Cloudflare Load Balancing Reference Architecture
Introduction
Cloudflare Load Balancing is a SaaS offering that allows organizations to host applications for a global user base while vastly reducing concerns of maintenance, failover, resiliency, and scalability. Using Cloudflare Load Balancing allows organizations to address the following challenges:
- Efficiently handling large volumes of incoming traffic, especially during unexpected surges or spikes.
- Ensuring applications and services remain accessible to users.
- Maintaining quick response times and optimal performance for all users, especially during high traffic periods.
- Adapting to changing traffic demands and ensuring the infrastructure can accommodate growth.
- Helping applications and services resist Distributed Denial of Service (DDoS) attacks.
Cloudflare Load Balancing is built on Cloudflare’s connectivity cloud, a unified, intelligent platform of programmable cloud-native services that enable secure any-to-any connectivity between all networks (enterprise and Internet), cloud environments, applications, and users. It is one of the largest global networks, with data centers spanning more than 310 cities in over 120 countries and interconnection with over 13,000 other networks. It also has a greater presence in core Internet exchanges than many other large technology companies.
As a result, Cloudflare operates within ~50 ms of ~95% of the world’s Internet-connected population. And since all Cloudflare services are designed to run across every network location, all requests are routed, inspected, and filtered close to their source, resulting in strong performance and consistent user experiences.
This document describes a reference architecture for organizations looking to deploy both global and local traffic management load balancing solutions.
Who is this document for and what will you learn?
This reference architecture is designed for IT, web hosting, and network professionals with some responsibility over or familiarity with their organization’s existing infrastructure. It is useful to have some experience with networking concepts such as routing, DNS, and IP addressing, as well as basic understanding of load balancer functionality.
To build a stronger baseline understanding of Cloudflare and its load balancing solution, we recommend the following resources:
- Solution Brief: Cloudflare LTM Load Balancing (5 minute read)
- Solution Brief: Cloudflare GTM Load Balancing (5 minute read)
- Blog: Elevate load balancing with Private IPs and Cloudflare Tunnels: a secure path to efficient traffic distribution (13 minutes)
Those who read this reference architecture will learn:
- How Cloudflare Load Balancing can address both local traffic management and global traffic management use cases.
- How Cloudflare’s global network enhances the functionality of Cloudflare Load Balancing.
- The capabilities of Cloudflare Load Balancers, and how they apply to various use cases.
- The structure of Cloudflare Load Balancers and their various configurations.
Handling dynamic workloads in modern applications
Concepts and terminology
Origin
In this document, the term “origin” refers to the location traffic is being steered to from the point of view of a load balancer. This could be a website, application, or other type of server. It could be physical, virtual, or serverless. It could be on-premises or hosted in a public or private cloud — and could even be a third-party load balancer. Within Cloudflare documentation, it may also be called a server, host, or endpoint.
Steering
Steering is a load balancer’s main function — the process of handling, sending, and forwarding requests based on a set of policies. These policies generally take many factors into account, including request URL, URL path, HTTP headers, configured weights, priority, and server latency, responsiveness, capacity, and load.
Layer 7
Layer 7 of the OSI model, also known as the application layer, is where protocols such as SSH, FTP, NTP, SMTP, and HTTP(S) reside. When this document refers to layer 7 or layer 7 load balancers, it means HTTP(S)-based services. The Cloudflare layer 7 stack allows Cloudflare to apply services like DDoS protection, Bot Management. WAF, CDN, Load Balancing and more to a customer’s website to improve performance, availability, and security.
Layer 4
Layer 4 of the OSI model — also called the transport layer — is responsible for end-to-end communication between two devices. Network services that operate at layer 4 can support a much broader set of services and protocols. Cloudflare’s public layer 4 load balancers are enabled by a product called Spectrum, which works as a layer 4 reverse proxy. In addition to offering load balancing, Spectrum provides protection from DDoS attacks and can conceal origin IP addresses.
SSL/TLS Offloading
SSL (Secure Sockets Layer) and its successor TLS (Transport Layer Security) are cryptographic protocols used to secure connections over the Internet. SSL and TLS offloading, also known as SSL/TLS termination or SSL/TLS acceleration, is a technique used in load balancers and web servers to handle the SSL/TLS encryption and decryption process without affecting an origin’s performance. SSL/TLS offloading improves server performance, simplifies certificate management, and enhances scalability by offloading the resource-intensive encryption and decryption tasks to dedicated devices, helping origins remain dedicated to serving content and application logic.
Challenges addressed by load balancers
Modern websites, or any applications for that matter, face three main challenges:
- Performance: Ensuring that the application responds to users requests and input in a timely manner
- Availability: Maintaining the uptime for the application, so it is always able to respond to user requests
- Scalability: Growing, shrinking, or relocating application resources based on user behavior or demand.
Performance
Application performance can be affected by several factors, but the most common cause of performance issues is the amount of usage or load placed on an origin server. An origin generally has a finite amount of compute resources it can provide. If too many requests arrive at once, or if the type of requests cause increased CPU/memory usage, the origin will respond slower or fail to respond at all.
To address these challenges, origins can be upgraded with more compute resources. But during idle or low-usage times, the organization ends up paying for underutilized resources. Organizations may also deploy multiple origins — but to seamlessly steer traffic between them, a load balancing solution is needed to make this process seamless to the end user.
Figure 1 shows how load might be distributed without a load balancer:
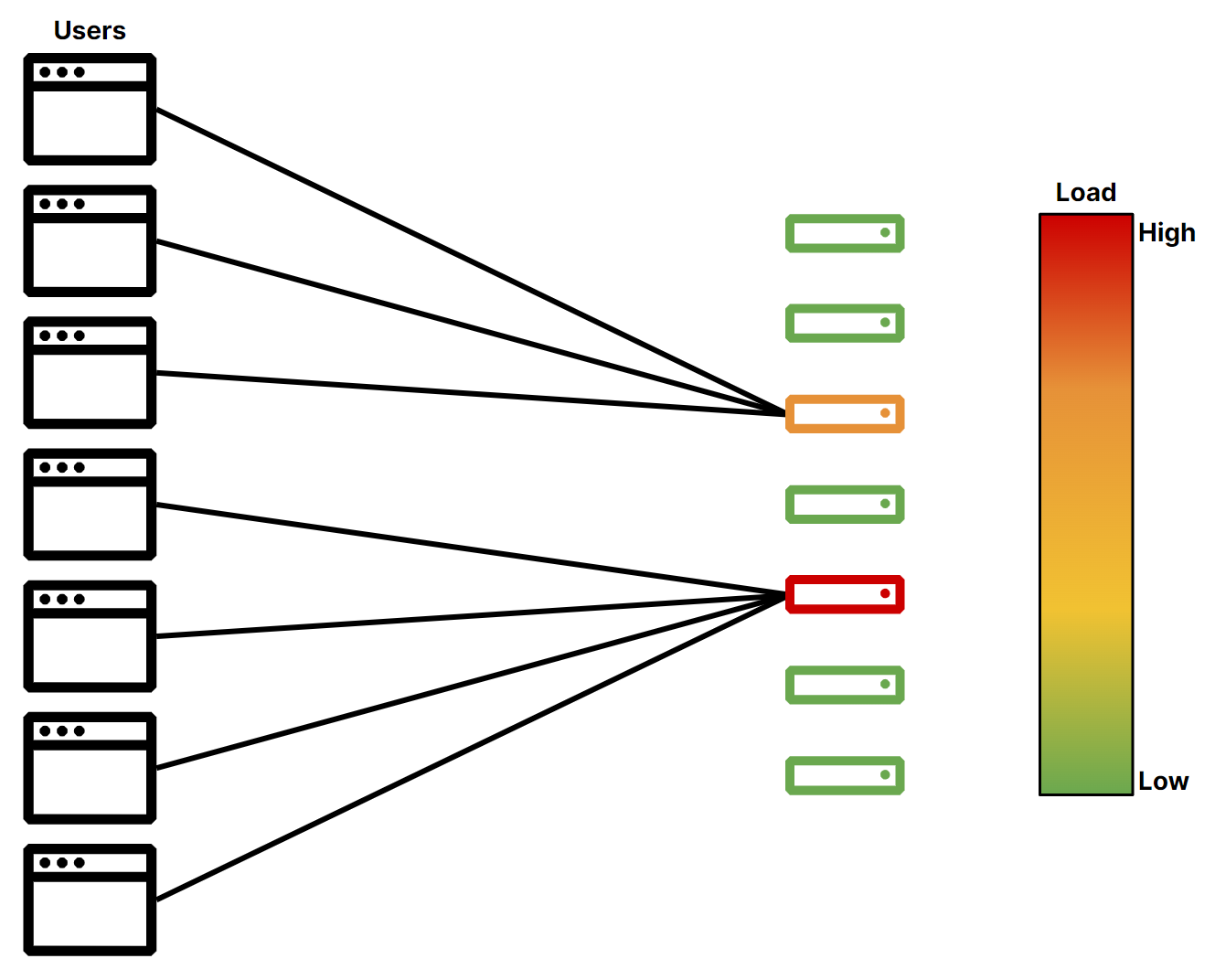
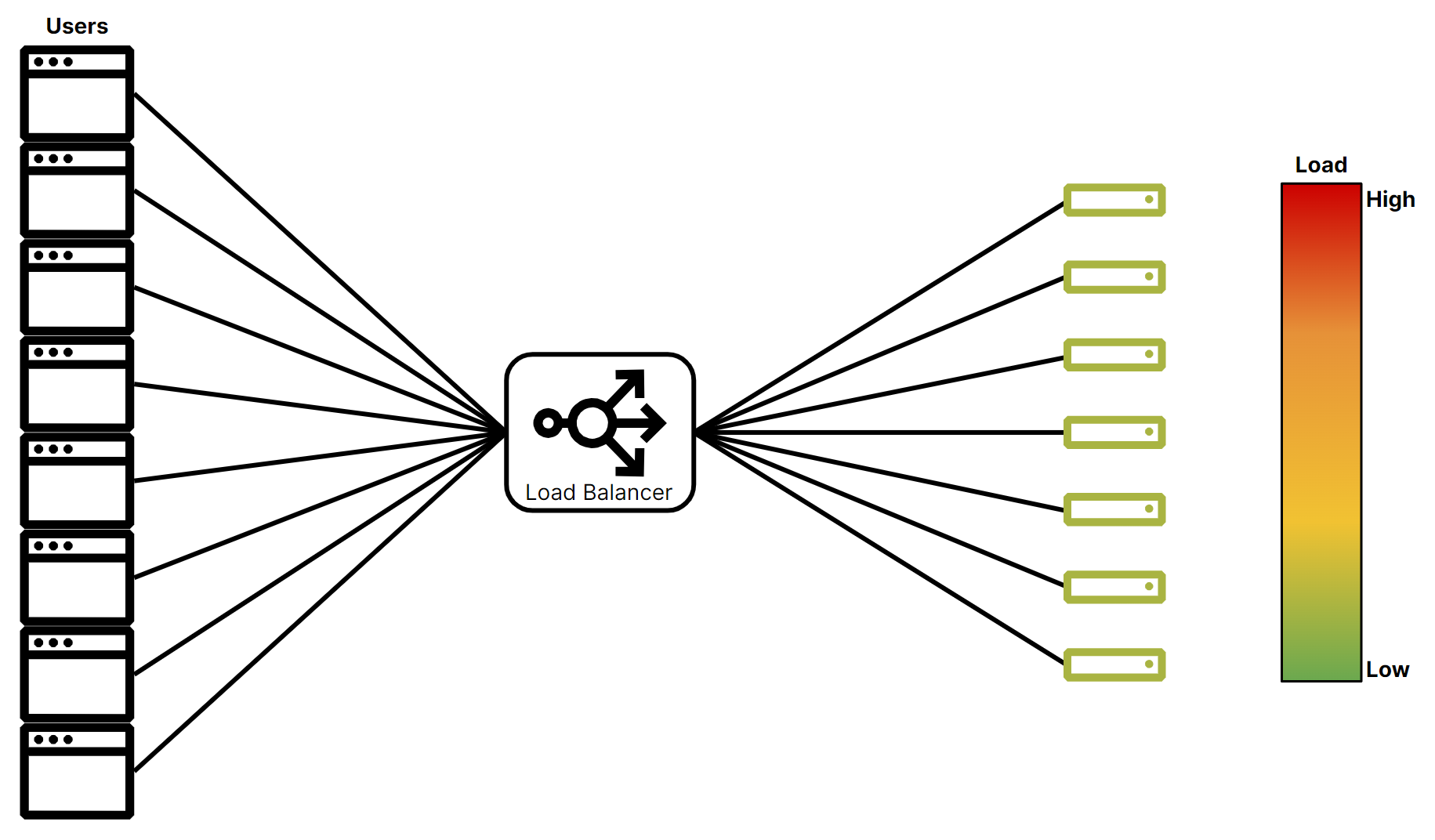
Load balancers allow organizations to host several origins and portion out traffic between them, ensuring no single server gets overwhelmed. The load balancer handles all incoming requests and forwards them to the appropriate server. The client doesn’t need any knowledge of server availability or load — it just needs to send the request to the load balancer and the load balancer handles the rest. Figure 2 shows how a load balancer can evenly distribute traffic from users across a set of origins.
Another performance-related issue has to do with the distance between a client and an origin. Whether due to the mere fact of traveling farther, or having to make more network hops, a request that travels a longer distance generally has a higher round-trip time (RTT).
RTT becomes important at scale. For example, if a client and server are both located in the United States, it would be reasonable to expect a RTT of 25ms. If the client has 20 requests it needs responses to, the total time required to handle them sequentially (not including compute time) would be 500ms (20 x 25ms). And if the same client connected from the APAC region the RTT might be upwards of 150ms, resulting in an undesirable total loading time of 3000ms (20 x 150ms). (Certainly, request streaming enhancements in HTTP/2 and HTTP/3 might change this math — but in websites with dynamic or interactive content, where a response’s information is used to generate additional requests, the example still holds in general.) Figure 3 illustrates how this happens.
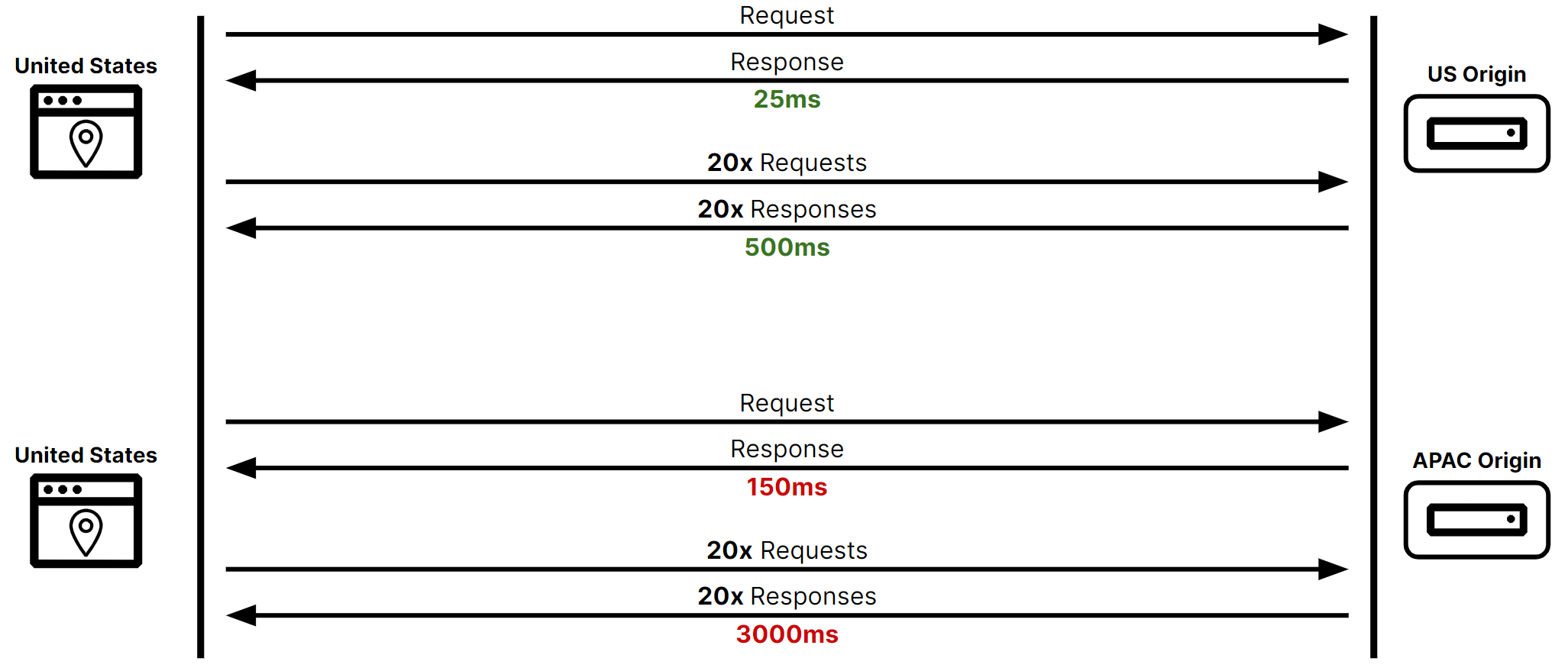
In the same way a load balancer can pass traffic to a less-busy server, it can also pass traffic to a geographically closer server, resulting in a more responsive experience for the client. Specifically, the load balancer performs a lookup of the IP address that sent the request, determines its location, and selects the closest or most region-appropriate server to send it to. (This is similar to functionality provided by DNS solutions like GeoDNS.
Availability
Service availability encompasses both unintentional and intentional downtime of origins behind a load balancer. Several factors can contribute to unintentional downtime, including hardware failure, software bugs, network issues, and ISP or other vendor issues. Even for the most advanced organizations, these issues are inevitable.
Load balancers solve these issues by always monitoring the health of origins. If an origin is slow to respond to a health check, or fails to respond entirely,the origin is marked as unhealthy. Several methods exist for doing so, including basic health tests like ICMP (ping) and TCP connection tests. More advanced health tests can be used like issuing an HTTP GET request and ensuring a specific response code and response body are returned from the origin. Once a server is in a degraded state, the load balancer will send fewer or no requests its way in favor of healthier origins. As the origin becomes operational again and the load balancer is able to receive responses to its health checks, the origin is marked as operational and has traffic steered towards it once more.
Intentional downtime comes in a few different forms, including capacity changes, hardware or infrastructure upgrades, and software updates. Load balancers gracefully remove traffic from one or more origins to allow for such maintenance..
Scale
Effective application scaling helps organizations meet customer or user demand and avoid unnecessary billing or charges. During traffic increases, organizations may need to temporarily deploy more origins to ensure the service stays performant and available. However, constantly having enough origins online to meet your maximum possible traffic could be costly regardless whether the server is located on-premises or via a cloud provider like AWS, GCP, or Azure. Load balancers allow for dynamic increases or decreases in capacity by monitoring requests, connections, and latency to the origins.
Another type of scale to consider is geographic scale. As services grow in popularity, server location becomes more important. Users in a different geographic region than a server may have slower response times and receive a lower quality of service than users in the same region. As organizations deploy new origins in different regions, they have to decide how they want to distribute their traffic. This challenge has been met by different layers of load balancing called global traffic management (GTM) and local traffic management (LTM). This document describes both of these in detail in the following section — but in summary, the GTM load balancer handles the initial request (typically via DNS) and then selects and steers traffic to the LTM load balancer that is deployed close to origins in the appropriate geographic region.
Types of traffic management
As mentioned, load balancing for global applications and services comes in two layers. The first layer is called Global Traffic Management or Manager (GTM), which may also be called Global Server Load Balancing (GSLB). The second layer is called Local Traffic Management or Manager (LTM), which may also be referred to as Server Load Balancing (SLB). This section will define the purpose of these different types of load balancing and how they work together.
Global traffic manager / global traffic management (GTM)
A Global Traffic Manager is responsible for routing requests, generally from the Internet, to the proper region or data center. Many GTM load balancers operate at the DNS layer, allowing them to:
- Resolve a DNS request to an IP address based on geographic region or physical location.
- Provide the IP of the origin or service closest to the client, so it can connect.
Figure 4 shows how a GTM load balancer is used to select a data center based on the client location or region.
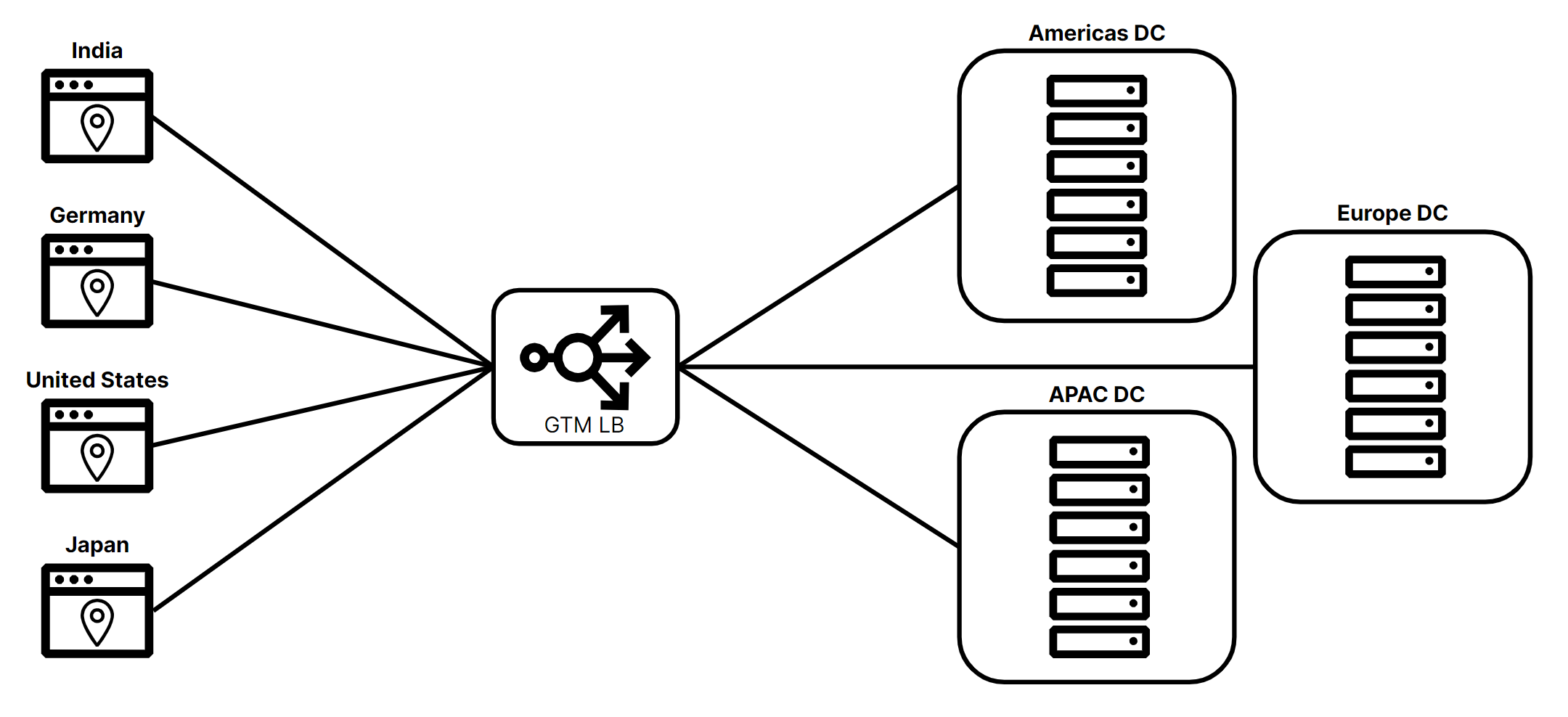
Global Traffic Managers can also proxy traffic and perform a variety of inspections, including reading/changing/deleting headers in HTTP requests and modifying URLs based on region or geographic location. GTM functionality is best implemented by cloud-based load balancers (like Cloudflare) since the goal is to steer traffic from anywhere in the world. Hardware load balancers exist in a single physical location, which means the further traffic originates from the load balancer, the slower the end-user experience. A cloud-based load balancer can run in many different geographic locations, helping it provide a performant solution for DNS-only, layer 4, and layer 7 contexts.
Local traffic manager / local traffic management (LTM)
A Local Traffic Manager steers traffic within a data center or geographic location. A LTM can be responsible for load balancing, SSL/TLS offloading, content switching, and other application delivery functions. LTM ensures efficient distribution of client requests across multiple origins to improve performance and ensure high availability. LTM load balancers are usually placed inside private networks and are used to load balance publicly or privately accessible resources. In Figure 5 below, the GTM load balancer has selected the Europe data center to direct a request to the Europe data center’s LTM load balancer which will then steer it to the appropriate origin.
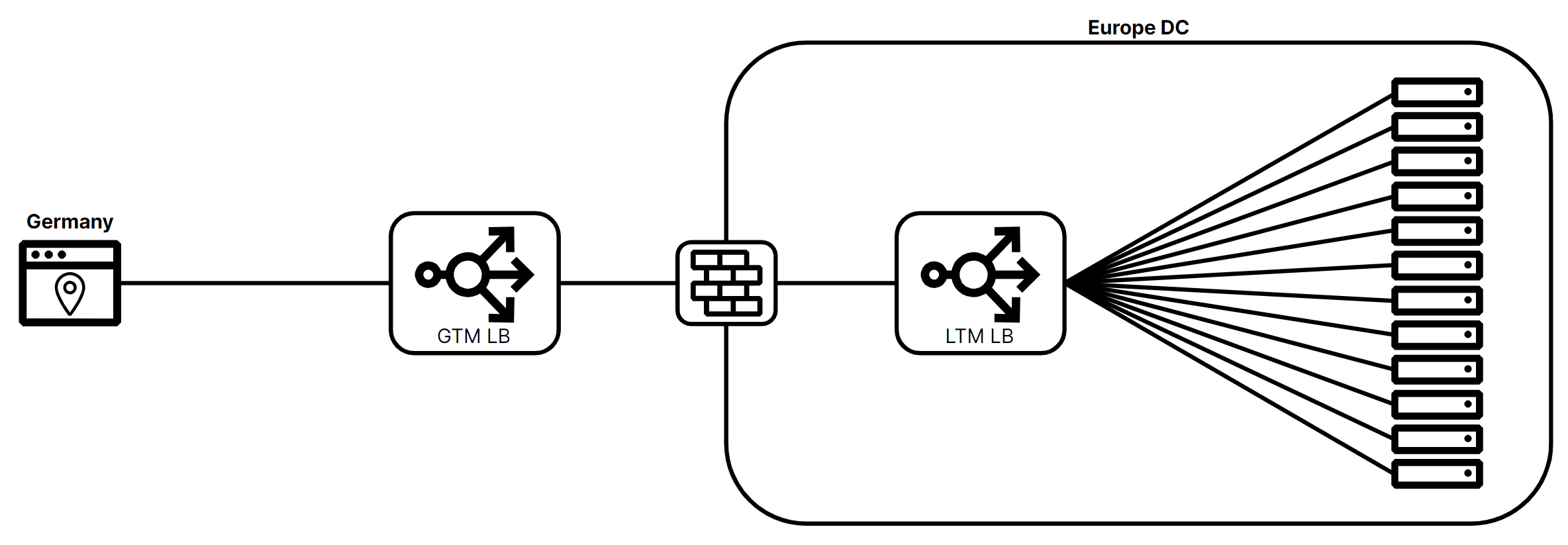
Local traffic managers and their origins usually sit behind firewalls. But while origins may be protected on private networks, accessibility to the LTM load balancer can be either public or private depending on deployment requirements. A LTM load balancer will monitor total requests, connections, and server health to ensure requests are steered towards origins capable of responding in a timely manner.
On-premises vs cloud-based load balancers
There are two main load balancer architectures:
- On-premises load balancers
- Typically hardware-based, but also can be virtualized or software-based
- Focused on maximum performance
- Cloud-based load balancers
- Software deployed public cloud infrastructure
- Handle requests closer to the originator of the request
Each approach has advantages and disadvantages. On-premises load balancers usually exist inside of private networks completely controlled by the organization. These load balancers are collocated with the origins they are load balancing, so latency and RTT time should be minimal. The disadvantage of these on-premises load balancers is that they are restricted to a single physical location. Which means traffic from other regions can have long RTT and high latency in responses. Also, adding another data center requires purchasing and deploying all new equipment. On-premises load balancers also typically require cloud-based load balancers for geographic traffic steering to get requests routed by a geographically local or region-appropriate data center. The advantages of cloud-based load balancers is that they can operate in almost any geographic region without concern for rack space, power, cooling, or maintenance and can scale without concern for new chassis, modules, or larger network connections. Cloud-based load balancers do however increase latency and RTT between the load balancer and the origin servers as they are not typically colocated with the origins they are steering traffic toward.
Cloudflare Load Balancing architecture and design
Cloudflare has offered cloud-based GTM since 2016 and started adding LTM capabilities in 2023. This section will review the entire Cloudflare Load Balancing architecture and dive deep into the different configurations and options available. First, however, it’s important to understand the benefits that Cloudflare Load Balancers have simply by running on Cloudflare’s global network.
Inherent advantages in the Cloudflare architecture
Cloudflare Load Balancing is built on Cloudflare’s connectivity cloud, a unified, intelligent platform of programmable cloud-native services that enable any-to-any connectivity between all networks (enterprise and Internet), cloud environments, applications, and users. It is one of the largest global networks, with data centers spanning more than 310 cities in over 120 countries and interconnection with over 13,000 other networks. It also has a greater presence in core Internet exchanges than many other large technology companies.
As a result, Cloudflare operates within ~50 ms of ~95% of the world’s Internet-connected population. And since all Cloudflare services are designed to run across every network location, all traffic is connected, inspected, and filtered close to the source for the best performance and consistent user experience.
Cloudflare’s load balancing solution benefits from our use of Anycast technology. Anycast allows Cloudflare to announce the IP addresses of our services from every data center worldwide, so traffic is always routed to the Cloudflare data center closest to the source. This means traffic inspection, authentication, and policy enforcement take place close to the end user, leading to consistently high-quality experiences.
Using Anycast ensures the Cloudflare network is well balanced. If there is a sudden increase in traffic on the network, the load can be distributed across multiple data centers – which in turn, helps maintain consistent and reliable connectivity for users. Further, Cloudflare’s large network capacity and AI/ML-optimized smart routing also help ensure that performance is constantly optimized.
By contrast, many other SaaS-based load balancing providers use Unicast routing in which a single IP address is associated with a single server and/or data center. In many such architectures, a single IP address is then associated with a specific application, which means requests to access that application may have very different network routing experiences depending on how far that traffic needs to travel. For example, performance may be excellent for employees working in the office next to the application’s servers, but poor for remote employees or those working overseas. Unicast also complicates scaling traffic loads — that single service location must ramp up resources when load increases, whereas Anycast networks can share traffic across many data centers and geographies.
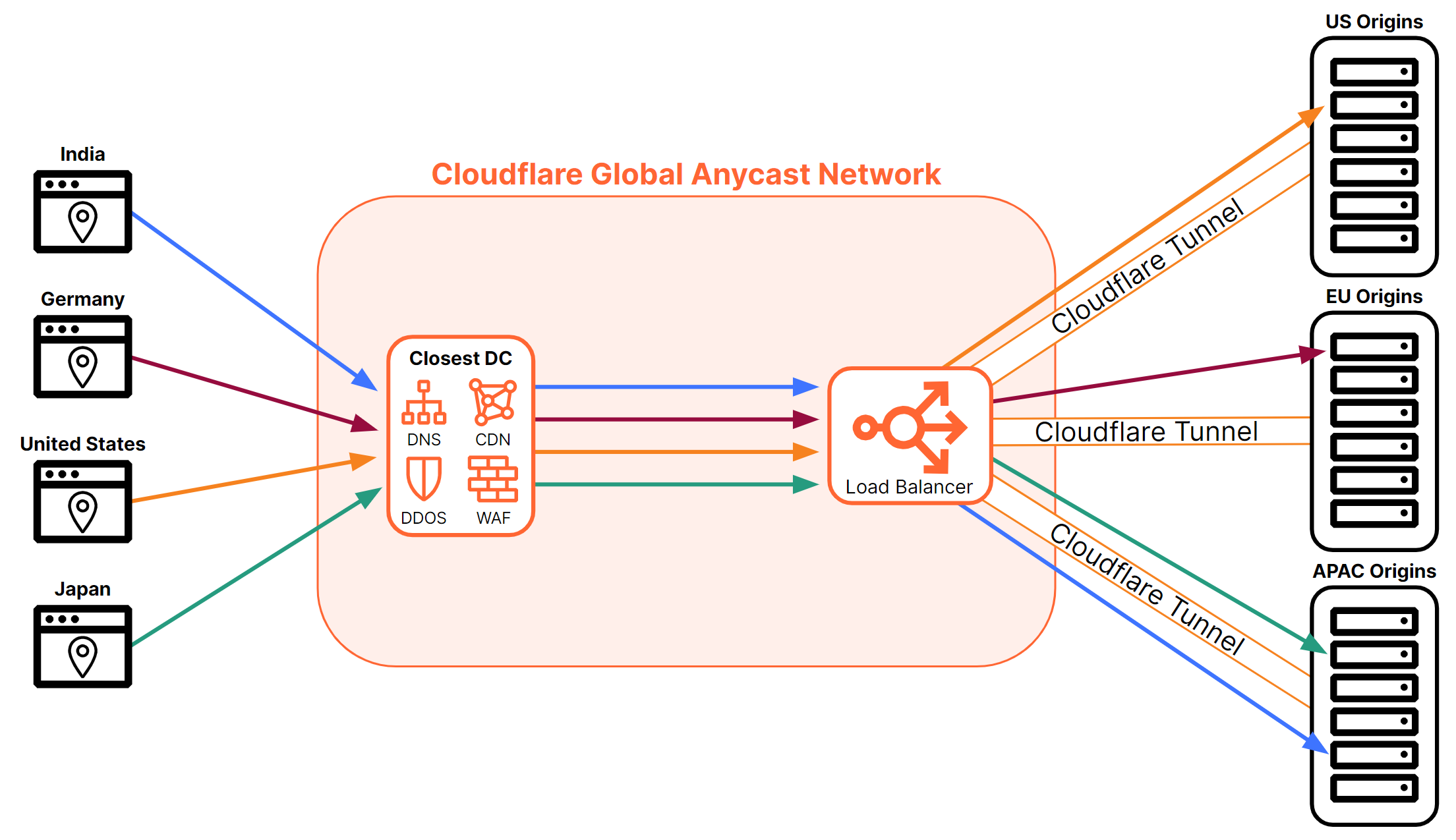
Figure 6 shows how using the Cloudflare network allows geographically disparate users to connect to their resources as fast as possible.
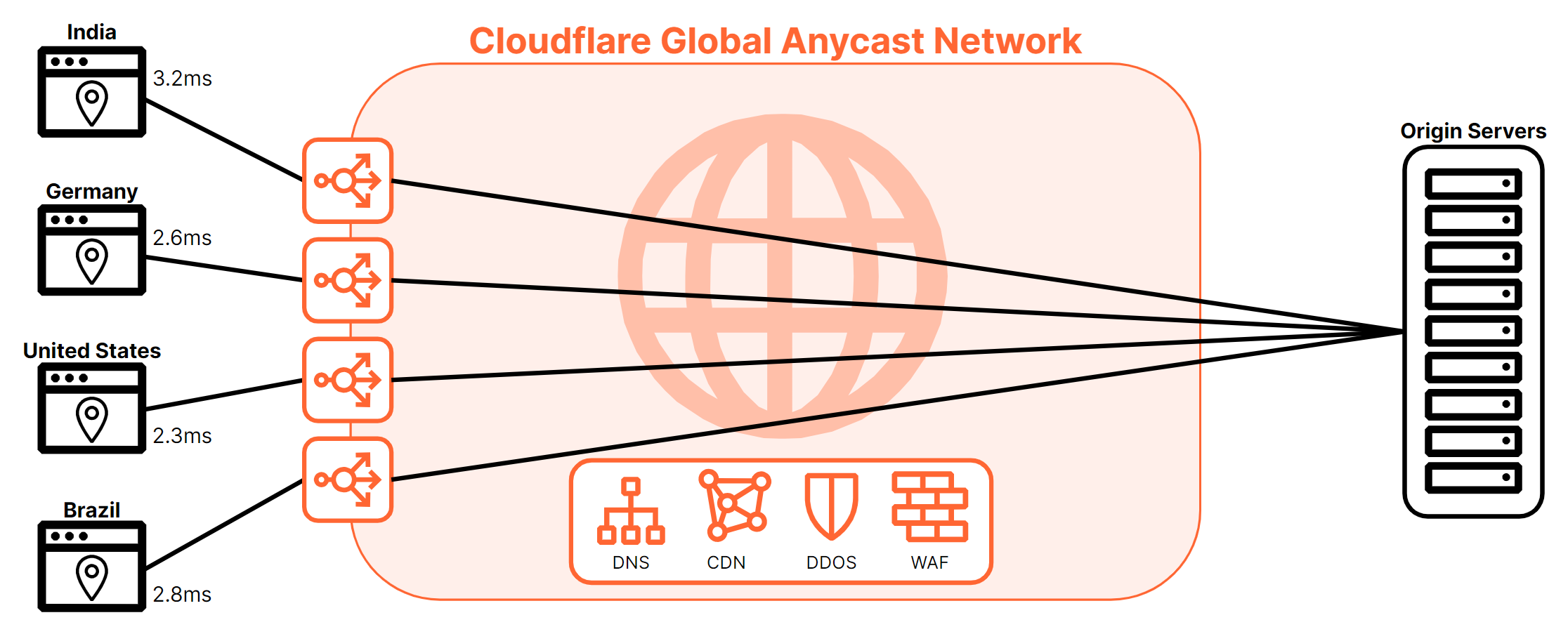
Figure 6, above, shows other Cloudflare services are also running in each of these data centers since Cloudflare runs every service in every data center so users have a consistent experience everywhere. For example, Cloudflare’s layer 7 load balancer will also be able to take advantage of other services such as DDoS protection, CDN/Cache, Bot Management, or WAF. All of these additional services can help protect your service from unnecessary traffic whether it be malicious requests (blocked by DDoS Protection, Bot Management, or WAF) or requests that can be served via cache rather than a request to origin. All of these services can be combined as needed to make a service or offering as protected, resilient, and performant as possible.

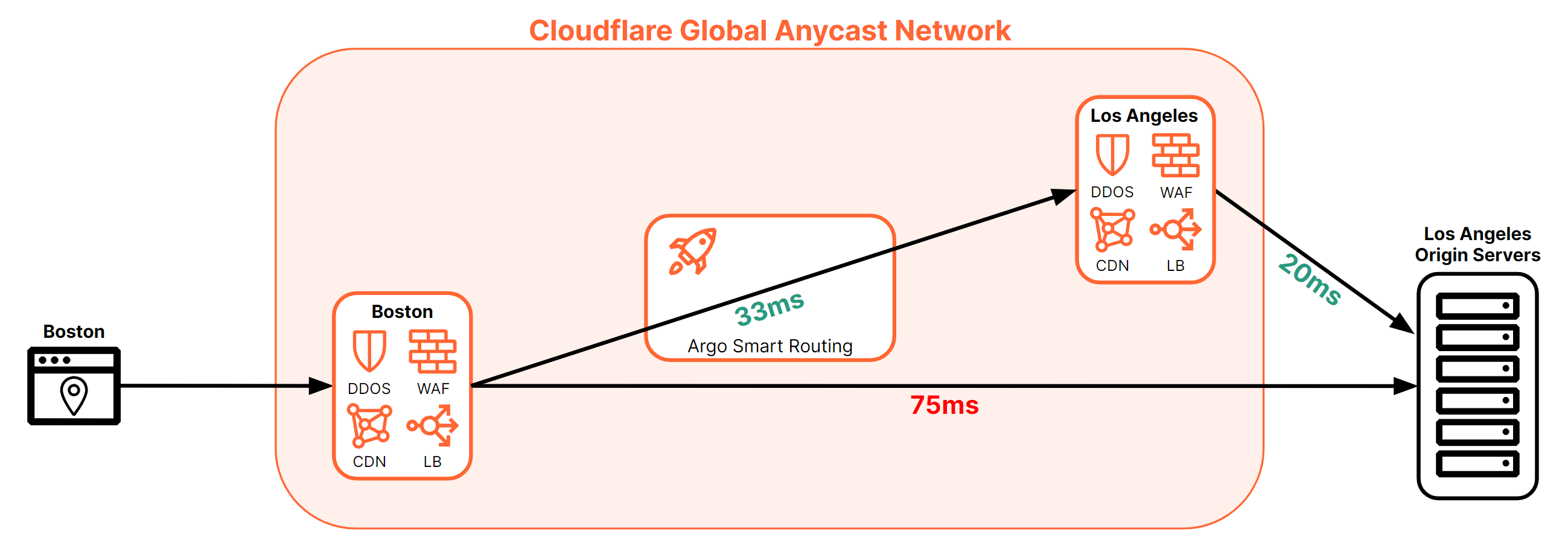
Cloudflare also has a network optimization service that is constantly running at all data centers to ensure that Cloudflare provides the best path between Cloudflare data centers and also track all the available paths to origins. This allows Cloudflare to ensure that origins can always be reached and reroute traffic to alternate Cloudflare data centers, if necessary, to reach an origin. After the load balancer has made a decision on which origin to steer the traffic, the traffic is then forwarded to Cloudflare’s network optimization service to determine the best path to reach the destination. The path can be affected by a feature called Argo Smart Routing which, when enabled, uses timed TCP connections to find the Cloudflare data center with the fastest RTT to the origin server. Figure 8 shows how Argo Smart Routing can help improve connection time to origins.
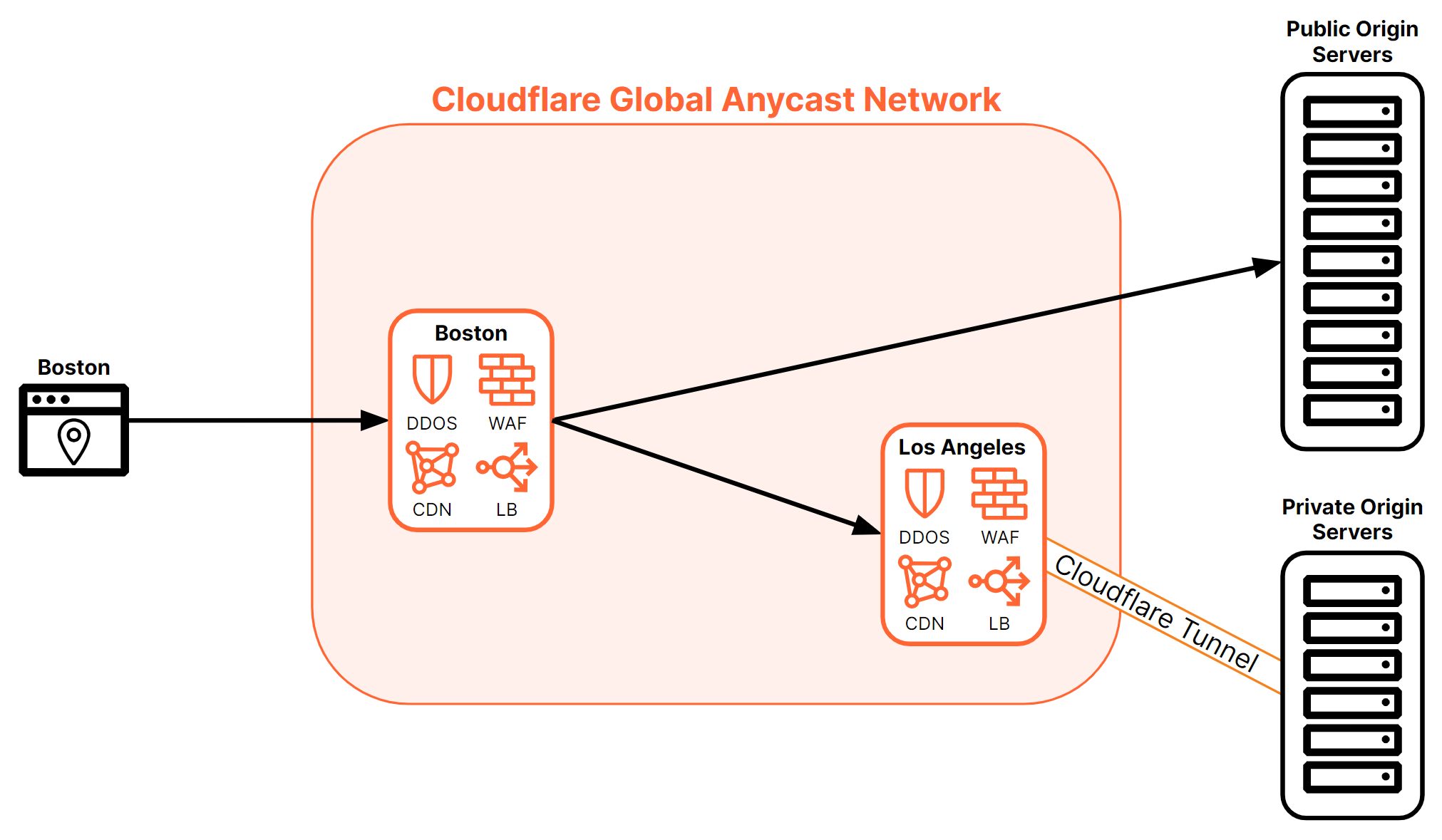
Another way traffic flow can be affected is by the use of Cloudflare Tunnels. This document covers Cloudflare Tunnels in depth in the following section. Because Cloudflare Tunnels connect origins to specific Cloudflare data centers, traffic destined for those origins must traverse those data centers to reach the origin. Figure 9 shows how connections to private origins connected via Cloudflare Tunnel must pass through the data center where the tunnel terminates.
Usually, GTM and LTM load balancers are either separate hardware or separate SaaS (GTM) and hardware (LTM) components. Cloudflare’s GTM and LTM load balancing capabilities are combined into a single SaaS offering which greatly simplifies configuration and management. There is no need to create a GTM load balancer and steer traffic to more local LTM load balancers. All origins can be directly connected to Cloudflare and traffic is steered to the correct region, data center, and origin all from a single load balancer configuration. While the concepts of GTM and LTM features will persist, their implementation in Cloudflare will be done in a way that keeps load balancer configurations as simple and straightforward as possible. Figure 10 illustrates how global traffic can be steered from any geographic region to a specific origin as needed.
The structure of a Cloudflare Load Balancer
A Cloudflare Load Balancer, often referred to as a Virtual IP (VIP), is configured with an entrypoint . Typically, this entrypoint is a DNS record. The load balancer first applies a defined traffic steering algorithm to select an origin pool, which is a group of origins selected based on function, geographic area, or region. A load balancer configuration can have one or multiple origin pools, and each origin pool can have one or many origins. After selecting an origin pool, the load balancer applies an origin steering algorithm to the list of origins and selects an origin to steer the traffic towards. Figure 11 shows the basic steps from client request to origin within a Cloudflare Load Balancer.
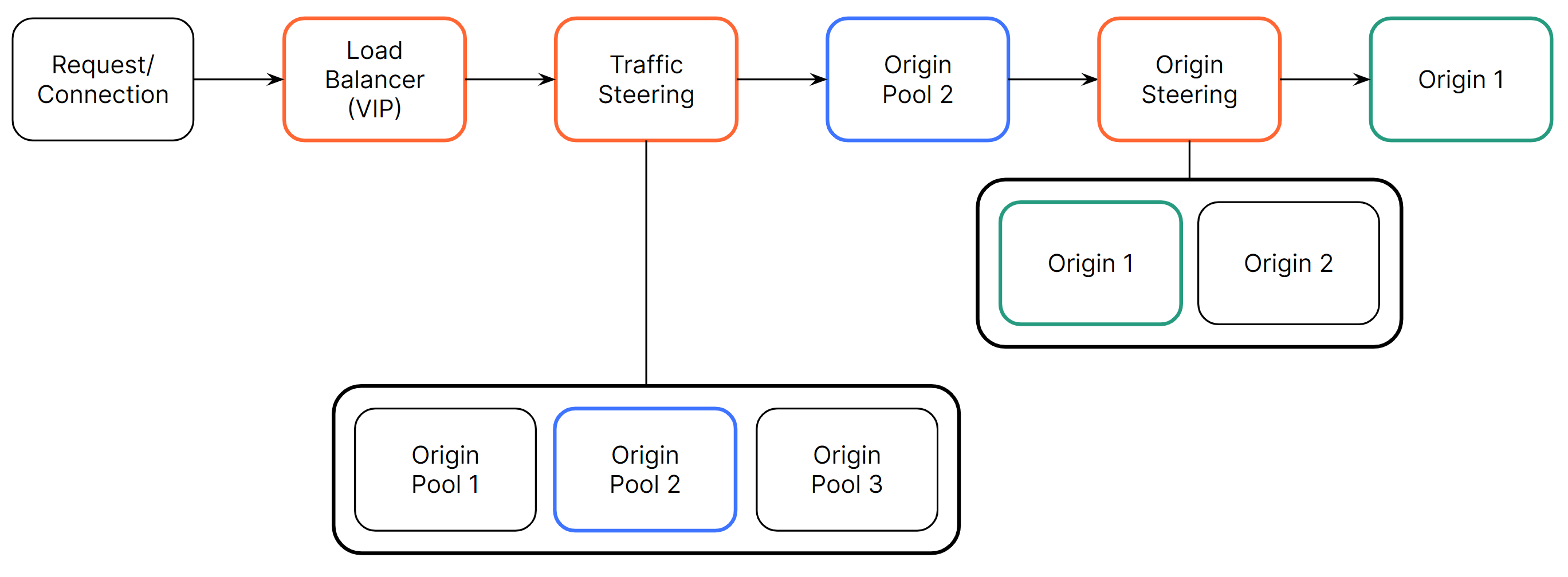
The definition of a Cloudflare Load Balancer is divided into three main components:
- Health monitors: these components are responsible for observing the health of origins and categorizing them as healthy or critical (unhealthy).
- Origin pools: this is where origins are defined and where health monitors and origin steering are applied.
- Load balancers: in this component, lists of origin pools and traffic steering policies are applied.
The following sections detail the options available and considerations for configuring a Cloudflare Load Balancer, starting with steering, which is utilized in both origin pool and load balancer configurations.
Steering types and methods
Steering is the core function of a load balancer and steering methods ultimately determine which origin is going to be selected when a load balancer is engaged. From the load balancer’s perspective, steering can be applied in two key areas.
The first is called ‘traffic steering’, and it is responsible for determining which origin pool will handle incoming requests, typically based on proximity or geographic region of the requester. The concept of traffic steering closely aligns with the idea of global traffic management.
The second area where steering is applied is after a region, data center, or origin pool has been selected. At this point, the load balancer needs to select the single origin responsible for handling the request or connection, referred to as ‘origin steering’. Steering at both of these levels is done by applying steering methods tailored to the specific needs of the customer deploying the load balancer. There are several different algorithms to choose from, but not all algorithms are applicable to both steering types.
Below is an in-depth review of all the steering methods Cloudflare offers. At the end of this section, there is a quick reference table which can be helpful in understanding which algorithms are applicable to which use cases.
Traffic steering
Traffic steering selects the group of origins, also called an origin pool. The most common use of traffic steering is to select the origin pool based on the least latent response times, geographic region, or physical location. Traffic steering is closely aligned to global traffic management and serves as the initial step in directing traffic to an origin.
Origin steering
Origin steering is responsible for selecting which origin will receive the request or connection. Origin steering can randomly select an origin, a previously selected origin (if session affinity is enabled), or it can be used to select the least utilized, fastest responding, origin for a request or connection. Origin steering is closely related to local traffic management, as it is responsible for selecting the final destination of a request or connection.
Weighted steering
Weighted steering takes into account the differences in origin pools and origins that will be responsible for handling requests from a load balancer. Origin weight, which is a required field for every origin, is only used when specific steering methods are chosen. Similarly, origin pool weight is only needed when specific steering methods are selected. Please see the steering options overview section for a quick reference for when weights are applied.
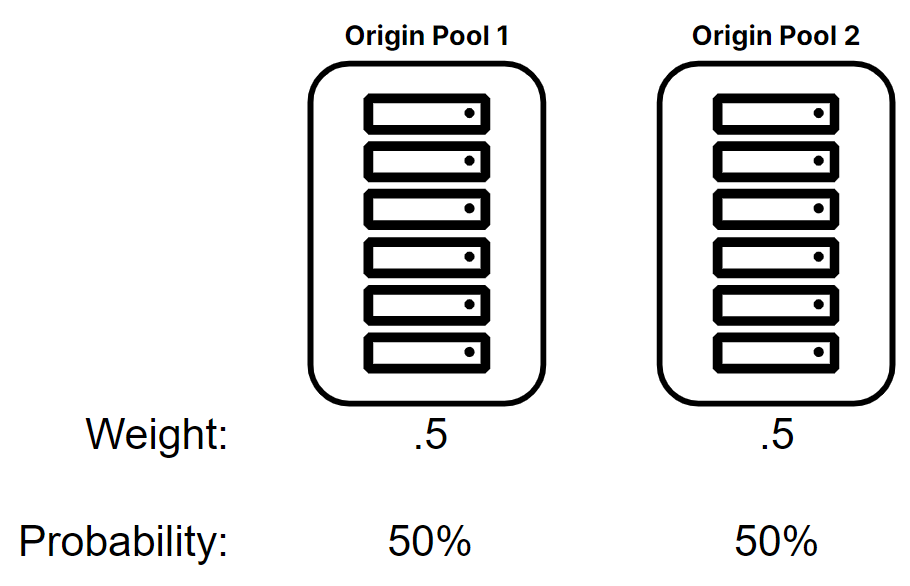
Weight influences the randomness of origin pool or origin selection for a single request or connection within a load balancer. Weight does not consider historical data or current connection information, which means that weight may have variations in distribution over shorter timeframes. However, over longer periods of time and with significant traffic, the distribution will more closely resemble the desired weights applied in configuration. It’s important to note that session affinity will also override weight settings after the initial connection, as session affinity is intended to direct subsequent requests to the same origin pool or origin. Figure 12 shows a weight example for two origin pools with equal capacity and probability of being selected.
Specific algorithms, such as Least Outstanding Request Steering, take into account the number of open requests and connections. Weight is used to determine which origins or origin pools can handle a greater number of open requests or connections. Essentially, weight defines the capacity of origins or origin pools, regardless of the selected steering method.
Weight is defined as any number between 0.00 and 1.00. It’s important to note that the total weight of the origin pools or the origins within an origin pool do not need to equal 1. Instead, the weights will be added together, and then an individual weight value is divided by that sum to get the probability of that origin being selected.
Weight to percentage equation: (origin weight) ÷ (sum of all weights in the pool) = (% of traffic to origin)
Below are some examples with diagrams to help in understanding how weight is used for distributing traffic. In these examples, it is assumed that the goal is to evenly distribute traffic across all origins with the same capacity or compute resources. Random traffic steering will be used to demonstrate traffic distribution across three origin pools.
Example 1:
- There are three origin pools defined, all with a weight of 1
- Each origin pool has a 33% probability of being selected
Example math for weight of 1: (1) ÷ (1 + 1 + 1) = (.3333) (or 33.33%)
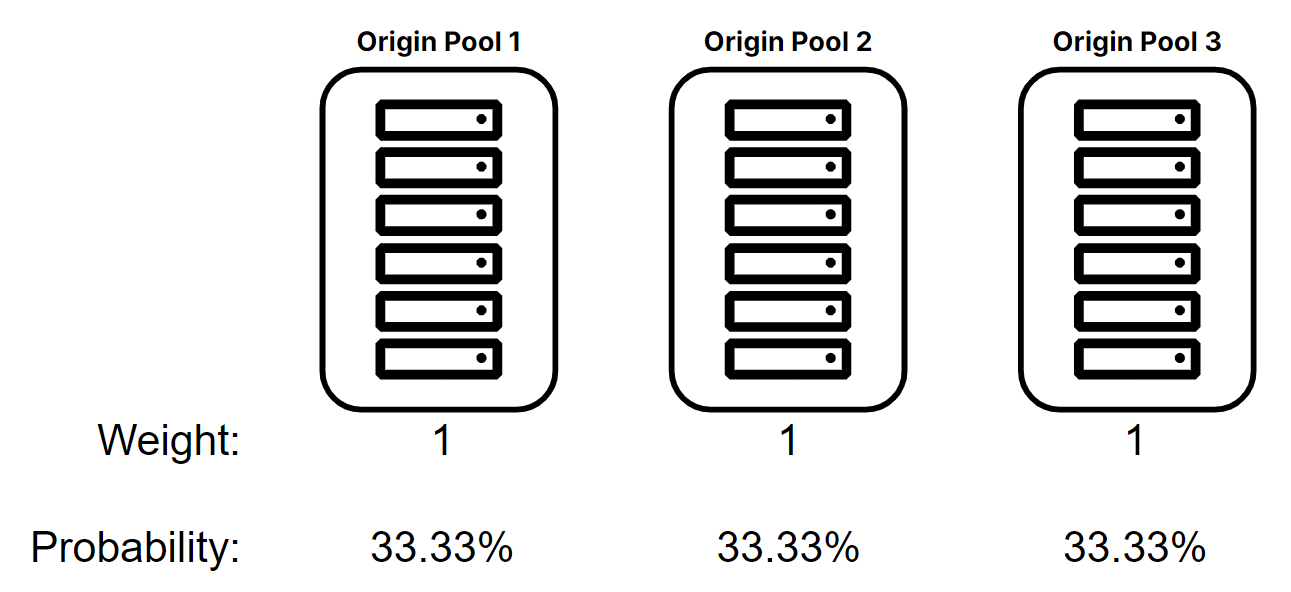
In this example, it was simple to apply 1 to all the weight values for each of the origin pools. However, it should be noted that any number between 0.01 and 1.00 could have been used as long as the same number was used across all three origin pools. For instance, setting all three pools to .1 or even .7 would have resulted in an equal probability that each pool would be selected to receive traffic.
Since the sum of the weights is used to calculate the probability, organizations can use any number of values to make these inputs easier to understand. In the following examples, since each origin has the same capacity, a value of .1 weight is assigned to each origin, and the sum of these values is used as the weight for the origin pool.
Example 2
- There are three origin pools defined
- Each origin pool has a different number of origins, but all origins have equal capacity
- To evenly distribute load across origins, each origin pool needs a different probability
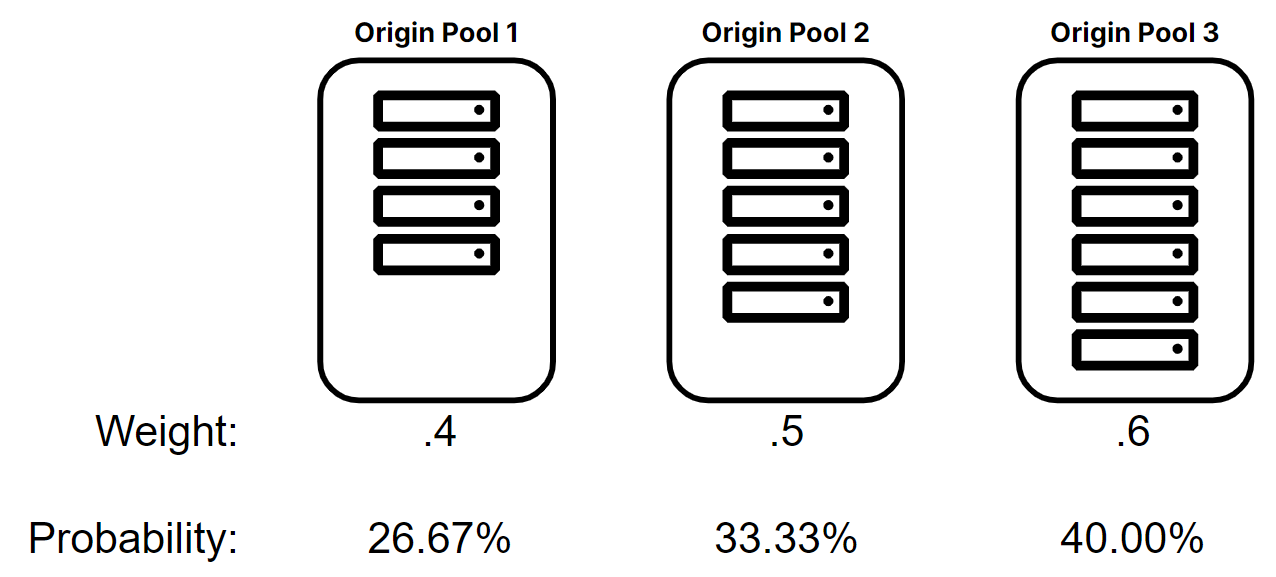
Example math for weight of .4 : (.4) ÷ (.4 + .5 + .6) = (.2667) (or 26.67%)
Example math for weight of .5 : (.5) ÷ (.4 + .5 + .6) = (.3333) (or 33.33%)
Example math for weight of .6 : (.6) ÷ (.4 + .5 + .6) = (.4000) (or 40.00%)
It is possible that origins do not all have the same capacity. In the following example, one of the origin pool’s origins has twice the capacity of the origins in the other two origin pools.
Example 3
- There are three origin pools defined
- Origin pool 1 has origins that have double the capacity compared to those in origin pool 2 and origin pool 3
- The goal is to place double the amount of traffic to origin pool 1 per origin
- Origin pool 1 has 4 origins but with double capacity, the weight of each origin will be valued at .2 for a total of .8 for the origin pool
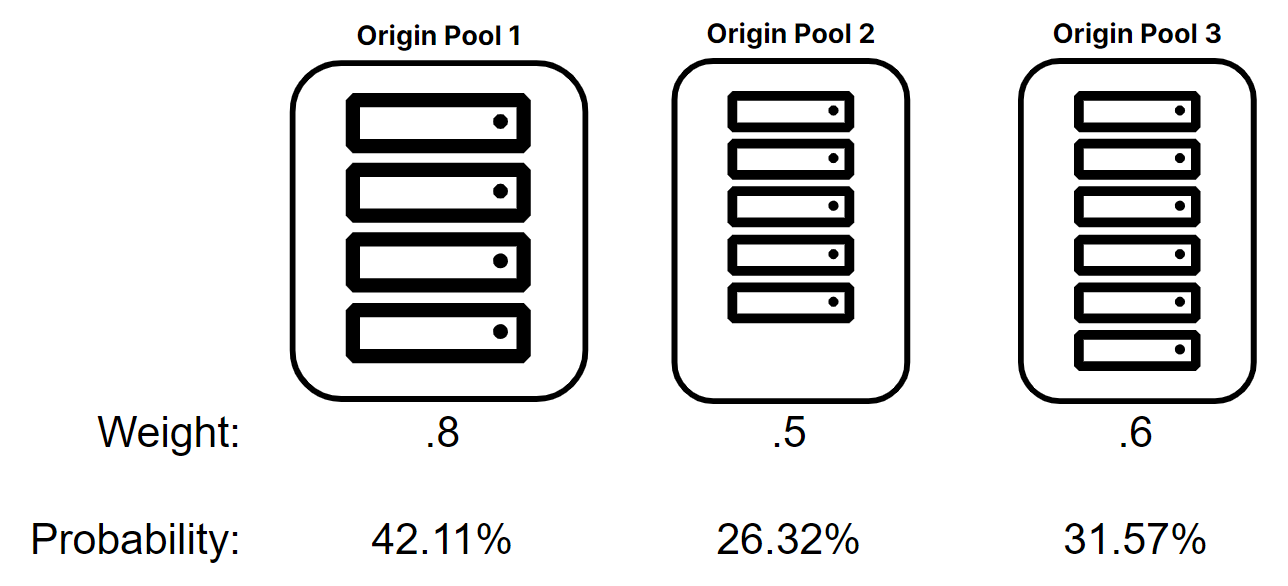
Example math for weight of .8 : (.4) ÷ (.8 + .5 + .6) = (.4211) (or 42.11%)
Example math for weight of .5 : (.5) ÷ (.8 + .5 + .6) = (.2632) (or 26.32%)
Example math for weight of .6 : (.6) ÷ (.8 + .5 + .6) = (.3157) (or 31.57%)
In this final example, since the four origins in origin pool 1 are double the capacity of other origins, the calculation treats origin pool 1 as if it essentially has 8 origins instead of 4. Therefore, the weight value of .8 instead of .4 as shown in example 2.
These are just three simple examples illustrating how weight can be used to distribute load across origin pools or origins. The same calculations are used for weights applied to origins within an origin pool as well. However, the impact of using weights within different steering methods is similar, although with slightly modified calculations, as covered in the sections below.
Weights are most useful when one origin pool might have more resources than another origin pool or when origins within an origin pool do not have equal capacity. Weight helps to ensure that all resources are used equally given their capabilities.
Steering methods
Off - failover
Off - failover is the most basic of traffic steering policies. It uses the order of the origin pools as a priority list for selecting which pool to direct traffic towards. If the first pool in the list is healthy and able to receive traffic, that is the pool that will be selected. Since off - failover isn’t available for origin steering, another steering method will be used to select an origin. Off - failover is commonly used in active/passive failover scenarios where a primary data center or group of origins is used to handle traffic, and only under failure conditions, is traffic steered towards a backup origin pool.
Random steering
Random steering is available for both traffic steering and origin steering. Random spreads traffic across resources based on the weight defined at both the load balancer configuration and within the origin pool. The weight values set at the load balancer for each origin pool can differ from the weight value set per origin within that origin pool. For example, within a load balancer configuration, 70% of traffic can be sent to one of two origin pools, then within that origin pool, the traffic can be evenly distributed across four origins. The previous section, weighted steering, provides a detailed explanation of how weight is used and the calculations that determine the selection of an origin pool or origin.
Hash steering
Hash steering is an origin steering algorithm that uses origin weight and the request’s source IP address to select an origin. The result is that every request from the same IP address will always steer to the same origin. It’s important to note that altering the order of origins or adding or removing origins from the origin pool could result in different outcomes when using the hash algorithm.
Geo steering
Geo steering is a traffic steering algorithm available to enterprise plan customers that is used to tie origin pools to specific countries or geographic regions. This option can be useful for improving performance by steering traffic to origins closer to users. It also aids in complying with laws and regulations by steering requests from users in specific regions to resources within the same region or to resources designed to meet specific regulatory requirements.
Dynamic steering
Dynamic steering is a traffic steering algorithm available to enterprise plan customers that creates round trip time (RTT) profiles. RTT values are collected each time a health probe request is made and based on the response from the origin server to the monitor request. When a request is made, Cloudflare inspects the RTT data and sorts pools by their RTT values. If there is no existing RTT data for your pool in a region or colocation center, Cloudflare directs traffic to the pools in failover order. When enabling dynamic steering the first time for a server pool, allow 10 minutes for the change to take effect as Cloudflare builds an RTT profile for that pool. Dynamic steering doesn’t use geographic boundaries in its decision making process and solely focuses on selecting the lowest RTT origin pool.
Proximity steering
Proximity steering is a traffic steering algorithm available to enterprise plan customers that steers traffic to the closest physical data center based on where the request originated.
Cloudflare determines the requester’s physical location using the following methods, in this order:
- EDNS Client Subnet information, if provided in the DNS request
- GeoIP information of the resolver used to reach Cloudflare
- GPS location of the Cloudflare data center handling the request
Proximity steering requires providing GPS coordinates for all origin pools, allowing Cloudflare to calculate the closest origin pool based on the requesting IP, DNS resolver, or Cloudflare data center.
Least outstanding requests steering (LORS)
Least outstanding request steering (LORS) is available to enterprise plan customers and can be used for both traffic and origin steering.
LORS uses the number of unanswered HTTP requests to influence steering and is only functional when used with Cloudflare Layer 7 proxied Cloudflare Load Balancers. If LORS is assigned to any other type of load balancer, its behavior will be equivalent to random steering. LORS uses the counts of open requests, along with weight, to create a new transformed weight that is used for the steering decision.
Equation for LORS transformed weight:
- weight / (count + 1) = transformedWeight
Reminder for random weight calculation:
- weight / (total weight) = probability of being selected
Here’s an example of LORS:
- Pool A has a weight of 0.4
- Pool B has a weight of 0.6
- Pool A has 3 open requests
- Pool B has 0 open requests
- Relevant equation
- weight / (count + 1) = transformedWeight
- Pool A’s transformed weight: 0.4 / (3 + 1) = 0.1
- Pool B’s transformed weight: 0.6 / (0 + 1) = 0.6
- Relevant equation
- weight / (total weight) = probability of being selected
- Pool A’s probability of being steered toward: 0.1 / (0.1+0.6) = .1429 (14.29%)
- Pool B’s probability of being steered toward: 0.6 / (0.1+0.6) = .8571 (85.71%)
In this example, the next connection has a 14.29% probability of being steered to Pool A and a 85.71% probability of being steered to Pool B. While it’s likely that traffic will be steered towards Pool B, it is still possible for it to be steered to Pool A. In situations with lighter load conditions, there will be more variation in the steering results, which may not precisely match the configured weights. However, as the load increases, the actual steering results will closely match the configured weights.
When non-L7 proxied load balancers are used with LORS, the open request count information is not available. As a result, the denominator will always be 1. Since dividing any number by 1 doesn’t change the numerator, and in this case, the numerator is the weight, steering decisions will be made solely on weight. This results in the random method described above.
LORS is best used if origin pools or origins are easily overwhelmed by spikes in concurrent requests. It is well-suited for applications that value server health over factors like latency, geographic alignment, or other metrics. This is especially useful when some or all requests put a heavy load on an origin and take a significant amount of time to generate a response.
Steering options overview
| Steering Method | Traffic Steering | Origin Steering | Weight-based | Enterprise-only |
|---|---|---|---|---|
| Off - Failover | X | |||
| Random | X | X | X | |
| Hash | X | X | X | |
| Geo | X | X | ||
| Dynamic | X | X | ||
| Proximity | X | X | ||
| Least Outstanding Requests | X | X | X | X |
All traffic steering methods marked above as Enterprise-only can also be obtained as a self-service add-on as well. All origin steering methods marked as Enterprise-Only require an enterprise plan with Cloudflare.
Health monitors
A health monitor determines the health of origins once they are configured inside an origin pool. Health monitors generate probes, which are connection attempts to origins. Health monitors use the responses to the probes to record origin health. Health monitors serve as templates that include service type, path, and port, and advanced features such as interval, timeout, and protocol specific settings for evaluating origin health The health monitor template is then applied to the origin pool, which contains origins hosting similar services. Once a health monitor is attached to the origin pool, the origin address is used as the destination for the health monitor probe. A single health monitor can be used across many origin pools, and health monitors are account-level objects, allowing them to be leveraged by multiple zones within the same Cloudflare account.
By default, health monitors probes are sent directly to the origin address, bypassing the entire layer 7 stack. This means that actual traffic to the origin through the load balancer will receive different treatment than the health monitor probe. Depending on the configuration, this could result in a health monitor reporting an origin as healthy, even if actual connections or requests are failing.
The Simulate Zone feature ensures that health monitor probes follow the same path as actual requests, passing through the entire layer 7 stack. This makes health monitors take the exact same path through the network and through other layer 7 process to reach the origin. This is required for health monitors when certain features are enabled, such as Authenticated Origin Pulls (AOP), where probes would fail if they weren’t being provided with the proper mTLS certificate for authentication on the origin. Simulate Zone also ensures health monitor probes use the same path provided by Argo Smart Routing and the same dedicated egress IPs when organziations leverage Aegis to restrict the edge IP addresses that Cloudflare uses to reach their origins.
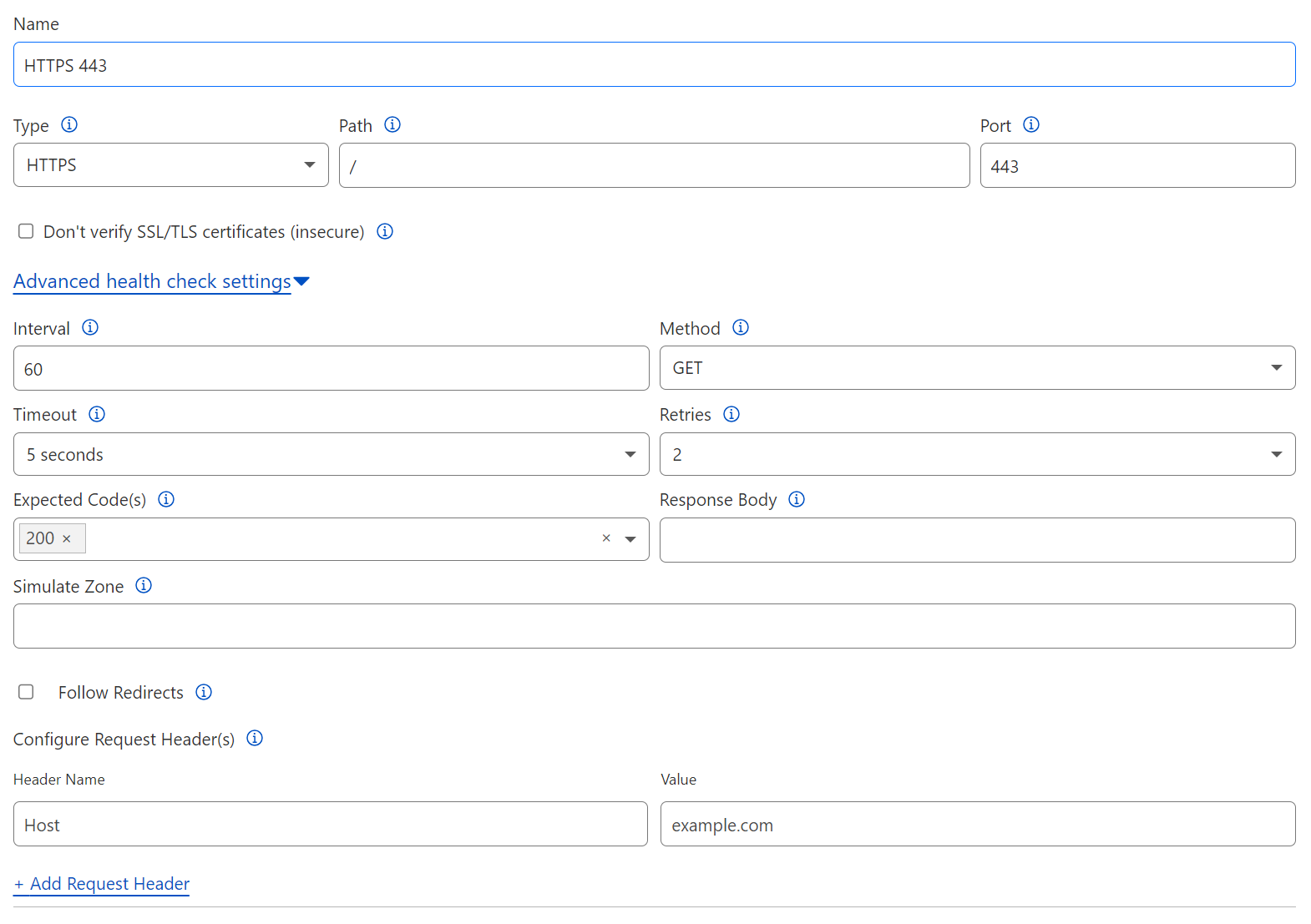
Health monitor Probes can be configured as the following types:
- HTTP
- HTTPS
- TCP
- UDP ICMP
- ICMP Ping
- SMTP
- LDAP
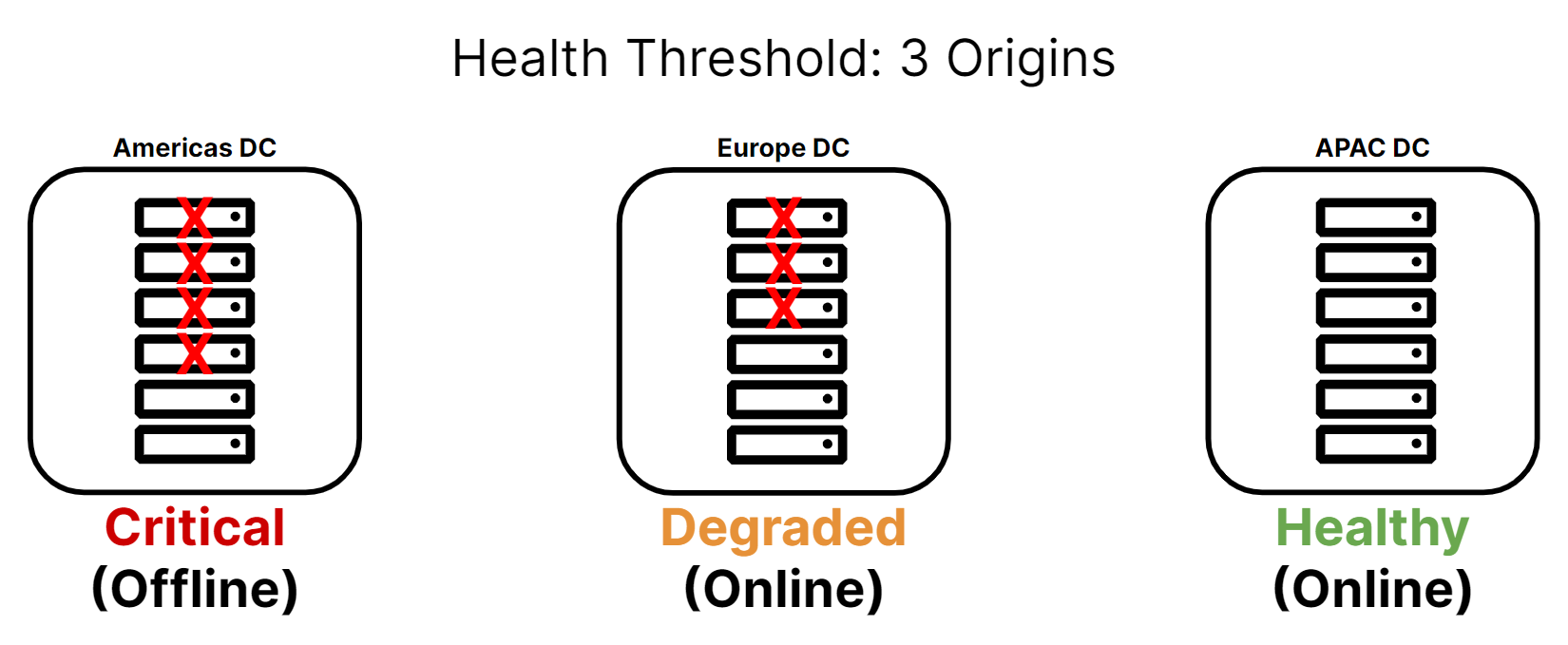
Once a health monitor is defined, it can be assigned to an origin and the probes will be sent to the origin at the interval defined. There are two additional settings to note in regards to the health monitor configuration within the origin pool. The first is the Health Threshold, which is used to determine how many origins within the pool need to be healthy in order to consider the origin pool to be healthy or degraded.
- Origin pool in healthy state
- Contains only healthy origins
- Origin pool in degraded state
- Contains at least one critical origin but remains at or above the health threshold setting
- Origin pool in critical state
- Contains healthy origins below the health threshold
- Not capable of handling traffic; removed from all steering decisions.
The second setting after defining the health monitor in the origin pool is to define which regions the health monitor probes should source from inside the Cloudflare global network. The available selections are listed below:
- All Regions (Default)
- All Data Centers (Enterprise Only)
- Western North America
- Eastern North America
- Western Europe
- Eastern Europe
- Northern South America
- Southern South America
- Oceania
- Middle East
- Northern Africa
- Southern Africa
- Southern Asia
- Southeast Asia
- Northeast Asia

With the exception of “All Regions” and “All Data Centers”, health monitor probes will only originate from data centers in the selected region or regions. For locally relevant services, it may not matter whether or not a data center on the other side of the world can reach the origins. Therefore, limiting checks to a specific region or a set of regions may make sense. The selection of “All Regions” or “All Data Centers” is intended to be used for globally available services where reaching a set of origins could be crucial to the function of the application.
Origins and origin pools
Origins are the actual servers that handle connections and requests after a load balancer has applied all its policies. Origins can be physical servers, virtual machines, or serverless applications. As long as they can handle a request or connection from a user or client, they can be considered an origin. There are several different methods of defining and connecting origins to Cloudflare and the next section details those methods.
Connecting origins to Cloudflare
Cloudflare origins can be defined in two ways, by IP address or by hostname. IP addresses are the most straightforward and basic of connection methods, hostnames offer a few options to consider. A hostname can be defined in Cloudflare DNS and it can be proxied or DNS-only (unproxied). Another option, of course, is that the hostname is not in a domain which Cloudflare is an authoritative DNS server for which means Cloudflare will rely on outside DNS servers to resolve that hostname to an IP address. Cloudflare Tunnel can also be used and offers two different options as well. These methods are discussed below in this section.
Cloudflare proxied, DNS, IP, and non-Cloudflare origins
As mentioned in the “HTTP(S) Load Balancing” section above, load balancing is the very last process run before a request is sent to an origin. In the case of however, even if an origin is proxied via Cloudflare’s edge, after the load balancer, the request is forwarded directly to the origin without passing through the layer 7 stack again. This doesn’t mean the origin is unprotected or uncached, however. As long as the load balancer itself is proxied then all those protections are provided to the load balancer rather than the origins. Any direct communication with the origin can still be proxied and treated with Cloudflare’s layer 7 stack, but communication with an origin places all the processing in front of the load balancer, not the origin. Figure 19 illustrates the difference of where the Cloudflare layer 7 stack is placed in relation to the origin(s).
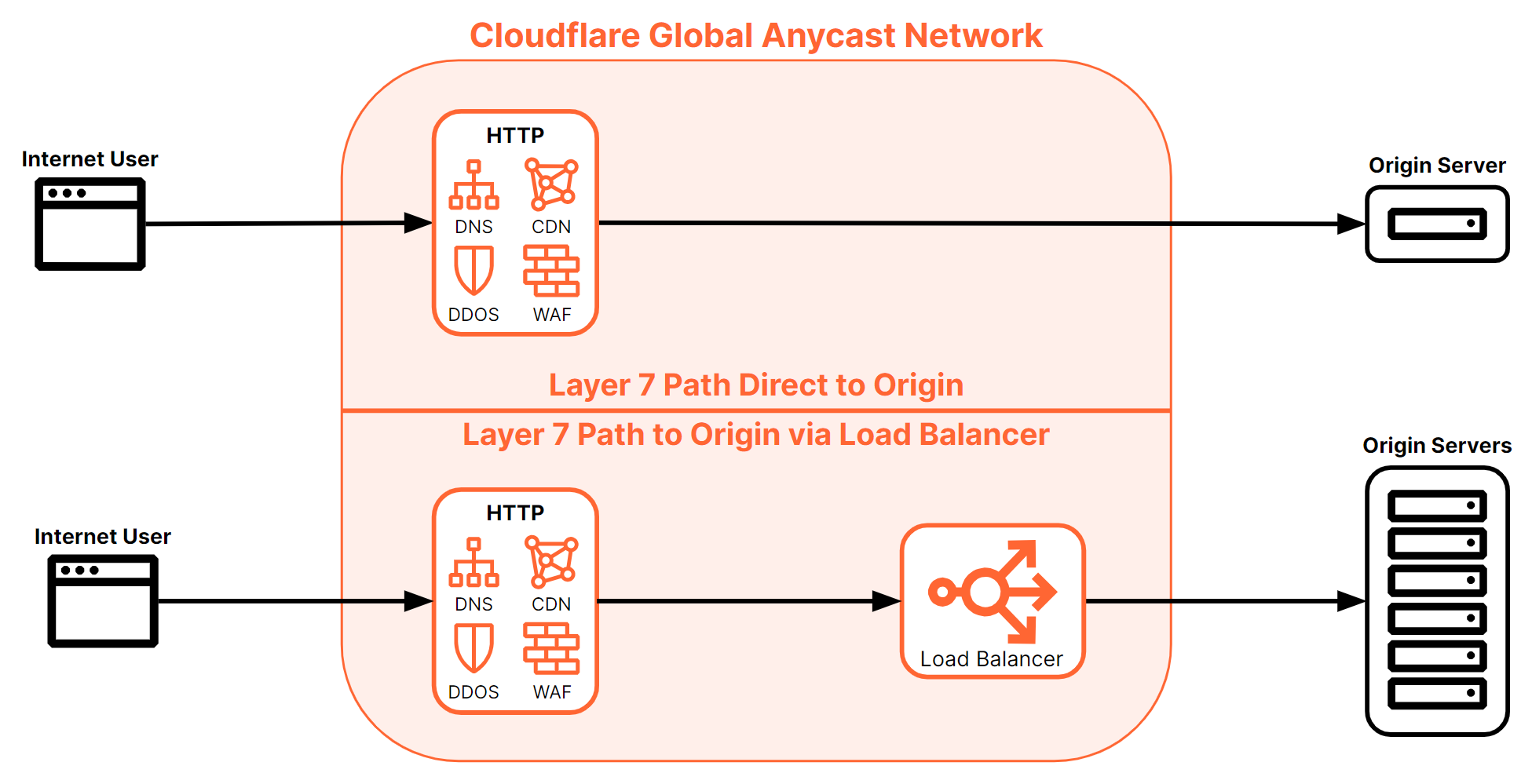
There are very few differences from a load balancer perspective when it comes to what type of origin is defined as part of an origin pool. Once the traffic and origin steering policies and the load balancer rules are applied, the Cloudflare Load Balancing service instructs the L7 stack where to forward the incoming request or connection . This request is sent directly to the origin. Depending on the type of connection to the origin, there may be a different path. Features like Argo Smart Routing or tunnel-connected origins that are terminated at different Cloudflare data centers will route traffic differently rather than sending the request out of the Cloudflare edge, over the internet, directly to the origin. Regardless of the path, however, load balancing is the last process in the stack and this means that traffic doesn’t receive any additional treatment. So while the connection to origin can change the path from Cloudflare to the origin, the treatment or processing doesn’t change once an origin is selected.
Cloudflare Tunnel
Cloudflare Tunnel is an outbound connection that enables organizations to simplify their firewall configurations, reduce complexity, enhance security, and more easily join their assets to the Cloudflare network. The executable that creates these tunnels is called cloudflared and may be referenced in this document and diagrams that follow.
Cloudflare Tunnel (cloudflared) can be installed directly on the origin server or any server with IP connectivity to the origin server. And because the connection to Cloudflare is initiated from the origin server to Cloudflare, the only access needed is outbound access to Cloudflare. A single Cloudflare Tunnel can transport traffic to one or many different origins in one of two different ways, one which results in the origin being publicly accessible and one which keeps the origin completely only accessible privately.
Cloudflare Tunnel can be installed on the origin itself or on any server with layer 3 (IP) connectivity to the origin or origins that need to be connected to Cloudflare. The decision to separate cloudflared could be made for many different reasons including but not limited to isolating the origin(s) and ensuring their performance, having separate teams that manage network level connectivity and origins, or separation for architectural simplicity where servers have segregated roles or responsibilities.
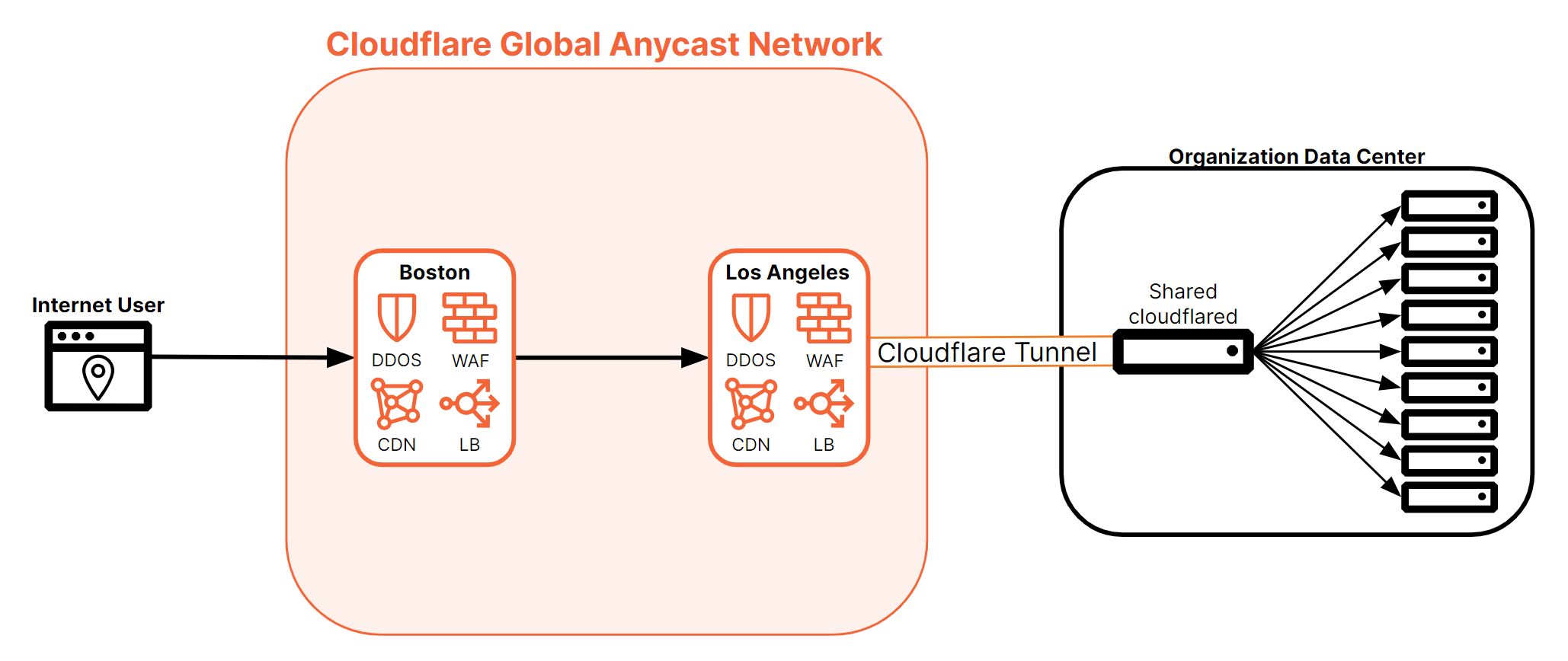
A single cloudflared instance will create 4 different tunnels, two tunnels in two different Cloudflare data centers. This model ensures high availability and mitigates the risk of individual connection failures. This means in event a single connection, server, or data center goes offline, the origins will remain available. Cloudflare Tunnel also allows organizations to deploy additional instances of cloudflared, for availability and failover scenarios. These unique instances are called replicas. Each replica establishes four new connections which serve as additional points of ingress to the origin(s). Each of the replicas will point to the same tunnel. This ensures that your network remains up in the event a single host running cloudflared goes down. By design, replicas do not offer any level of traffic steering (random, hash, or round-robin).
Public hostname
The public origin method allows organizations to define a tunnel that points to a specific service or port running on an origin server. The tunnel can terminate on the origin server or on any server with IP connectivity to the origin. Using this public hostname method requires that each service that will be accessed over the tunnel is defined in the tunnel configuration. When configured, a unique tunnel ID, such as d74b3a46-f3a3-4596-9049-da7e72c876f5, will be created for the IP and port or service for which the tunnel is connecting traffic. This tunnel ID is then created into a unique public hostname in the Cloudflare-owned domain of cfargotunnel.com which results in a DNS A record being created that points directly to that service, I.E. d74b3a46-f3a3-4596-9049-da7e72c876f5.cfargotunnel.com. While this hostname is public it can only be accessed or utilized by traffic that is sent through the account that owns the Cloudflare Tunnel configuration. No other accounts would be able to access or send traffic directly to this DNS address. A DNS CNAME record created outside of the account that owns the cfargotunnel.com hostname will not be able to send traffic through that specificCloudflare Tunnel.
When configured via the Dashboard, Cloudflare automatically creates a CNAME record in the DNS zone that refers to the cfargotunnel.com hostname. For example, a CNAME record of myTunnelService.example.com could be created to point the A record of d74b3a46-f3a3-4596-9049-da7e72c876f5.cfargotunnel.com. The main benefit being the ease of use and administration as the CNAME record is much more suggestive about its purpose and belongs to the customer DNS zone.
Another option is to create these tunnels and services on the host running cloudflared. This is called a locally-managed tunnel. When working with locally-managed tunnels, the CNAME entry is not created automatically however, so the organization would have to configure this manually, after the tunnel and service is defined.
From a load balancer perspective, it’s very important to understand how these tunnels can be used as an origin. An origin can only be defined by using the cfargotunnel.com hostname. Using a public CNAME record that points to the cfargotunnel.com address will not work properly and is not supported. This is especially important for origin services that don’t operate on ports 80 or 443. Cloudflare Load Balancers default to these two ports to access the services running on the origins. If an organization has services running on other ports, they will need to configure a Cloudflare Tunnel with a catch-all rule to reach that port. This configuration allows a Cloudflare Load Balancer to reach the service via port 443 while having Cloudflare tunnel proxy the connection to the desired port on the origin.
Private IP
The second method is for private subnets. This method allows organizations to define private IP addresses and a subnet mask which will be used to create a private virtual network within the Cloudflare global network. The private subnet method does not allow the definition of a port and as such, once a subnet and mask are defined, the entire subnet can be reached over that tunnel but only to users within the organization that are allowed access via defined Zero Trust policies.
This subnet then gets added to the virtual network inside of Cloudflare where the customer can control how users can access it and which users can access it. This subnet can be defined for any desired subnetting or routing, including using a 32-bit mask (single IP address, IE. 10.0.0.1/32). The allowed subnet does not need to exist on the host that is running the cloudflared process either. All that is required is layer 3 or IP connectivity between the host running cloudflared and the subnet that is going to be reachable over Cloudflare Tunnel.
Origin pool details
Within the origin pool, there are several configuration options. This section details what these configuration options are and how they alter the behavior of a Cloudflare Load Balancer.
Origin steering
The first configuration, besides defining a name and description of the origin pool, is to determine the origin steering method. Origin steering is responsible for ultimately selecting the origin or endpoint that will receive the request or connection attempt. (Please refer to the Steering methods section for a detailed description of each method.)
Origins
Individual origins are defined within origin pools, and the origin pool allows for one or more origins to be defined per pool.
- The origin name is primarily used for reference, reporting, and analytics; it does not affect the function of the load balancer or origin pool.
- The origin address, however, defines a resource that the load balancer can use to handle a request or connection.
- Origins within an origin pool must be accessible over port 80 or 443. If the origin is not listening on port 80 or 443, then either a proxy service or network port forwarding device needs to be placed in front of the origin to map port 80 or 443 to the port that the service is actually listening on.
- Another method for mapping ports of origins to 80 or 443 is to connect to the origin service using Cloudflare Tunnel, and then use the hostname created through that process as the origin address. This will automatically map the intended origin port to port 443.
Origin address can be defined in one of the following ways:
- Publicly routable IP address
- Cloudflare-proxied publicly reachable hostname
- Publicly reachable non-Cloudflare hostname
- Private, non-publicly routable IP address with the selection of a virtual network
Virtual networks
Using public IPs and hostnames of any type require no additional configuration. In those scenarios, the virtual network should be set to the default value of “none”. The “none” setting signals that these resources will be accessible on the public Internet, routed via Cloudflare’s global edge network.
The use of the virtual network option is reserved for private IP resources. This setting maps to IP subnets that are hosted behind Cloudflare Tunnel configurations. A virtual network should be selected that has a route to the IP address of the origin. To navigate to this setting in the Cloudflare Dashboard, select Networks - Routes from the Zero Trust page.
Origin weight
Origin weight is only used for the random, hash, and least outstanding request steering methods; it must always be defined as part of the origin definition. (Please refer to the Weighted Steering section for more information on how weights are used for origin selection.)
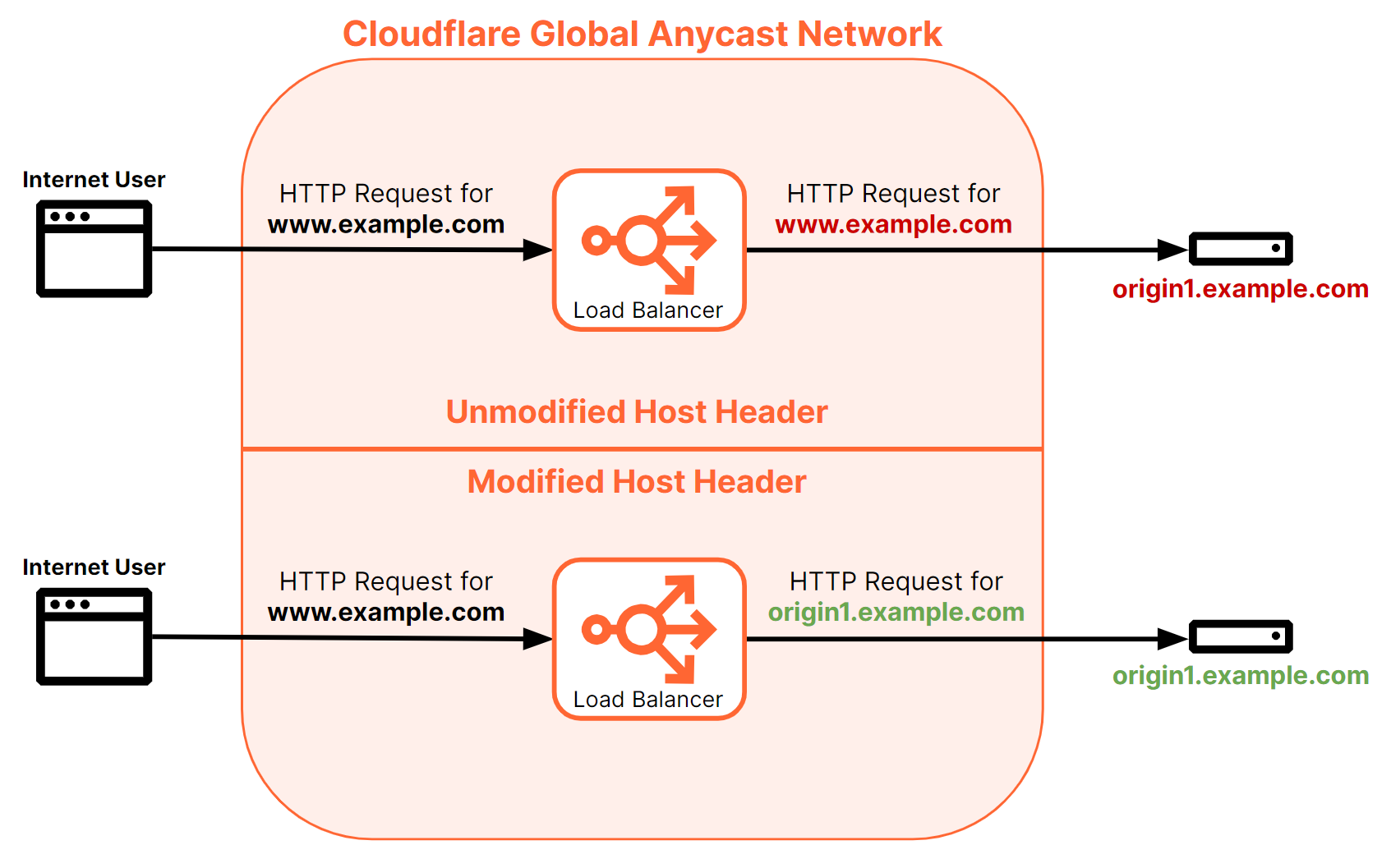
Host header modification
Origin pools allow for the host header to be modified before dispatching a request to an origin. This configuration only applies to the HTTP(S) layer 7 load balancer. (It will be ignored when used with layer 4 load balancers, including private IP and Spectrum.)
Within a layer 7 load balancer where requests are HTTP(S)-based, the Host header tells the origin which website is being requested, as a single origin may host several different web domains. When an origin is specifically configured to host a web domain, it may either not respond or send a failure response to a request for a resource, if it does not believe it is hosting the resource requested in the Host header (i.e., if there are mismatched Host headers).
For example:
- Say a user tries to reach
www.example.com. The load balancer will be configured with the hostname ofwww.example.comto receive all the requests. - Since the origins can’t have the same public hostname in DNS, its hostname is
origin1.example.com. - When the user makes a request to
www.example.com,the Host header will be set towww.example.com,as well. The origin will need to be configured to respond to Host headers ofwww.example.com. - In some cases (such as with certain cloud or SaaS applications), however, origins aren’t configurable in that manner, so the origin may receive a request with an unknown Host header and fail to respond appropriately.
- In this example, in the origin configuration, setting the Host header for the origin to the origin address of
origin1.example.comwill replace the Host header ofwww.example.comwithorigin1.example.com, and will allow the origin server to properly respond to this request.
Figure 21 highlights the potential problem of mismatched Host headers:
Also, at the origin pool, GPS coordinates for the pool (which are used with proximity traffic steering) can be defined. If proximity steering is not being used, then these coordinates are not required. (Please refer to the Proximity Steering
Load shedding
Load shedding — a real-time response available to administrators to protect against origins in a pool that are becoming unhealthy — is also configured on the origin pool.
The load shedding setting is not intended to be enabled unless an administrator is trying to actively protect an origin pool from becoming unhealthy. It is activated, for example, when an origin that is still responding to requests is experiencing increased CPU or memory usage, increased response times, or occasionally failing to respond at all.
When an origin pool’s health begins to degrade, load shedding can help direct some of the existing loads from one origin pool to another.
Depending on the health of the origin pool, it may be enough to simply shed or redirect new requests and connections away from the origin pool. This policy applies to traffic, which is not subject to any session affinity rules since these are new connections that haven’t had an origin pool or origin selected yet (and, therefore, will not potentially affect the end user experience).
Should an origin pool approach critical failure due to load, the next option is to shed additional session affinity traffic. This will start to redirect requests and connections that are bound to origin pools through session affinity as well. However, please note that because this process can ultimately change the user’s origin, it could impact the end user’s experience. Ultimately, the impact is determined by the application that is being load balanced, and how much connection context is shared between origins.
Health monitors
Health monitors are attached to origins at the origin pool as well as health threshold and the health check region selection. Details of these options can be found in the health monitor section.
Load balancers
Load balancing within Cloudflare combines both GTM and LTM load balancing into a single load balancer configuration. While certain features or terms may align more with GTM or LTM load balancers, for Cloudflare customers, both are combined into a single, easy-to-manage instance.
Depending on their specific use case, organizations can leverage different types of Cloudflare Load Balancers. The following section highlights the main differences between the deployment models, and articulates when each type of load balancer should be implemented.
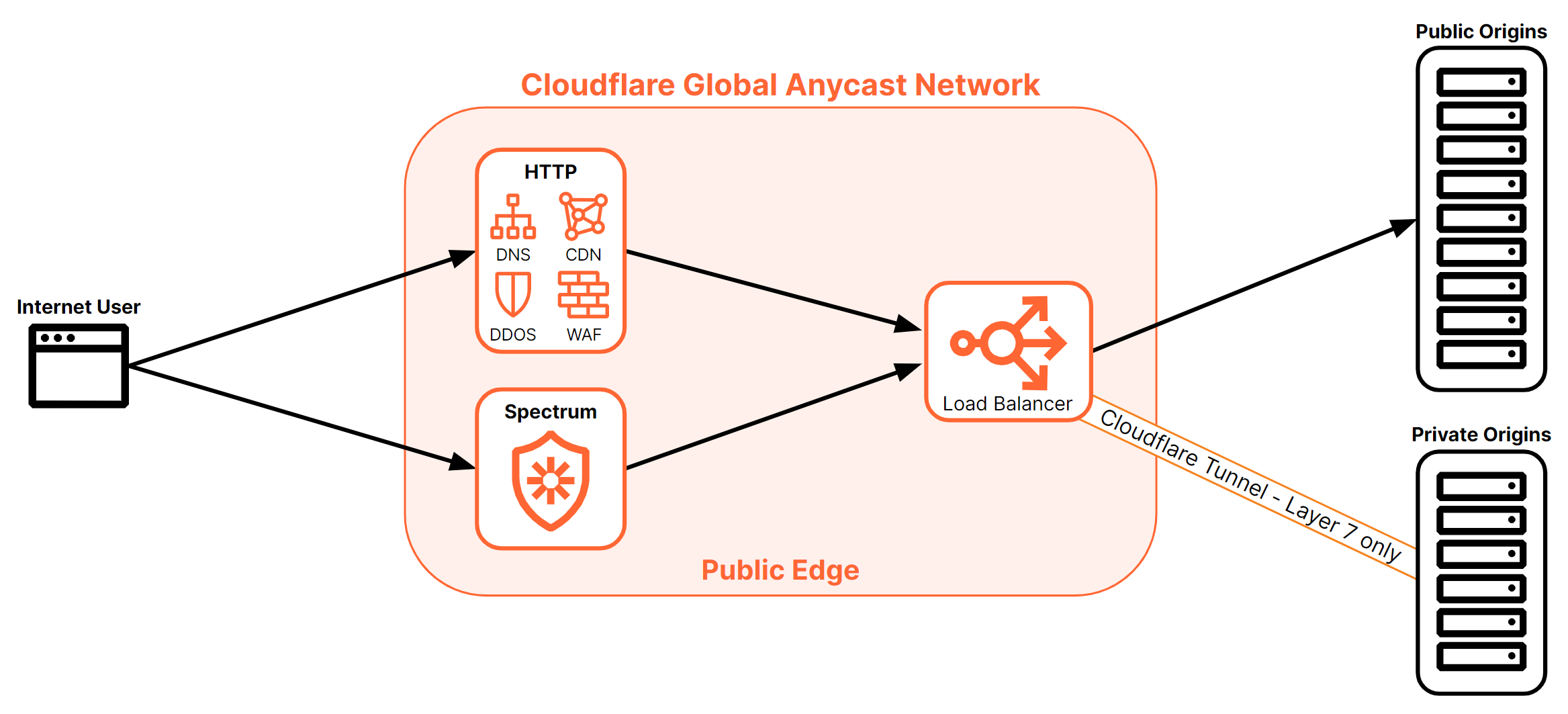
Figure 22 highlights all the possible combinations of load balancers and origins supported by Cloudflare:
Deployment models
Cloudflare offers three load balancing deployment models, each of which support different use cases, functionality, and privacy requirements.
Except for the DNS-only load balancing option described in more detail below, all of the deployment models anchor traffic through the load balancer. This means the user or client creating the request or connection is never aware of the origins that are being used to service the request or connection. Origin information can certainly be exposed — if desired — through the use of headers, but this is not default behavior for any of these anchored deployment models.
The following explores the four main deployment models (and their differences) in more detail.
Layer 7 HTTP(S) load balancing
First, the most common model is the HTTP(S)-based layer 7 proxied load balancer. These load balancers exist on Cloudflare’s edge and are publicly reachable. Amongst other features, this model supports WebSockets, which are open connections between the client and origin allowing for data to be passed back and forth between the two.
Because this same layer 7 security stack also provides WAF, DDoS protection, Bot Management, Zero Trust, and other services, accessing these public load balancers can be restricted to authenticated and authorized users as needed. (Please refer to Securing Load Balancers for more information.)
In this layer 7 stack, load balancing can further improve the performance, reliability, and reachability of an organization’s public-facing web assets. The origins for these load balancers may be deployed in public cloud, private cloud, on-premises, or any combination thereof within the same load balancer. (Please refer to Connecting origins to Cloudflare for more details about how to connect origins to Cloudflare’s edge network).
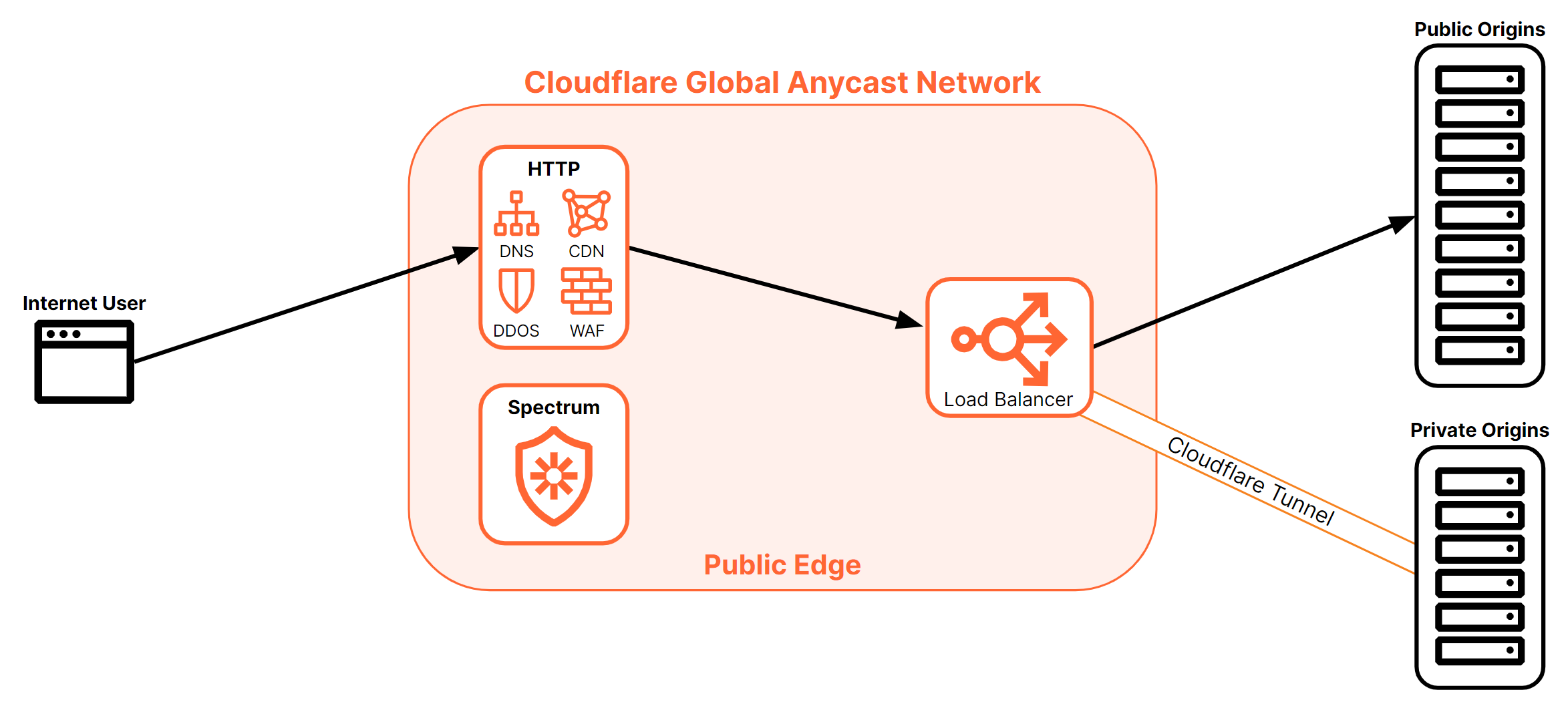
As illustrated in Figure 23 above, the load balancing component of the layer 7 stack is the last process run on a request as it moves towards the origin. This can have a large positive impact on increasing performance and reducing load on origins.
For example, caching can prevent requests from ever reaching the origin servers and can be responded to without ever having to engage the load balancers. Also, WAF, DDoS protection, and Bot Management can eliminate attack traffic altogether — leaving more capacity for legitimate traffic.
Once a request reaches the load balancer process, the request is always sent directly to the origin that was selected. This means that even if the origin is proxied through Cloudflare, the request will be sent directly to the origin and receives no further processing.
For customized treatment after the load balancer selects an origin, the load balancer’s Custom Rules are applied. (This is covered in detail in the Load balancers section below).
Important notes about Layer 7 HTTP(S) load balancers:
- Layer 7 HTTP(S) load balancers support both public and private origins
- Layer 7 HTTP(S) load balancers will only support HTTP(S) and WebSocket traffic
- Zero trust policies can be applied to Layer 7 HTTP(S) load balancers
DNS-only load balancing
Cloudflare’s DNS-only load balancer is an unproxied load balancer. This means that only the initial DNS request for the resource — not the actual traffic — passes through the Cloudflare edge. Therefore, instead of a DNS request resolving to a Cloudflare IP and then moving through the layer 7 stack as seen earlier in Figure 7, Cloudflare receives a DNS request for a DNS-only load balancer, applies all the appropriate load balancing policies, then returns an IP address to the requesting client to reach out directly.
Because all the traffic between the client and the origin will travel directly between the two and not through Cloudflare’s layer 7 stack, any type of IP traffic can be supported by a DNS-only load balancer.
Even though Cloudflare does not proxy these types of load balancer connections, the health monitor service is still monitoring the health on all the origins in the pool. Based on the health or availability of an origin, a Cloudflare DNS-only load balancer will either add or remove an applicable origin to a DNS response to ensure that traffic is being steered to healthy origins.
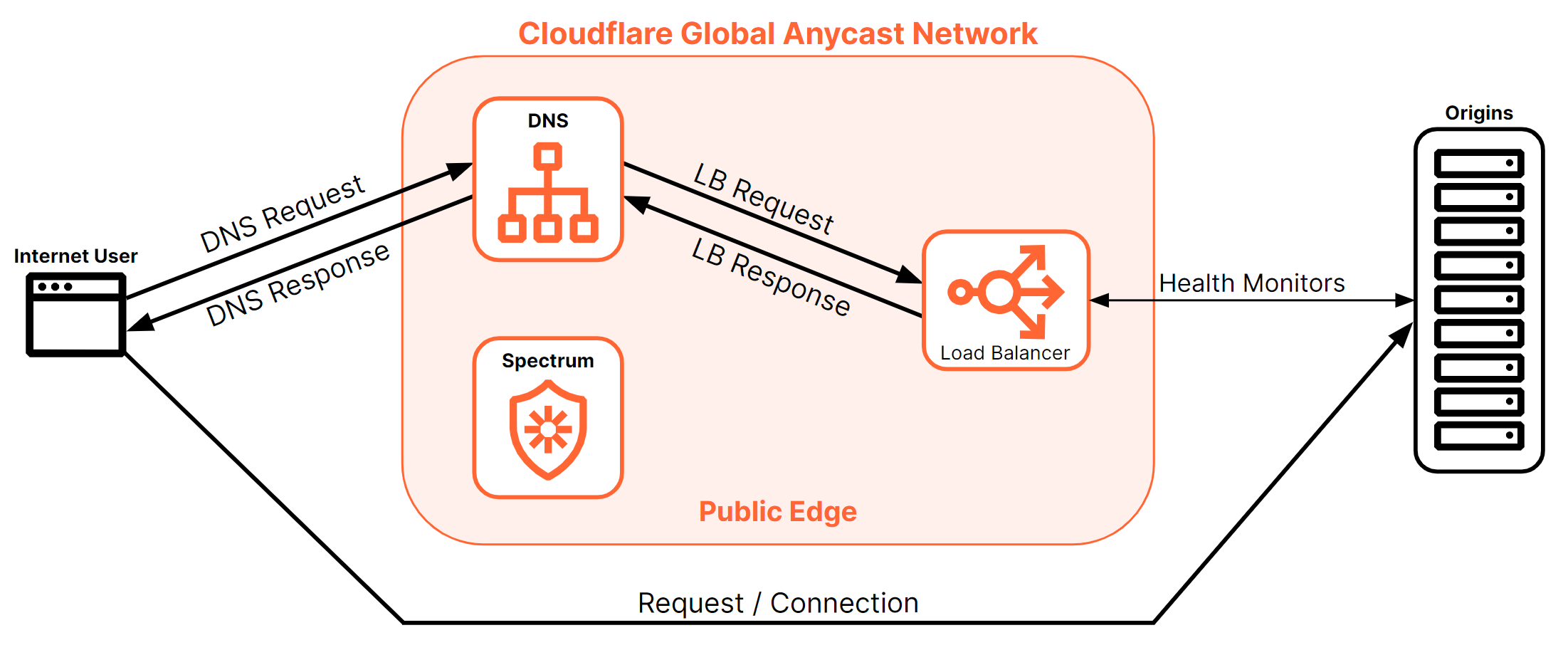
After a DNS-only load balancer has selected an origin pool via traffic steering, one or many IP addresses may be returned in the DNS response.
The decision to send one or many IP addresses within the DNS response is based on the weight assigned to the origins within the selected origin pool:
- If all the weights are equal across all origins, all IP addresses of all the origins will be returned in DNS response.
- If at least one origin is specified with a unique weight within the origin pool, then only a single IP address will be returned in the DNS response — regardless of the origin steering method selected on the origin pool.
This gives organizations the flexibility to allow applications to be aware of all the origins and perform local failover, or to allow Cloudflare to provide a single IP for an application to utilize.
Figure 27 shows how the defined weight within an origin pool can affect how a DNS-only load balancer responds.
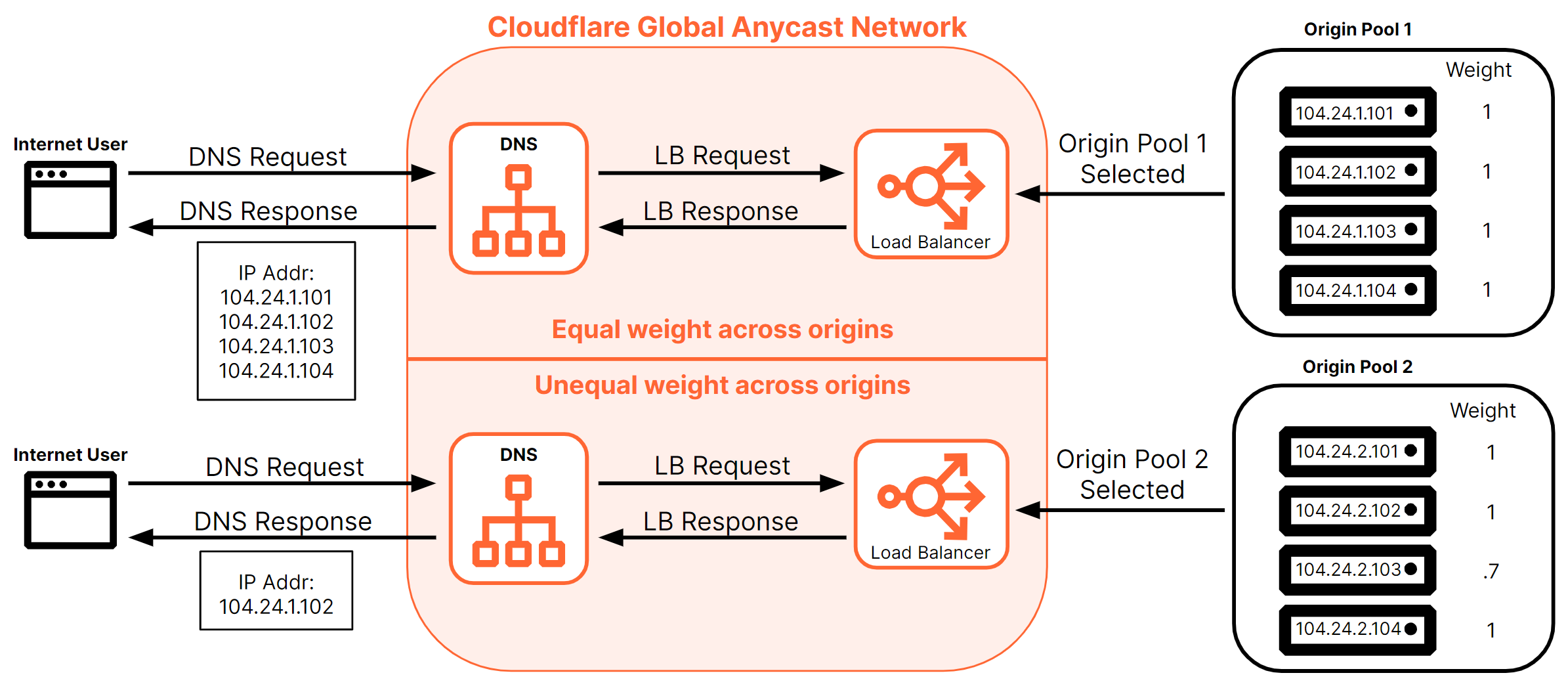
Please note that DNS-only load balancers have a few limitations compared to proxied load balancers:
- The load balancer no longer hides the origin’s IP address from the client as it is sent back to the client directly.
- They do not have the built-in layer 7 stack services mentioned in the previous model; i.e., DNS-only load balancers do not include caching, WAF, DDoS protection, or Zero Trust support.
- Session affinity is limited to
ip_cookie, which will select an origin deterministically and then map that origin to the client IP address for all subsequent requests. - Finally, because connections are not proxied through the load balancer for DNS only, certain steering methods will not work either. For example, LORS will not work since Cloudflare will not be aware of the connections to the origins. These steering methods will revert to random weighted steering.
For more information on additional steering methods, please refer to the Steering section.
There are also client and resolver DNS cache considerations when using DNS-only load balancers. The cache life is determined by the DNS server answering the request. The Time-to-Live (TTL) value tells a DNS requester how long the response is valid before the client should send a new DNS request to see if the destination has changed. The TTL is calculated in seconds, so — for example — a TTL value of 3600 equates to a TTL of one hour. However, standard DNS TTL values are usually either 12 or 24 hours or 43200 and 86400 respectively.
The TTL of a DNS-only load balancer is set to 30 (seconds). This ensures that as origin health changes or origins are added or deleted, the DNS-only load balancer is queried more often to provide the most accurate list of available origins possible.
Important notes about DNS-only load balancers:
- DNS-only load balancers support only public origins
- DNS-only load balancers do not proxy traffic — and — as such, are not involved in the connections to origin
- DNS-only load balancers only respond to a DNS request with an IP address or set of IP addresses
Spectrum load balancing
Cloudflare also offers another ingress method via the Spectrum product.
Where the layer 7 stack only supported HTTP(S) and WebSockets, Spectrum offers support for any TCP- or UDP-based protocol. A Cloudflare Load Balancer using Spectrum as an ingress for traffic operates at layer 4, where both TCP and UDP protocols exist. Any service that utilizes TCP or UDP for transport can leverage Spectrum with a Cloudflare Load Balancer including SSH, FTP, NTP, SMTP, and more.
Given the breadth of services and protocols this represents, the treatment provided is more generalized than what is offered with the layer 7 HTTP(S) stack. For example, Cloudflare Spectrum supports features such as TLS/SSL offloading, DDoS protection, IP Access lists, Argo Smart Routing, and session persistence with our layer 4 load balancers.
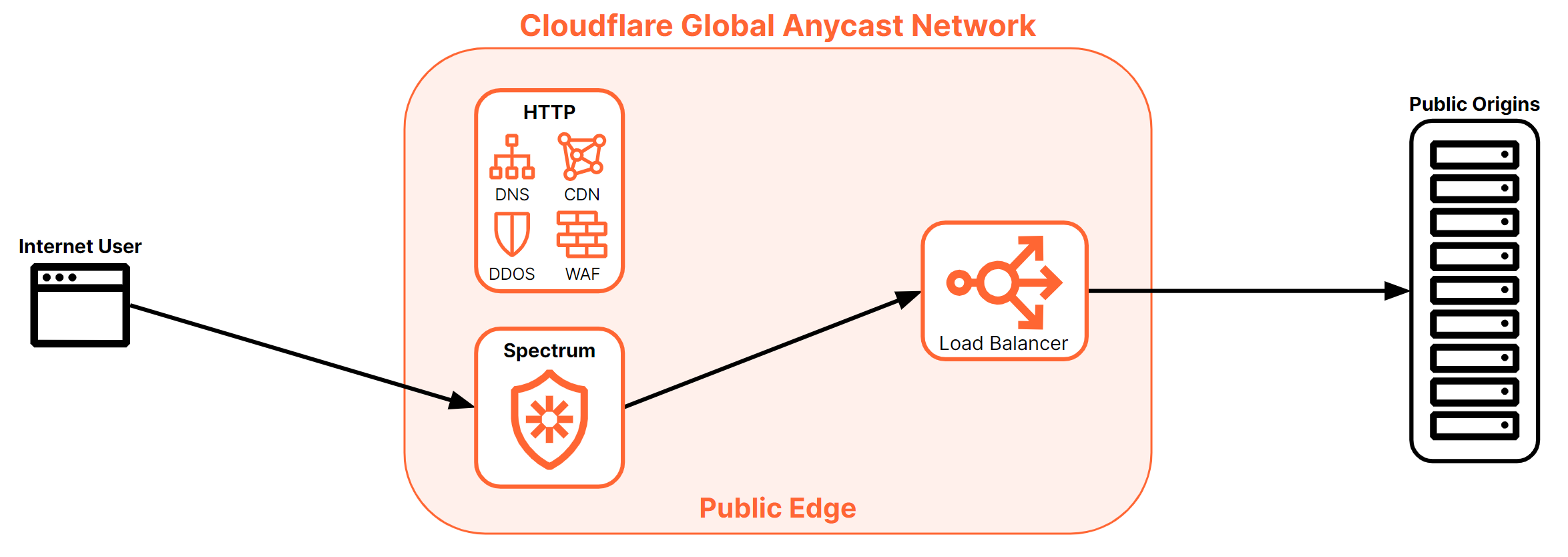
Cloudflare layer 4 Spectrum load balancers are publicly accessible. Access to these load balancing resources can be managed using a Spectrum configuration called IP Access Rules, which can be defined as part of a WAF configuration, but are limited to rules created with the “allow” or “block” action for specific IP addresses, subnets, countries, or Border Gateway Protocol (BGP) Autonomous System Numbers (ASNs).
In addition to being public, Spectrum load balancers are always proxied. The proxy setting shown earlier (Figures 24 and 25) will be ignored when Spectrum is configured as the ingress path for the load balancer. All traffic destined for Spectrum-based load balancers will always pass through the Cloudflare edge.
Important notes about Spectrum load balancers:
- Spectrum load balancers support only public origins
- Spectrum load balancers are initially created as Layer 7 HTTP(S) load balancers. A Spectrum application is then created with a Load Balancer origin type, and the load balancer that has already been created is selected.
- Spectrum load balancers are always proxied, regardless of the proxy setting on the load balancer configuration
- There is no ability to change the ingress port from the Internet via Spectrum to the origin; i.e., if the traffic comes in on port 22 to Spectrum, it will be steered to port 22 on the origin
- Spectrum load balancers only support session affinity using the hash origin steering method
- Spectrum load balancers do not support Custom Rules
Deployment models at-a-glance
| Load Balancer Model | Public | Proxied | OSI Layer | Traffic Type |
|---|---|---|---|---|
| Layer 7 HTTP(S) | X | X | 7 | HTTP(S) |
| DNS-Only | X | 7 (DNS) | IP-Based | |
| Spectrum | X | X | 4 | TCP/UDP |
Load balancer details
Hostname
The hostname setting is the publicly-reachable hostname for the load balancer. The hostname must be created within the zone for which the load balancer is being created.
Proxy status
The proxy setting determines whether Cloudflare will proxy traffic for the load balancer or simply provide a DNS reply with the origins for the client to directly connect. This is covered in detail in the Deployment models section.
Session affinity
Session affinity, also known as session persistence or sticky sessions, keeps a client connected to the same origin for all subsequent requests after the first request or connection. This can be an important feature for applications that don’t share session data — the context of a user’s interaction with a web application — between origins. For example, if a new origin were selected in the middle of a client session and information about the session (e.g. the contents of a user’s shopping cart) were lost, the user experience for that application would be poor.
Cloudflare offers three methods for enabling session affinity:
- By Cloudflare cookie only (cookie): On the first request to a proxied load balancer, a cookie is generated, encoding information of which origin the request will be forwarded to. Subsequent requests (by the same client to the same load balancer) will be sent to the origin server that the cookie encodes for a) the duration of the cookie and b) as long as the origin server remains healthy. If the cookie has expired or the origin server is unhealthy, a new origin will be calculated and used.
- By Cloudflare cookie and Client IP fallback (ip_cookie): This behaves similar to the cookie method above, except that the cookie is generated based on the client IP address. In this case, requests from the same IP address always get steered towards the same origin for a) the duration of the cookie and b) as long as the origin server remains healthy. If the cookie has expired or the origin server is unhealthy, a new origin will be calculated and used.
- By HTTP header (header): On the first request to a proxied load balancer, a session key is generated based on the configured HTTP headers. Subsequent requests to the load balancer with the same headers will be sent to the same origin server, for a) the duration of the session or b) as long as the origin server remains healthy. If the session has been idle for the duration of session affinity time-to-live (TTL) seconds or the origin server is unhealthy, then a new origin server will be calculated and used.
These three session affinity options only apply to layer 7 HTTP(S) load balancers. Session affinity requires a TTL, which determines how long the load balancer will route subsequent requests to a specific origin. The default TTL is 82,800 seconds (23 hours), but it can be set for anywhere from 1,800 seconds (30 minutes) to 604,800 seconds (seven days).
For cookie-based session affinity, the expiration timer is never reset, meaning that the timer is counting down from the start of the session — regardless of the session being idle or active. HTTP header-based session affinity will reset the expiration timer every time there is activity in the session.
Origin draining
Origin draining is a subfeature of session affinity. It allows for sessions to gracefully expire from an origin while not allowing new sessions to be created on that same origin. Origin draining is useful for maintenance, as it does not require administrators to arbitrarily or abruptly cut off user sessions in order to remove all active sessions from an origin.
The origin drain TTL is the amount of time that origins will be allowed to maintain active sessions before being forcefully terminated. Once the origin drain TTL is set, origin draining is started by disabling an origin (or multiple origins) within an origin pool. As seen in the below image, administrators can monitor the time remaining on an origin drawing operation from the load balancer UI.
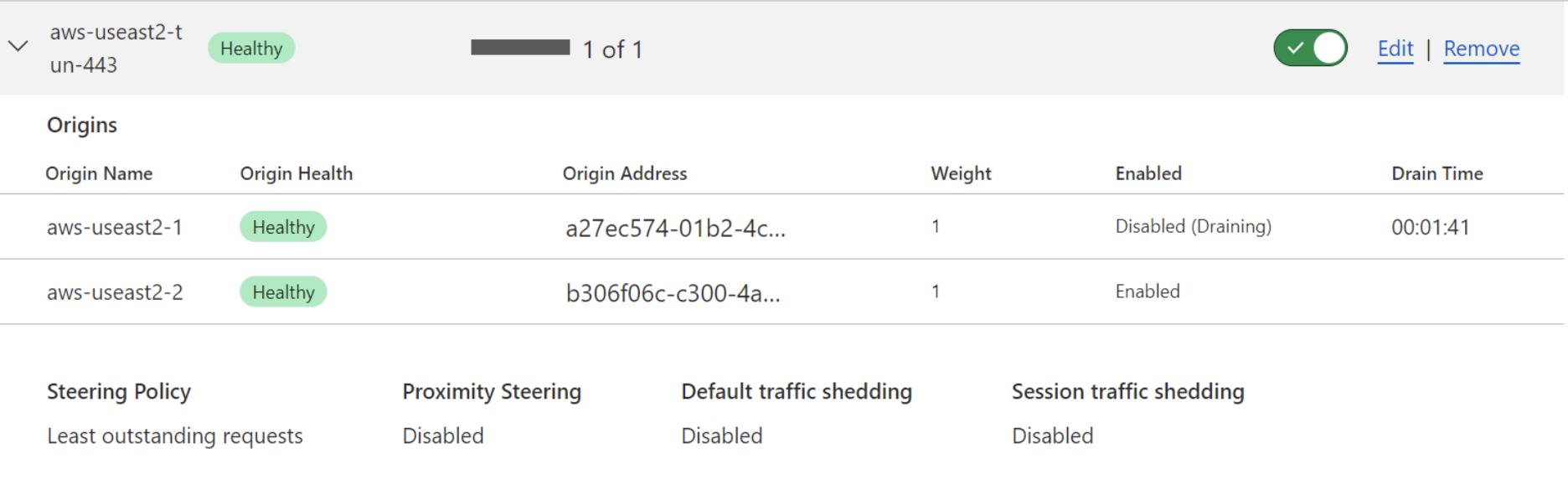
Origin draining is only applicable for session affinity because without session affinity, subsequent requests or connections are not guaranteed to be steered to the same origin. Thus, disabling an origin does not have an impact on user experience.
Zero-downtime failover
Zero-downtime failover automatically sends traffic to origin servers within an origin pool during transient network issues. Zero-downtime failover will trigger a single retry only if there is another healthy origin in the origin pool and a 521, 522, or 523 error code is occuring. No other error codes will trigger a zero-downtime failover operation. These response codes are not returned from the origin, but from requests made by upstream Cloudflare services to an organization’s origins.
Zero-downtime failover has three modes of operation:
- None (Off): No failover will take place and users may receive error messages or a poor user experience.
- Temporary: Traffic will be sent to other origin(s) until the original origin is available again
- Sticky: The session affinity cookie is updated and subsequent requests are sent to the new origin moving forward as needed. This is not supported when session affinity is using HTTP header mode.
Adaptive routing - failover across pools
Adaptive routing - failover across pools extends the functionality of zero-downtime failover by allowing failover to extend to origins in another origin pool, rather than only failing over to an origin in the same pool.
Origin pools
Origin pools are configured in a priority order and can be rearranged as needed. This priority order is only considered when using Off - Failover traffic steering; otherwise, origin pools will be selected based on the criteria outlined in the Steering methods section.
The origin pools assigned to a load balancer represent the entire collection of origin servers that could possibly handle requests or connections through the load balancer. An origin pool typically contains origins that all have the same capabilities and are in the data center or geographic region. All origins in a pool should be capable of handling any request directed to an origin pool. For more information about origin pools, please refer to the Origin pools section.
Fallback pools
A fallback pool is the pool of last resort. When all origin pools are unavailable or unhealthy, the fallback pool will be used for all requests and connections. While health monitor data is always considered when steering traffic within a load balancer, a fallback pool does not rely on this data and is not subject to it.
Health monitors
Health monitors are usually configured as part of the origin pool. Health monitors can be added, changed, or deleted as part of the load balancer configuration. Please see the Health monitors section for more information.
Traffic steering
Traffic steering is the method of steering between origin pools. For help understanding which traffic steering method to select, please see the Steering types and methods section.
Custom rules
Custom rules allow users to perform actions on requests or connections before the load balancer finishes its decision process. Custom rules are configured with expressions that match certain fields in requests or connections. Once the expression is created to match traffic, an action is assigned for when a request or connection matches the expression.
Custom rules are a powerful tool for customizing the steering and output from a load balancer before the request or connection is sent to the origin. For example, the HTTP method (e.g. GET, PUT, POST) could be matched to ensure that POST messages are sent to a specific origin pool dedicated to handling receiving information from clients.
Alternatively, that session affinity TTL could be reset based on a request going to a specific URL path to ensure that the client has enough time to complete the transaction.
It is not possible to document all of the potential combinations of fields that can be matched and actions that can be taken. However, the following resources describe all of the fields and actions that are currently available:
If the default behavior of a load balancer is not covered in the documents listed above, it is likely that a custom rule can help meet unique use case requirements.
Protecting and securing load balancers
Inherent security
All Cloudflare Load Balancer deployment models come with inherent protections. The following section briefly highlights the default security Cloudflare provides, as well as optional protections that can be added in front of Cloudflare Load Balancers:
- Proxied HTTP layer 7 load balancer (Public)
- DDoS protection to protect against attacks
- WAF with Cloudflare managed ruleset and OWASP ruleset to block known vulnerabilities and exploits
- DNS-only load balancer (Public)
- DNS DDoS protection to ensure a DNS-only load balancer is always available
- Spectrum layer 4 load balancer (Public)
- DDoS Protection to protect against layer 4 attacks
Additional options
Cloudflare offers additional security layers that can be used in conjunction with load balancing to protect any services — including websites, APIs, HTTP(S)-based services, and more:
- Proxied HTTP layer 7 load balancer (Public)
- Bot management to control which bots can access resources
- WAF for creating custom rules for web applications
- Page Shield for monitoring script usage on web applications
- API Shield for protecting APIs
- DNS-only load balancer (Public)
- DNSSEC to ensure authenticity of DNS records
- Spectrum layer 4 load balancer (Public)
- IP Access Rules for controlling access to public layer 4 load balancers
Summary
The Cloudflare global Anycast network is a powerful platform for load balancing. A load balancing configuration in Cloudflare is accessible in over 310 cities across the world and has virtually unlimited capacity and bandwidth.
These load balancers operate within approximately 50ms of about 95% of the Internet-connected population, including origin servers that allow Cloudflare Load Balancers to perform both GTM and LTM load balancing. Cloudflare now combines these two distinct load balancing concepts into a single load balancer. This helps enable organizations to steer traffic to geographically-relevant data centers, then select the proper origin to handle the request.
With Cloudflare Tunnel, origins can be located within private networks and still be utilized by Cloudflare Load Balancers. Cloudflare offers public layer 7 load balancers — that supports both HTTP(S) and WebSockets, as well as public layer 4 load balancers that can steer any TCP or UDP traffic. This means that Cloudflare can offer load balancing services to all organizations and users, no matter their location, use cases, or existing configurations.