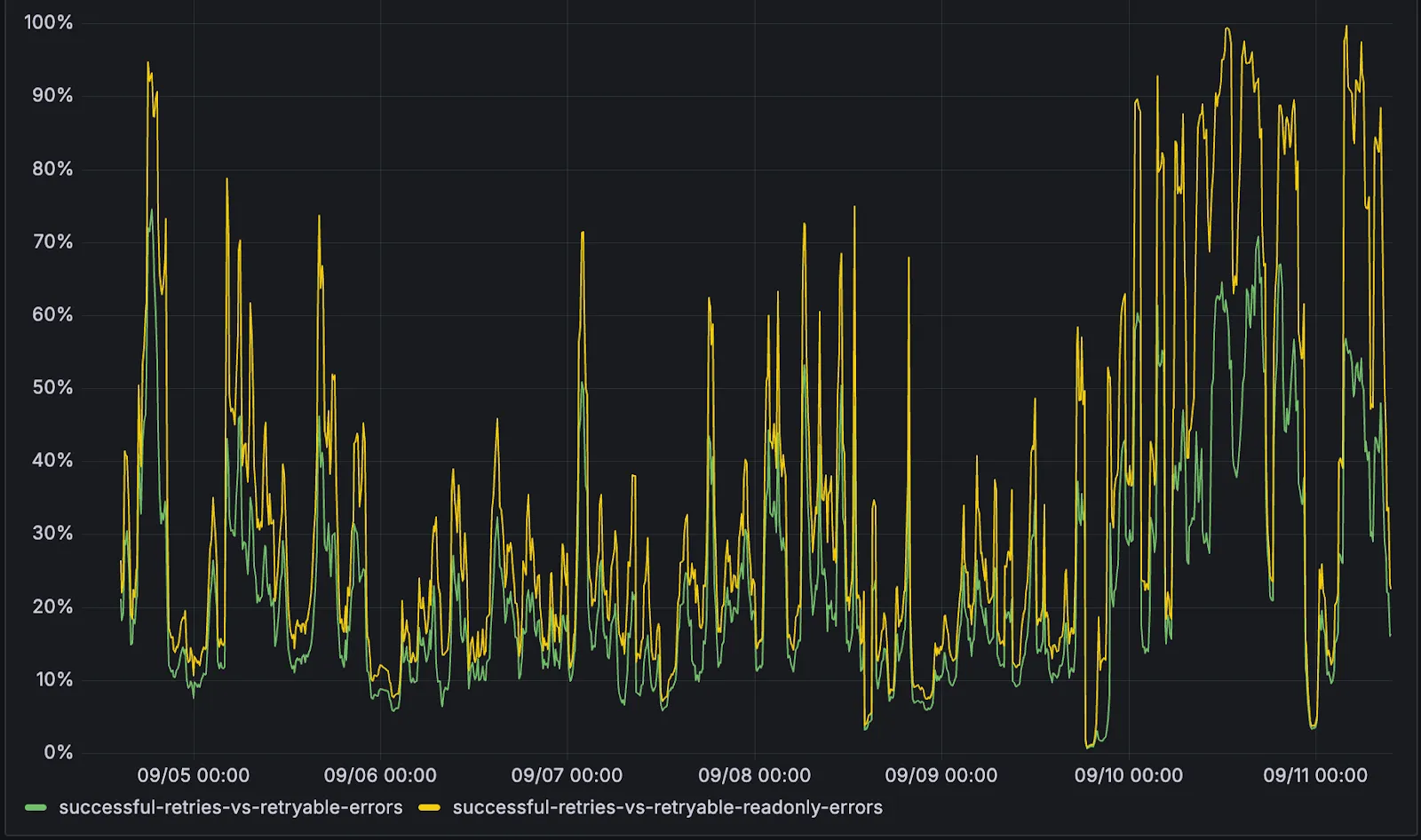
D1 now detects read-only queries and automatically attempts up to two retries to execute those queries in the event of failures with retryable errors. You can access the number of execution attempts in the returned response metadata property total_attempts.
At the moment, only read-only queries are retried, that is, queries containing only the following SQLite keywords: SELECT, EXPLAIN, WITH. Queries containing any SQLite keyword ↗ that leads to database writes are not retried.
The retry success ratio among read-only retryable errors varies from 5% all the way up to 95%, depending on the underlying error and its duration (like network errors or other internal errors).
The retry success ratio among all retryable errors is lower, indicating that there are write-queries that could be retried. Therefore, we recommend D1 users to continue applying retries in their own code for queries that are not read-only but are idempotent according to the business logic of the application.
D1 ensures that any retry attempt does not cause database writes, making the automatic retries safe from side-effects, even if a query causing changes slips through the read-only detection. D1 achieves this by checking for modifications after every query execution, and if any write occurred due to a retry attempt, the query is rolled back.
The read-only query detection heuristics are simple for now, and there is room for improvement to capture more cases of queries that can be retried, so this is just the beginning.
We've simplified the programmatic deployment of Workers via our Cloudflare SDKs. This update abstracts away the low-level complexities of the multipart/form-data upload process, allowing you to focus on your code while we handle the deployment mechanics.
Previously, deploying a Worker programmatically required manually constructing a multipart/form-data HTTP request, packaging your code and a separate metadata.json file. This was more complicated and verbose, and prone to formatting errors.
For example, here's how you would upload a Worker script previously with cURL:
With the new SDK interface, you can now define your entire Worker configuration using a single, structured object.
This approach allows you to specify metadata like main_module, bindings, and compatibility_date as clearer properties directly alongside your script content. Our SDK takes this logical object and automatically constructs the complex multipart/form-data API request behind the scenes.
Fixed the cloudflare_workers_script ↗ resource in Terraform, which previously was producing a diff even when there were no changes. Now, your terraform plan outputs will be cleaner and more reliable.
Fixed the cloudflare_workers_for_platforms_dispatch_namespace ↗, where the provider would attempt to recreate the namespace on a terraform apply. The resource now correctly reads its remote state, ensuring stability for production environments and CI/CD workflows.
The cloudflare_workers_route ↗ resource now allows for the script property to be empty, null, or omitted to indicate that pattern should be negated for all scripts (see routes docs). You can now reserve a pattern or temporarily disable a Worker on a route without deleting the route definition itself.
Using primary_location_hint in the cloudflare_d1_database ↗ resource will no longer always try to recreate. You can now safely change the location hint for a D1 database without causing a destructive operation.
Users using Cloudflare's REST API to query their D1 database can see lower end-to-end request latency now that D1 authentication is performed at the closest Cloudflare network data center that received the request. Previously, authentication required D1 REST API requests to proxy to Cloudflare's core, centralized data centers, which added network round trips and latency.
Latency improvements range from 50-500 ms depending on request location and database location and only apply to the REST API. REST API requests and databases outside the United States see a bigger benefit since Cloudflare's primary core data centers reside in the United States.
D1 query endpoints like /query and /raw have the most noticeable improvements since they no longer access Cloudflare's core data centers. D1 control plane endpoints such as those to create and delete databases see smaller improvements, since they still require access to Cloudflare's core data centers for other control plane metadata.
D1 read replication is available in public beta to help lower average latency and increase overall throughput for read-heavy applications like e-commerce websites or content management tools.
Workers can leverage read-only database copies, called read replicas, by using D1 Sessions API. A session encapsulates all the queries from one logical session for your application. For example, a session may correspond to all queries coming from a particular web browser session. With Sessions API, D1 queries in a session are guaranteed to be sequentially consistent to avoid data consistency pitfalls. D1 bookmarks can be used from a previous session to ensure logical consistency between sessions.
// retrieve bookmark from previous session stored in HTTP headerconst bookmark = request.headers.get("x-d1-bookmark") ?? "first-unconstrained";const session = env.DB.withSession(bookmark);const result = await session .prepare(`SELECT * FROM Customers WHERE CompanyName = 'Bs Beverages'`) .run();// store bookmark for a future sessionresponse.headers.set("x-d1-bookmark", session.getBookmark() ?? "");
Read replicas are automatically created by Cloudflare (currently one in each supported D1 region), are active/inactive based on query traffic, and are transparently routed to by Cloudflare at no additional cost.
To checkout D1 read replication, deploy the following Worker code using Sessions API, which will prompt you to create a D1 database and enable read replication on said database.
To learn more about how read replication was implemented, go to our blog post ↗.
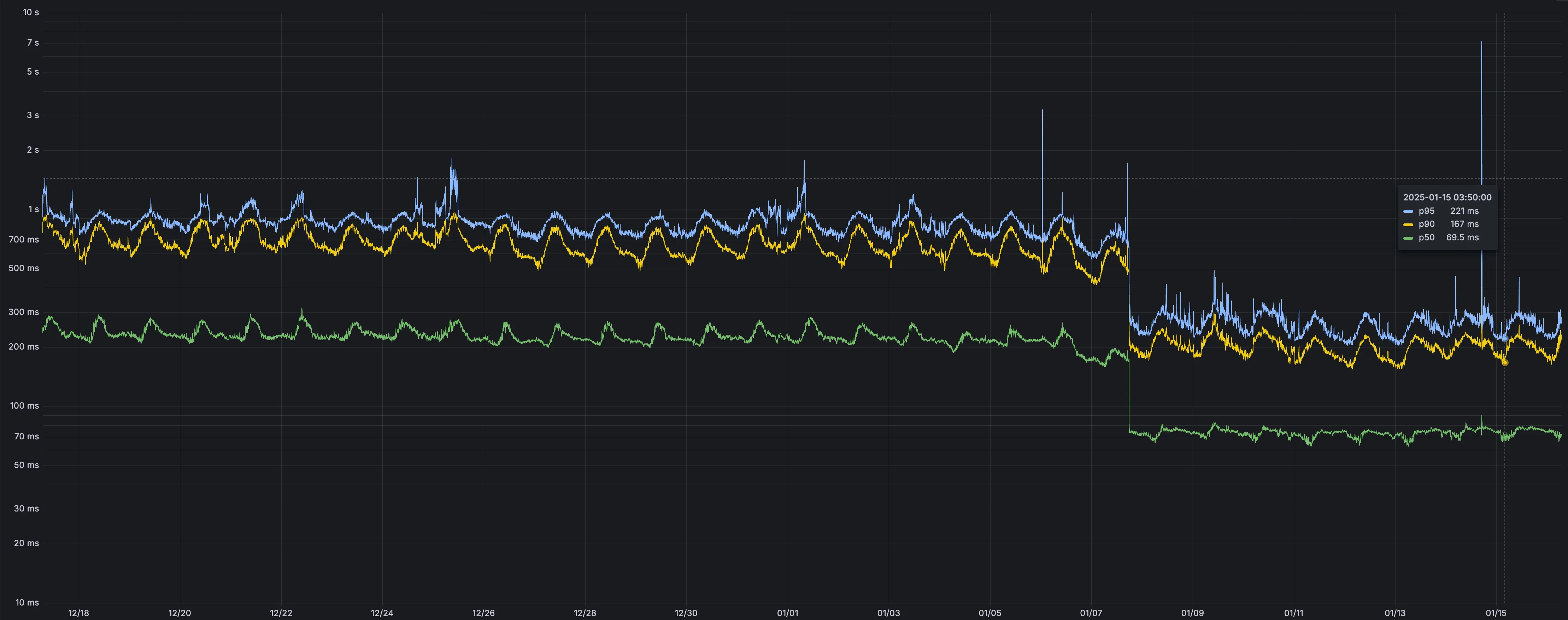
Users making D1 requests via the Workers API can see up to a 60% end-to-end latency improvement due to the removal of redundant network round trips needed for each request to a D1 database.
p50, p90, and p95 request latency aggregated across entire D1 service. These latencies are a reference point and should not be viewed as your exact workload improvement.
This performance improvement benefits all D1 Worker API traffic, especially cross-region requests where network latency is an outsized latency factor. For example, a user in Europe talking to a database in North America. D1 location hints can be used to influence the geographic location of a database.
For more details on how D1 removed redundant round trips, see the D1 specific release note entry.